新火种
2023-11-01
新火种
2023-11-01 



中国学者拿下“半壁江山”!ICCV2021开幕,SwinTransformer摘得马尔奖
:
作者 | 蒋宝尚、琰琰
刚刚,计算机视觉三大顶会之一的 ICCV 2021于线上拉开序幕。
今年 ICCV收到有效投稿6236篇,1617篇被收录,接收率为25.9%,其中210篇论文为oral。就总数来看,相比ICCV 2019,接收数量增加了1800篇。
在这些论文中,中国学者几乎拿下了“半壁江山”,占比45.7%,超过第二名美国近一倍,是第三名英国的近13倍。
而在优秀论文评选中,中国科学技术大学刘泽、西安交通大学的林宇桐、微软的曹越合作的Swin Transformer拿下了马尔奖(最佳论文)。

此外,在杰出评审名单中,中国学者至少上榜50位,占比23%。
据悉,为了选出这一千六百多篇论文,共有233位领域主席(AC)、4216位评审为之付出努力。为了保障论文质量,每篇论文至少接受3位评审的审阅,而能否拒稿是由“一对儿”领域主席决定的。
以下是马尔奖、最佳学生论文的贡献:
最佳学生论文:“Pixel-Perfect Structure-From-Motion With Featuremetric Refinement”
贡献:提供了一种用于优化 SFM 建图精度的方案,能够大幅度提升建图精度与后续的视觉定位精度。
马尔奖:“Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows”
贡献:提出了名为Swin Transformer的新型视觉Transformer,它可以用作计算机视觉的通用骨干网络。
获奖论文之马尔奖
论文题目:Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows”
论文地址:https://arxiv.org/pdf/2103.14030.pdf
对于这篇文章的贡献,作者曹越介绍:
1.之前的ViT(Vision Transformer)中,由于self-attention是全局计算的,所以在图像分辨率较大时不太经济。由于locality一直是视觉建模里非常有效的一种inductive bias,所以我们将图片切分为无重合的window,然后在local window内部进行self-attention计算。为了让window之间有信息交换,我们在相邻两层使用不同的window划分(shifted window)。
2. 图片中的物体大小不一,而ViT中使用固定的scale进行建模或许对下游任务例如目标检测而言不是最优的。在这里我们还是follow传统CNN构建了一个层次化的transformer模型,从4x逐渐降分辨率到32x,这样也可以在任意框架中无缝替代之前的CNN模型。
Swin Transformer的这些特性使其可直接用于多种视觉任务,包括图像分类(ImageNet-1K中取得86.4 top-1 acc)、目标检测(COCO test-dev 58.7 box AP和51.1 mask AP)和语义分割(ADE20K 53.5 val mIoU,并在其公开benchmark中排名第一),其中在COCO目标检测与ADE20K语义分割中均为state-of-the-art。
获奖论文之最佳学生论文
论文标题:Pixel-Perfect Structure-From-Motion With Featuremetric Refinement
论文地址:https://arxiv.org/pdf/2108.08291.pdf

我们在几何估计之前调整初始关键点位置,随后作为后处理完善点和摄像机的位置。因为优化了基于神经网络预测的密集特征的测量误差,所以对噪声检测和外观变化是稳健的。这也显著提高了各种关键点检测器算法、具有挑战性的观察条件和现成深度特征的相机pose和场景几何体的准确性。该系统可以轻松扩展到大型图像集,实现大规模像素完美密集定位。
目前,代码已经开源:https://github.com/cvg/pixel-perfect-sfm
获奖论文之荣誉提名论文
1.论文题目:“Mip-NeRF: A Multiscale Representation for Anti-Aliasing Neural Radiance Fields”
论文地址:https://arxiv.org/pdf/2103.13415.pdf

摘要:对于NeRF来说,通过每个像素渲染多条光线进行采样是不切实际的,因为每条光线的渲染都需要查询多层感知器上百次。在这项研究中,我们提出了一种名为“mip-NeRF”的扩展解决方案,它以连续值的比例表示场景。通过高效渲染消除反锯齿圆锥锥体( anti-aliased conical frustums)取代光线,mip NeRF减少了混叠瑕疵,显著提高了NeRF表示精细细节的能力,在速度上比NeRF 快了7%,大小仅为NeRF的一半。
此外,与NeRF相比,mip NeRF在数据集上降低了17%的平均错误率,在具有挑战性的多尺度变体上降低了60%的平均错误率。Mip NeRF还能够在多尺度数据集上与强力超采样NeRF的精度相匹配,同时速度快22倍。
2.论文题目:OpenGAN: Open-Set Recognition via Open Data Generation
论文地址:https://arxiv.org/pdf/2104.02939.pdf

