

 新火种
2023-10-29
新火种
2023-10-29 


当AI学会高数:解题、出题、评分样样都行
 “高等数学里程碑式的研究”,114页论文让AI文理双修,也许不久后机器出的高数试卷就会走进高校课堂,这下可以说“高数题不是人出的了”。编译 | 王晔
“高等数学里程碑式的研究”,114页论文让AI文理双修,也许不久后机器出的高数试卷就会走进高校课堂,这下可以说“高数题不是人出的了”。编译 | 王晔编辑 | 青暮
人工智能虽然给我们带来了诸多便利,但也不免受到了各种质疑。在互联网领域表现良好的人工智能,在数学领域的很多表现却被认为是“出乎意料地糟糕”。基于Transformers的语言模型在零样本和少样本等各种自然语言处理(NLP)任务中取得了令人难以置信的成功。但是,“这些模型在解决数学问题方面基本上是失败的。”中国科学院院士、普林斯顿大学数学系和应用数学研究所教授、北京大数据研究院院长鄂维南曾表示,神经网络可以帮助我们有效地表示或逼近高维函数,深度神经网络是一个有效的工具,它带来的影响是巨大的。以上思路更多还是基于深度学习在特征提取上的优势,然而,在更简单或“低维”函数的、符号逻辑层面的推理中,神经网络真的毫无希望了吗?回归人工智能发展萌芽阶段,符号语言的思想为数理逻辑的产生和发展奠定了基础。当时人们试图将对一切事物的理解与认知化为符号语言以及符号间的推理,以此思路构建的模型以符号为基底,但或许可以尝试另一种思路,就是先用神经网络挖掘符号的特征。在最新的一项研究中,用神经网络的方法精确求解低维的数学问题被证实非常有效。值得一提的是,该项研究中还用到了OpenAI Codex。作为一种生成软件源代码的深度学习模型,Codex 可以理解十几种编程语言,通过 API 提供的 Codex 模型在 Python 编程中也具有极强的能力,它在执行编程任务时能够考虑到上下文信息,包括转译、解释代码和重构代码。该研究还被其研究团队称为“第一项可以规模化自动解决、评分和生成大学水平数学课程问题”的工作,打破了人们普遍认为的神经网络不能解决高等数学问题的观点。“这些所谓不成功的研究只使用了基于文本的预训练,而既对文本进行预训练又对代码进行微调的神经网络,可以通过程序合成成功解决大学水平的数学问题。” 论文地址:https://arxiv.org/pdf/2112.15594v1.pdf
论文地址:https://arxiv.org/pdf/2112.15594v1.pdf秒速解高数机器学习模型真的可以解决单变量函数的图形绕轴旋转产生的体积、洛伦兹吸引子及其投影、奇异值分解(SVD)方法的几何图形等问题吗?这项研究展示了机器学习在这方面的强大能力。机器学习模型可以大规模很好地解决麻省理工学院包括单变量微积分、多变量微积分、微分方程、概率和统计学导论在内的数学课程问题。不仅如此,该团队的研究证实它还可以解决MATH数据集的问题,“MATH数据集是衡量模型的数学问题解决能力的基准,该数据集的主要来源是高中数学竞赛,如AMC 10、AMC 12和AIME等。目前为止,最先进的 Transformers ,如GPT-3,只对文本进行了预训练,GPT-3取得的最好成绩总体准确率为6.9%,并且在所有题目上的准确率都低于8.8%”。
