

 新火种
2023-10-28
新火种
2023-10-28 


大视觉语言模型基准数据集ReForm-Eval:新瓶装旧酒,给旧有的基准数据集换个形式就能用来评估新的大视觉语言模型
概要
复旦DISC实验室推出了ReForm-Eval,一个用于综合评估大视觉语言模型的基准数据集。ReForm-Eval通过对已有的、不同任务形式的多模态基准数据集进行重构,构建了一个具有统一且适用于大模型评测形式的基准数据集。所构建的ReForm-Eval具有如下特点:
构建了横跨8个评估维度,并为每个维度提供足量的评测数据(平均每个维度4000余条);具有统一的评测问题形式(包括单选题和文本生成问题);方便易用,评测方法可靠高效,且无需依赖ChatGPT等外部服务;高效地利用了现存的数据资源,无需额外的人工标注,并且可以进一步拓展到更多数据集上。我们的基准数据集与评估框架已经开源,具体使用可以参考本推送第4节。第1节介绍了ReForm-Eval的构建动机;第2节介绍了ReForm-Eval的构建、评估方法;第3节介绍了我们基于ReForm-Eval进行的定量分析得到的初步发现;请感兴趣的读者阅读,本文未尽之处请参阅我们的论文。
论文链接:https://arxiv.org/abs/2310.02569
作者信息:
 01引言
01引言
构建开源的类GPT-4的“大视觉语言模型”是最近多模态领域的热潮。目前的大模型,包括BLIP-2,MiniGPT4,LLaVA,Lynx等等,已经展现了令人惊喜的能力。这些模型可以回答图片相关的问题,做OCR,理解网上的梗图,但是也会因为幻觉(object hallucination)胡言乱语。
我们不禁好奇,那么这些模型究竟靠谱吗,哪个模型更好呢?然而目前却很少有定量的分析来评估和对比这些大模型,究其原因在于目前几乎没有适合评估大视觉语言模型的基准数据集。
那为什么之前的多模态数据集无法拿来评估新一代的模型呢?可以跟着我们在图1上半部分中一探究竟:
(1)首先看左上部分,目前多数的基准数据集都是为特定任务设计的,进一步就要求特定的输入-输出形式来辅助完成模型的评估,比如常用的问答数据集VQA 2就要求词/短语级别的简短输出;视觉蕴含任务则是“蕴含、矛盾、中立”关系的三分类任务;物体计数任务则只给出了数字形式的标签。
(2)然而以LLM为基座的大视觉语言模型非常灵活,倾向于输出完整且详细的句子(右上部分),对于第一个问题,虽然输出包括了正确答案,但是VQA v2要求答案完全一致(EM,exactly match);对于第二个问题,模型的理解正确,却没有用特定的词进行表达;对于第三个问题,模型错误输出了信息,但是数字部分却正好蒙对。
总的来说,旧有的基准数据集里任务特定的形式,与新一代的大模型的自由形式的文本输出存在着差异,但这是否意味着我们必须构建新的基准数据集来评估模型呢?