摘要:现实世界的机器学习系统需要分析与训练数据不同的测试数据。在K-way分类中,这通常被表述为开集(open-set)识别,以区分 K闭集(closed-set)数据集。关于开集识别通常有两种处理方案:1)使用一些离群数据作为开集,对开-闭二进制判别器分别进行判别学习(discriminatively learning an open-vs-closed binary discriminator by exploiting some outlier data as the open-set,);2)使用GAN,对闭集数据分布进行无监督学习,并使用其判别器作为开集似然函数。
然而,由于过度拟合训练离散值,前者不能很好地推广到不同的开放测试数据,而后者由于GANs训练不稳定,效果也不好。基于以上问题,我们提出了一种新的解决方案OpenGAN,它解决了现有技术存在的局限,首先,在一些真实的离群数据上经过挑选的GAN鉴别器已经达到最先进的水平。第二,可用敌对合成的“假”数据来扩充可用的真实开集示例集。第三,也是最重要的一点,它可以在 K-way网络计算的特征上构建鉴别器。大量实验表明,OpenGAN的性能明显优于以前的开集方法。
值得一提的是,该论文的第一作者Shu Kong也是一位华人学者。
3.论文标题:Viewing Graph Solvability via Cycle Consistency
论文链接:https://openaccess.thecvf.com/content/ICCV2021/papers/Arrigoni_Viewing_Graph_Solvability_via_Cycle_Consistency_ICCV_2021_paper.pdf

摘要:在SfM(Structure from motion)中,视图的顶点代表相机,边代表矩阵。我们在论文中设计了一组算法,能够让解算视图,即确定唯一的投影相机(projective cameras)减少未知数的数量.
当前,已有的理论完全描述所有视图的可解性,或者计算有难度,毕竟其涉及包含大量未知数的多项式方程组。本文的主要思想是:通过利用循环一致性(cycle consistency)。具体而言:
1.完成对所有先前未定最小图(undecided minimal graphs)的分类,所谓最小是指:最多9个节点。
2.将实际的可解性测试扩展到最多90个节点的最小图
3.明确回答了一个公开的研究问题,证明了有限可解性与可解性不等价。
4.论文题目:Common Objects in 3D: Large-Scale Learning and Evaluation of Real-Life 3D Category Reconstruction
论文链接:https://arxiv.org/pdf/2109.00512.pdf

摘要:在过去,识别3D对象类别需要在合成数据集上进行训练和评估,这是因为真实的3D注释类别的中心数据不可用。为了促进相关研究的推进,我们收集了与现有合成数据相似的真实数据。在这项工作中,我们最主要贡献是创建了 3D公共对象数据集(Common Objects in 3D),它全部来自真实世界,包含了对象类别的多视图图像,并使用摄影机姿势和地面真实3D点云进行了注释。
具体而言,该数据集包含近19000个视频的150万帧,这些视频捕获了50个MS-COCO类别的对象,因此,就类别和对象的数量而言,该数据集远远大于现有数据集。利用这个新数据集,我们对几种新的视图合成和以类别为中心的三维重建方法进行了一次大规模的“野外”评估。最后,我们还提出了一种新的神经渲染方法NerFormer,实验证明,它利用强大的转换器在给定少量视图的情况下也能够重建对象。
PAMI-TC 奖
ICCV 2021 组委会还颁布了过往杰出研究类奖项 PAMI-TC 奖,包括四个奖项:Azriel Rosenfeld终身成就奖、杰出学者奖,Everingham 奖和ICCV Helmholtz 奖。

其中,Azriel Rosenfeld终身成就奖颁发给了加州大学Berkeley 分校电气工程与计算机科学系教授 RUzena Bajcsy,以表彰其长期以来在计算机视觉领域所作出的重大贡献。

Bajcsy 博士是美国国家工程院 (1997) 和美国国家医学科学院 (1995) 的成员,也是计算机协会 (ACM) 和美国人工智能协会 (AAAI) 成员。曾获得了ACM/AAAI 艾伦纽厄尔奖,本杰明富兰克林计算机和认知科学奖、 IEEE 机器人和自动化奖。2002 年,她还被《探索》杂志评为 50 位最重要的女性之一。主要从事机器人研究,包括计算机视觉、触觉感知以及系统识别。
个人主页:https://people.eecs.berkeley.edu/~bajcsy/?_ga=2.102438914.2095164583.1634049418-1623552618.1634049418)
PAMI杰出学者奖项颁发给了加州理工学院教授Pietro Perona和法国国家信息与自动化研究所(INRIA)研究员Cordelia Schmid。