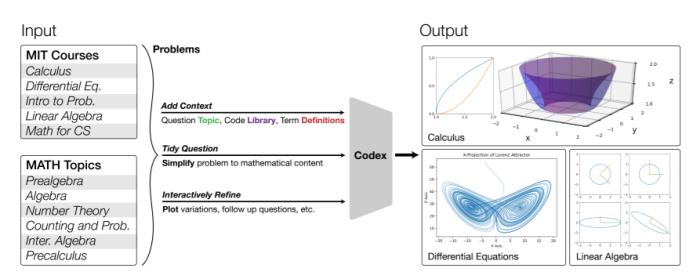 图1:图中展示了模型可求解的高数问题。例如,在微积分18.01-02中,求由两个二维图形限定的二维区域围绕z轴旋转一周得到的体积(右上);在微分方程18.03中,求解洛伦兹奇异吸引子(右下);在线性代数18.06中,画出奇异值分解(SVD)的几何图形(右下)。“以前使用Transformers解决数学课程问题的工作之所以失败,是由于像GPT-3一样的Transformers,只在文本上进行了预训练。”研究团队认为此前工作使用验证或预测表达式树的联合训练输出,虽然在解决小学水平的数学问题(如MAWPS和Math23k)时,准确率超过80%。然而,这种方法的有效性并未在高中、数学奥林匹克或大学水平的数学课程中得到扩展。后来有人通过与图神经网络(GNN)配对预测算术表达式树(expression trees),并在文本上预训练Transformers,来求解大学水平问题,且准确率高达95%。但是这个结果仅限于数字答案,并局限于特定课程,不容易扩展到其他课程。而本文的这项研究证明,把问题变成编程任务进行程序合成,是大规模解决数学和STEM课程的关键。“对文本进行预训练并对代码进行微调的 Transformers ,可以在MATH数据集和大学水平的数学课程上取得完美表现。”如图1所示,研究团队将麻省理工学院课程中的数学问题和MATH数据集进行处理,并将其作为输入传给OpenAI Codex Transformers,使要解决的问题转化为编程任务,然后执行自动生成程序。问题不同,运行程序的输出形式也不同,包含数字输出形式,甚至可以通过程序合成从文本中产生图片输出形式。该团队用prompt生成法(prompt generation methods ),使Transformers能够为每个随机抽到的问题生成带图的解题程序和方案。相比之下,这项工作可以输出包括图表在内的多种模式,并且不需要专门的训练就可以扩展到其他数学课程。他们还对原始问题和转化后的问题进行了对比量化,并通过调查评估了生成问题的质量和难度。
图1:图中展示了模型可求解的高数问题。例如,在微积分18.01-02中,求由两个二维图形限定的二维区域围绕z轴旋转一周得到的体积(右上);在微分方程18.03中,求解洛伦兹奇异吸引子(右下);在线性代数18.06中,画出奇异值分解(SVD)的几何图形(右下)。“以前使用Transformers解决数学课程问题的工作之所以失败,是由于像GPT-3一样的Transformers,只在文本上进行了预训练。”研究团队认为此前工作使用验证或预测表达式树的联合训练输出,虽然在解决小学水平的数学问题(如MAWPS和Math23k)时,准确率超过80%。然而,这种方法的有效性并未在高中、数学奥林匹克或大学水平的数学课程中得到扩展。后来有人通过与图神经网络(GNN)配对预测算术表达式树(expression trees),并在文本上预训练Transformers,来求解大学水平问题,且准确率高达95%。但是这个结果仅限于数字答案,并局限于特定课程,不容易扩展到其他课程。而本文的这项研究证明,把问题变成编程任务进行程序合成,是大规模解决数学和STEM课程的关键。“对文本进行预训练并对代码进行微调的 Transformers ,可以在MATH数据集和大学水平的数学课程上取得完美表现。”如图1所示,研究团队将麻省理工学院课程中的数学问题和MATH数据集进行处理,并将其作为输入传给OpenAI Codex Transformers,使要解决的问题转化为编程任务,然后执行自动生成程序。问题不同,运行程序的输出形式也不同,包含数字输出形式,甚至可以通过程序合成从文本中产生图片输出形式。该团队用prompt生成法(prompt generation methods ),使Transformers能够为每个随机抽到的问题生成带图的解题程序和方案。相比之下,这项工作可以输出包括图表在内的多种模式,并且不需要专门的训练就可以扩展到其他数学课程。他们还对原始问题和转化后的问题进行了对比量化,并通过调查评估了生成问题的质量和难度。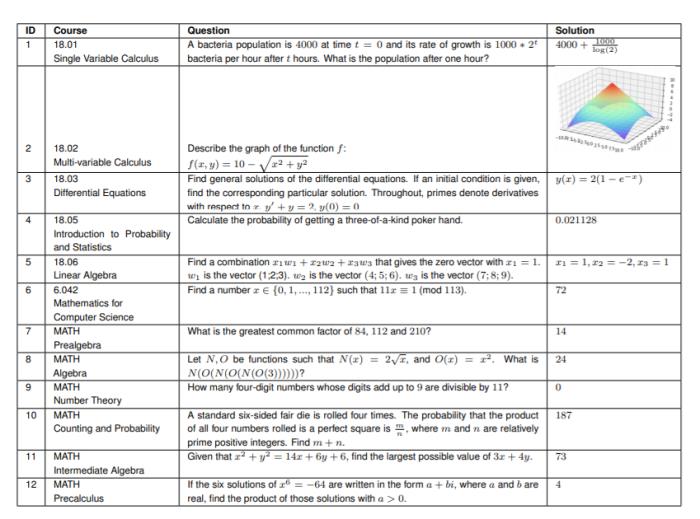 表1:针对六门课程(18.01, 18.02, 18.03, 18.05, 18.06, 6.042)和MATH数据集的六个主题(预-代数,代数,中级代数,计数和概率,预-微积分,数论)中的一些问题的解决方案。解决方案可包含数字答案、方程式和图表等。在上表所列的麻省理工学院的数学课程中,使用该方法可以很好地自动解决、评分和生成问题,并且所有这些都是实时的,每个问题处理时间竟不到一秒。
表1:针对六门课程(18.01, 18.02, 18.03, 18.05, 18.06, 6.042)和MATH数据集的六个主题(预-代数,代数,中级代数,计数和概率,预-微积分,数论)中的一些问题的解决方案。解决方案可包含数字答案、方程式和图表等。在上表所列的麻省理工学院的数学课程中,使用该方法可以很好地自动解决、评分和生成问题,并且所有这些都是实时的,每个问题处理时间竟不到一秒。关键研究实验题目来自麻省理工学院六门课程中随机抽取的25个问题,和MATH数据集的六个主题中各随机抽取5个问题。并且,为了说明他们的研究结果不是过度拟合训练数据,他们还用了在训练期间网上查不到的新的应用线性代数课程COMS3251来进行验证。技术代替人进行解题时,并不是使用技术对问题进行重大修改,而是努力提取问题的本质,因此,该团队使用Codex对问题进行了整理。
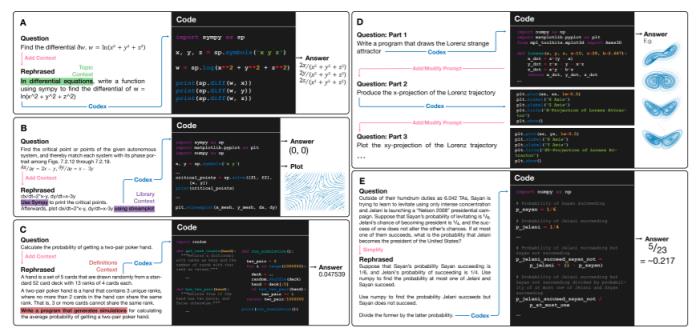 图2:问题的扩充和重组得到正确的Codex输出。上图中,显示了使用Codex将课程问题转化为编程任务并运行程序以解决数学问题的方法。每个面板的左半部分显示了原始问题和通过添加问题背景、互动或简化后而重新表述的问题。添加问题背景是非常有必要的,对学生和程序来说,解题域是选择合适的解题方法的必要信息。