Everingham奖颁发给了KITTI 视觉基准团队和Detectron对象检测和分割软件团队,其成员分别包括:
Andreas Geiger ,philip Lenz,Christoph Stiller,Raquel Urtasun and other contributors
RossGirshick,Yuxin Wu,llijiaRadosavovic,Alexander Kirllov ,GeorgiaGkioxari,Francisco Massa ,Wan-Yen Lo,Piotr Dollar,Kaiming He
ICCV Helmholtz 奖在奖励对计算机视觉领域做出重要贡献的工作,颁发对象是十年前对计算机视觉领域产生重大影响的论文。今年的 Helmholtz 奖颁给了三篇论文:
ORB:An efficient alternative to SIFT or SURF
HMDB:A large video datebase for human motion recognition
DTAM;Dense tracking and mapping in real-time
ICCV 2021投稿趋势一览
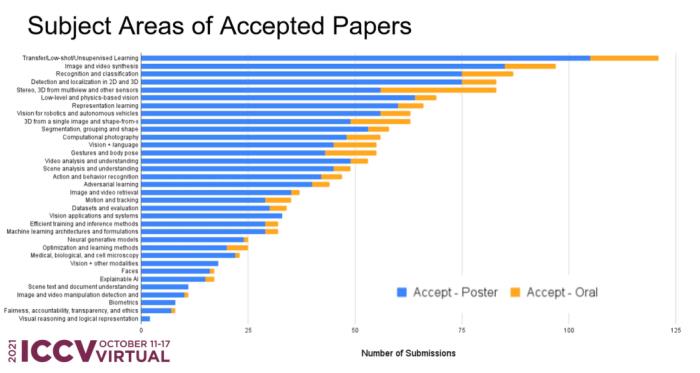
就接收论文分布领域而言,迁移\小样本\无监督学习、图像视频合成、识别和分类位列前三甲,接收数量都超过了80篇。而新出现的领域,例如可解释AI、公平、负责、透明和道德等研究主题的论文,其接收数量一直“上涨”。
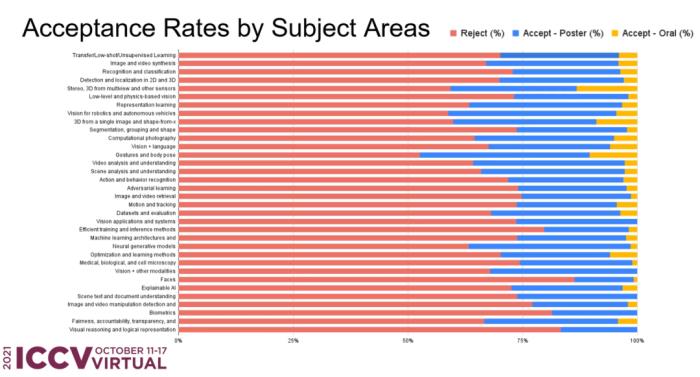
抛却“论文的绝对数量”,通过比例观察,可以明显看出:手和身的姿态、机器和自动驾驶视觉、视频分析和理解、伦理等领域接受率相差不大;视觉推理和逻辑表达领域接受率最低。
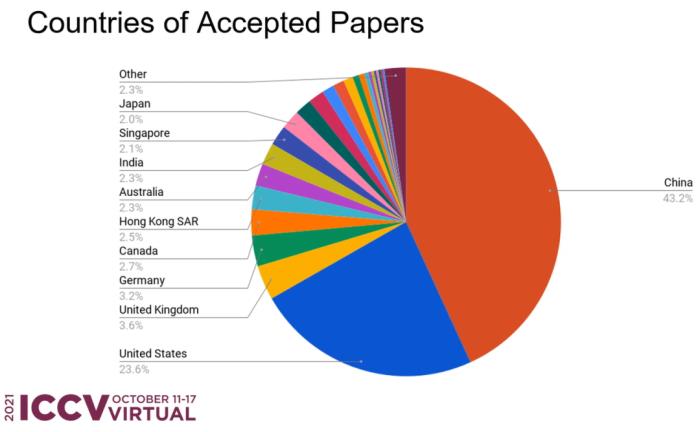
在国家层面,中国论文数量几乎占据了“半壁江山”(43.2%+2.5%=45.7%),超过美国(23.6%)接近一半,超过第三名英国(3.6%)12倍.....

中国力量的另一个体现是杰出评审的数量,本届ICCV总共评出了220位,粗略估计华人学者52位。
另外,据大会主席james clark介绍,本届ICCV会维持三天,共有82个workshops,12个tutorial进行展示,研究主题涵盖各个领域。
 Clark特别点出了两场特邀报告和三场讨论。其中,麻省理工学院的Judith Donath和来自工业界的Caroline Sinders将会呈现计算机视觉和AI在社会中的应用,以及技术对社会的影响。
Clark特别点出了两场特邀报告和三场讨论。其中,麻省理工学院的Judith Donath和来自工业界的Caroline Sinders将会呈现计算机视觉和AI在社会中的应用,以及技术对社会的影响。


另外三场专家论坛将讨论研究热点,分别是:深度学习和传统技法在计算机视觉中的比较;Deepfake和数据安全;计算机视觉和工业应用。
相关链接:
https://www.zhihu.com/question/437495132/answer/1800881612
雷锋网雷锋网

相关推荐


- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。