例如,如果没有问题背景,一个关于网络的问题,可能是关于神经网络的问题也可能是关于通信网络的问题。面板A中对微积分方程问题的主题背景进行了补充,将其重新表述为一个编程任务的问题。补充背景包括澄清含糊不清的定义和运算符,或有一个以上标准用法的符号,说明学生通过学习课程就会知道的隐含假设,包括课程的主题或课题,指出学生从与问题相关的讲座或教科书章节中学到的适当方法。面板B中使用了Python库、sympy库和streamplot库的背景,用于解题和绘制可视化图。如果程序的语法与Python版本不兼容,或者数据类型有错误,又或者没有使用库,合成程序在执行中可能无法得到正确的答案。面板C中显示了概率和统计学中的一个例子,原始问题被转化为生成模拟的概率编程任务。在做题时学生可以从课程的主题和涵盖的材料中得到一些信息,在这个过程中,要通过了解问题背景,确定所需要的是什么类型的答案,对处理形式有一个合理预期。例如,概率或组合学中的许多问题可能需要用阶乘、组合函数或指数来回答。因此在实验中也必须要提供背景,以便用正确的方法来处理问题。面板D考虑到NLP模型在处理长而复杂的文本方面有困难,因此将较长的问题分解成了具体的编程任务,并删除了多余的信息。通过互动产生了多个图,交互式使用Codex可以使可视化图很好地被绘制出来,并且可以发现缺失的功能或需要的库。面板E来自《计算机科学数学》,对问题进行了简化处理,简化包括删除多余的信息,将长的句子结构分解成较小的组成部分,并将提示转换为编程格式。概括提炼出简洁的提示和一系列较短的问题,可以提高Codex性能。除此之外,他们还考虑了原始课程问题转化为Codex 提示的三种情况:原样提示。原始问题和Codex 提示是相同的;自动提示转换。原始问题和Codex提示不同,Codex提示是由其本身自动生成的;手动提示转换。原始问题和Codex提示不同,Codex提示是由人生成的。当把问题转化为Codex提示时,又出现了一个关键性的问题:原始问题与之后产生正确答案的提示在语义上的接近程度如何?
图2:问题的扩充和重组得到正确的Codex输出。上图中,显示了使用Codex将课程问题转化为编程任务并运行程序以解决数学问题的方法。每个面板的左半部分显示了原始问题和通过添加问题背景、互动或简化后而重新表述的问题。添加问题背景是非常有必要的,对学生和程序来说,解题域是选择合适的解题方法的必要信息。例如,如果没有问题背景,一个关于网络的问题,可能是关于神经网络的问题也可能是关于通信网络的问题。面板A中对微积分方程问题的主题背景进行了补充,将其重新表述为一个编程任务的问题。补充背景包括澄清含糊不清的定义和运算符,或有一个以上标准用法的符号,说明学生通过学习课程就会知道的隐含假设,包括课程的主题或课题,指出学生从与问题相关的讲座或教科书章节中学到的适当方法。面板B中使用了Python库、sympy库和streamplot库的背景,用于解题和绘制可视化图。如果程序的语法与Python版本不兼容,或者数据类型有错误,又或者没有使用库,合成程序在执行中可能无法得到正确的答案。面板C中显示了概率和统计学中的一个例子,原始问题被转化为生成模拟的概率编程任务。在做题时学生可以从课程的主题和涵盖的材料中得到一些信息,在这个过程中,要通过了解问题背景,确定所需要的是什么类型的答案,对处理形式有一个合理预期。例如,概率或组合学中的许多问题可能需要用阶乘、组合函数或指数来回答。因此在实验中也必须要提供背景,以便用正确的方法来处理问题。面板D考虑到NLP模型在处理长而复杂的文本方面有困难,因此将较长的问题分解成了具体的编程任务,并删除了多余的信息。通过互动产生了多个图,交互式使用Codex可以使可视化图很好地被绘制出来,并且可以发现缺失的功能或需要的库。面板E来自《计算机科学数学》,对问题进行了简化处理,简化包括删除多余的信息,将长的句子结构分解成较小的组成部分,并将提示转换为编程格式。概括提炼出简洁的提示和一系列较短的问题,可以提高Codex性能。除此之外,他们还考虑了原始课程问题转化为Codex 提示的三种情况:原样提示。原始问题和Codex 提示是相同的;自动提示转换。原始问题和Codex提示不同,Codex提示是由其本身自动生成的;手动提示转换。原始问题和Codex提示不同,Codex提示是由人生成的。当把问题转化为Codex提示时,又出现了一个关键性的问题:原始问题与之后产生正确答案的提示在语义上的接近程度如何?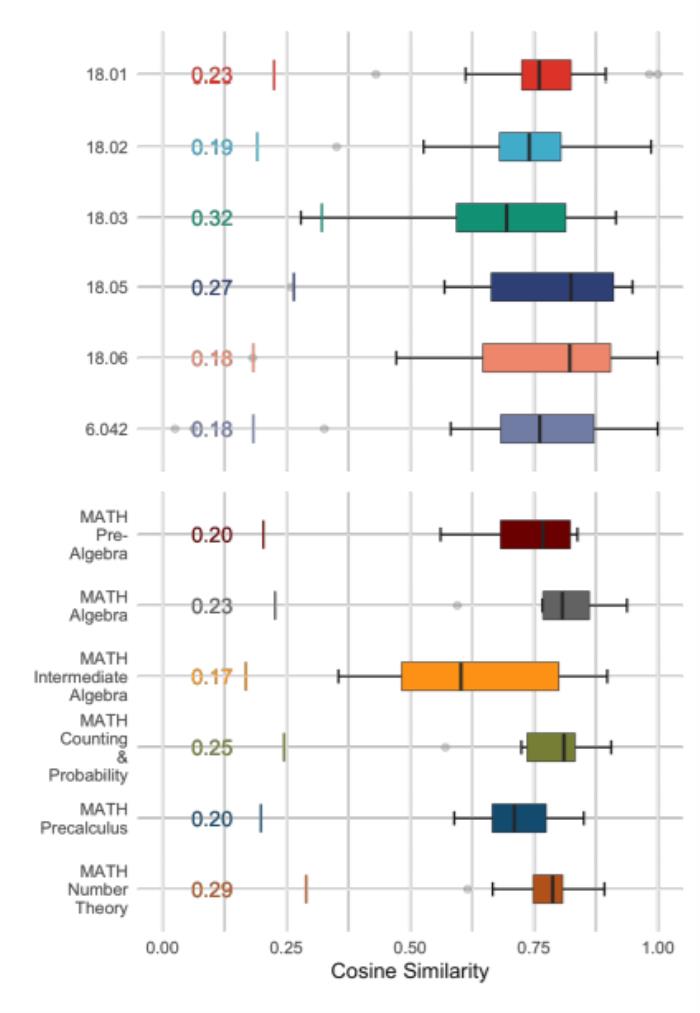 图3:按课程和类别划分的所有问题的余弦相似度分布。如图3所示,为了测量原始问题和转化后之间的差距,他们使用Sentence-BERT嵌入之间的余弦相似度。Sentence-BERT使用siamese和triplet网络结构对预训练的BERT模型进行了微调。Sentence-BERT能够在句子层面上产生语义嵌入,从而可以在长篇文本中进行语义相似度比较。应用他们的方法,对于难度较低的课程,修改少量原始问题(高余弦相似度分数),就可以达到Codex提示,输出一个提供正确答案的程序。而每个框图左边的线代表每门课程的基准相似度分数,通过平均每门课程中所有这样的问题组之间的相似度计算得出。他们还做了原始问题和产生正确答案的转换版本之间的相似性分数的直方图,用来评估。
图3:按课程和类别划分的所有问题的余弦相似度分布。如图3所示,为了测量原始问题和转化后之间的差距,他们使用Sentence-BERT嵌入之间的余弦相似度。Sentence-BERT使用siamese和triplet网络结构对预训练的BERT模型进行了微调。Sentence-BERT能够在句子层面上产生语义嵌入,从而可以在长篇文本中进行语义相似度比较。应用他们的方法,对于难度较低的课程,修改少量原始问题(高余弦相似度分数),就可以达到Codex提示,输出一个提供正确答案的程序。而每个框图左边的线代表每门课程的基准相似度分数,通过平均每门课程中所有这样的问题组之间的相似度计算得出。他们还做了原始问题和产生正确答案的转换版本之间的相似性分数的直方图,用来评估。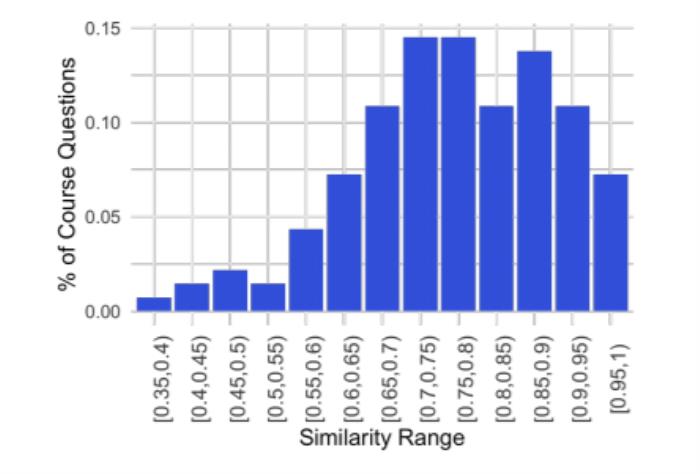 图4:最右边的一列代表了按原样或做了非常小的改动就能正确回答问题所占的百分比。使用Codex进行提示生成也会产生一些问题。在某些课程中,直接用未经转化的原始问题来提示Codex并不能得到正确的答案。因此,需要将原始问题的形式进行转化,他们将其主要分为三类:主题背景。为Codex提供与一般课程和具体问题相关的主题和副主题,可以帮助指导Codex产生正确答案。例如,对于概率中的条件预期问题,提供有关贝叶斯定理、预期值等背景。库背景。为Codex提供解决特定问题所需的编程包/库也是非常有帮助的。例如,引导Codex使用Python中的Numpy包以解决线性代数问题。定义背景。很多时候,Codex缺乏某些术语的定义基础。例如,Codex并不清楚扑克牌中 "Full House "的含义。明确这些术语的定义并让Codex理解它们,可以更好地指导其程序合成。此外,他们还使用Codex,通过从数据集中创建一个有编号的问题列表,为每门课程生成了新的问题。这个列表在生成随机数量的问题后会被切断,其结果将用于提示Codex生成下一个问题。重复进行此过程,就可以为每门课程生成许多新问题。
图4:最右边的一列代表了按原样或做了非常小的改动就能正确回答问题所占的百分比。使用Codex进行提示生成也会产生一些问题。在某些课程中,直接用未经转化的原始问题来提示Codex并不能得到正确的答案。因此,需要将原始问题的形式进行转化,他们将其主要分为三类:主题背景。为Codex提供与一般课程和具体问题相关的主题和副主题,可以帮助指导Codex产生正确答案。例如,对于概率中的条件预期问题,提供有关贝叶斯定理、预期值等背景。库背景。为Codex提供解决特定问题所需的编程包/库也是非常有帮助的。例如,引导Codex使用Python中的Numpy包以解决线性代数问题。定义背景。很多时候,Codex缺乏某些术语的定义基础。例如,Codex并不清楚扑克牌中 "Full House "的含义。明确这些术语的定义并让Codex理解它们,可以更好地指导其程序合成。此外,他们还使用Codex,通过从数据集中创建一个有编号的问题列表,为每门课程生成了新的问题。这个列表在生成随机数量的问题后会被切断,其结果将用于提示Codex生成下一个问题。重复进行此过程,就可以为每门课程生成许多新问题。 图5:学生调查问题。学生要对60个问题中的每一个问题进行评分。如上图所示,他们还在麻省理工学院和哥伦比亚大学选修过这些课程或其同等课程的学生中进行了长时间调查,比较了机器生成的问题和人写的问题在每门课程中的质量和难度。
图5:学生调查问题。学生要对60个问题中的每一个问题进行评分。如上图所示,他们还在麻省理工学院和哥伦比亚大学选修过这些课程或其同等课程的学生中进行了长时间调查,比较了机器生成的问题和人写的问题在每门课程中的质量和难度。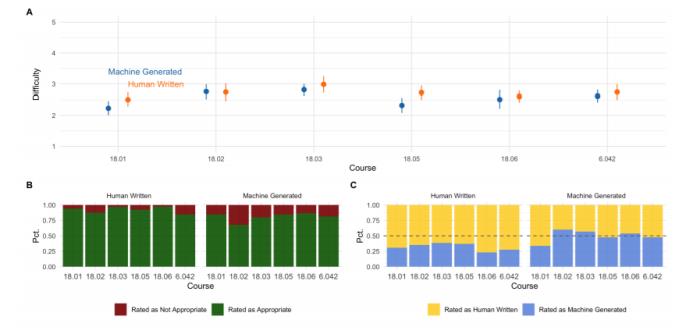 图6. 学生调查结果。A组基于学生的评分,比较了人工编写的问题和本文研究方法为每门课程产生的问题的难度。该图显示了1(最容易)和5(最难)之间的难度评分的平均值,以及它们的95%置信区间。B组显示的是人工编写的和机器生成的问题被评为适合和不适合该课程的百分比。C组显示了被评为人写的或机器生成的问题的百分比。然而,该研究还有一些局限性,如Codex只能接受基于文本的输入,因此该团队的方法无法对输入图像进行处理,无法回答带有必要视觉组成部分的问题,如数字或图表。其次,本研究没有涉及高级数学证明的问题,他们强调,这是研究的广度所带来的限制,而不是Codex的限制。并且,他们的方法最后一步是通过执行一个程序来完成的,例如使用Python解释器,存在局限性。此外,理论上复杂性结果也不适用于本研究解决的具体实例。
图6. 学生调查结果。A组基于学生的评分,比较了人工编写的问题和本文研究方法为每门课程产生的问题的难度。该图显示了1(最容易)和5(最难)之间的难度评分的平均值,以及它们的95%置信区间。B组显示的是人工编写的和机器生成的问题被评为适合和不适合该课程的百分比。C组显示了被评为人写的或机器生成的问题的百分比。然而,该研究还有一些局限性,如Codex只能接受基于文本的输入,因此该团队的方法无法对输入图像进行处理,无法回答带有必要视觉组成部分的问题,如数字或图表。其次,本研究没有涉及高级数学证明的问题,他们强调,这是研究的广度所带来的限制,而不是Codex的限制。并且,他们的方法最后一步是通过执行一个程序来完成的,例如使用Python解释器,存在局限性。此外,理论上复杂性结果也不适用于本研究解决的具体实例。总结该团队的研究证明,对文本进行预训练并对代码进行微调的 Transformers能够解决训练能够通过程序合成解决、评定和生成大学水平的数学问题。问题集的生成和分析进一步验证了这些惊人的结果。这项研究成功证实了现代程序设计语言可以作为一种替代性的表述和计算环境。由他们的方法不需要额外的训练,就可以扩展到其它STEM课程,并且可以给高等教育带来巨大的帮助。他们的研究证实了,用现代编程语言进行的神经网络合成是更有活力和广泛适用的,有可能解决更广泛的问题。尽管任何有限的计算都可以被表示为足够大的表达式树,但人们可能会看到所需的表达式树的大小可能是任意大的。与图灵完备语言相比,这种灵活性得到了加强,因为已经存在的大量程序语料库让可用的标记表达式树的数量黯然失色。“程序输出在本质上也更适合人类阅读。因为使用抽象化、模块化和高级逻辑的能力可以更清晰地说明解决问题的方法。”此外,程序生成可以通过解释性的注释以及函数和变量的名称,直接传达逻辑推论。值得一提的是,在他们的这项研究中在Codex的一些输出中看到了这样的解释文字和推导。“这种正式和非正式语言的统一是我们方法论的一个固有的优势。”参考资料:1. CQ Choi, 7 revealing ways AIs fail: Neural networks can be disastrously brittle, forgetful, and surprisingly bad at math. IEEE Spectr. 58, 42–47 (2021)

相关推荐


- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
热门文章