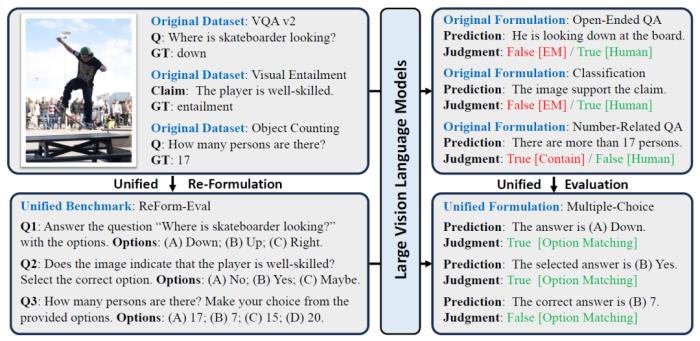
图1:旧有基准数据集和ReForm-Eval的区别。中括号内表示评估方法,红色、绿色分别代表错误和正确的评估结果
我们的答案是否定的,既然现在的大模型无法适应于旧的基准数据集,那么为什么不把旧的数据集重构成适合大模型评估的问题形式呢。参考文本LLM的评估基准中常用的问题形式,我们主要考虑了两种形式:文本生成问题和单选题,前者则主要应用于OCR、图片描述这样严格需求文本生成的场景,后者则适用于重构其余的数据集。图1下半部分展示了几个重构成单选题的例子,进一步可以看出统一化的问题形式也方便进行统一、公平的评估。
基于重构的方法下,我们推出了一个统一化的基准数据集,ReForm-Eval。通过高效的利用现有的数据集资源,不需要额外的人工标注,就能在多种能力维度都提供足量的评估数据。
02 ReForm-Eval介绍
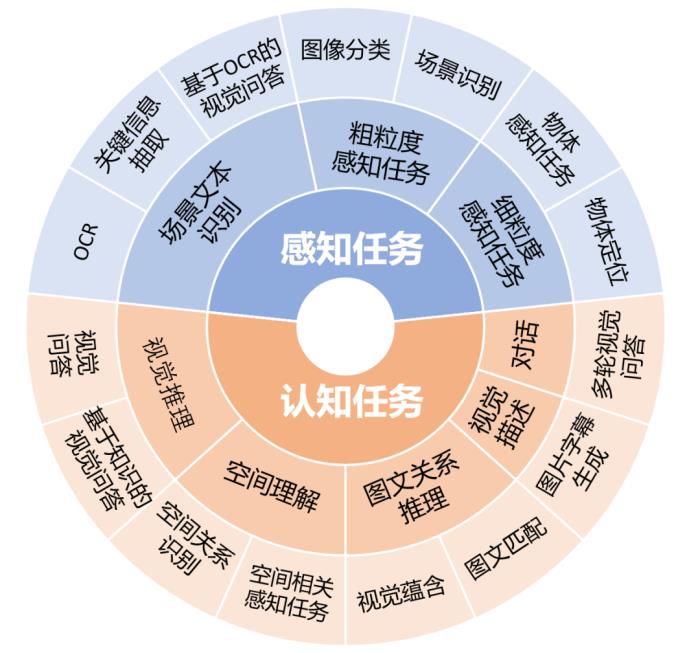
图2:ReForm-Eval中的评估维度和对应的任务
评估维度与构建方法
为了能解决用户提出的多样化问题,LVLM需要具有多样化的能力。ReForm-Eval为了能对模型进行综合的评估,参考图2,我们考虑了2大类,8小类的能力维度,每个能力维度下通过不同任务进行评估,对于每个任务,我们重构了该任务下的多个数据集作为评测的数据。
虽然任务多样,但是ReForm-Eval将对应的数据重构成了统一的问题形式:
特定场景下文本生成任务:a. OCR类任务:用于评估场景文本识别能力,要求模型检测出图片中完全一致的目标词;b. 描述任务:要求模型对视觉内容进行简短的描述单选题:利用样本的正确答案标签作为正确选项,我们采取不同方法来根据原有基准数据集的形式来高效地构建负选项:
a. 分类任务:如ImageNet,我们通过WordNet等方式构建了候选类别间的关系,并基于此选择与样本标签相近的类别作为负选项,若分类类别较少,则使用所有的类别作为选项;
b. 开放问答任务:如VQA 2.0,因为原有数据集中常出现的答案可能与正确答案相关性较低,我们通过ChatGPT的帮助从问题+正确答案里产生相关却不等价的负选项;
c. 其余特定形式的任务:主要通过适合该任务需求的策略进行负选项构建,比如图文匹配中的负选项来自数据集中用于描述其他图片的文本,并根据与正确答案的相似度进行排序选取困难的负选项;
每个任务相关的数据集和具体构建细节请参见我们的论文。
评估方法
ReForm-Eval中统一的问题形式使得我们可以通过统一的评估方法,来对来自数据集的不同样本上模型的输出进行一致的评估。
1. 对于文本生成任务的评估:我们根据具体的场景设计了不同的评估方法.
a. OCR任务:
评估指标:词级别的准确率(图片中的正确词完整出现在模型输出文本中的比例)评估方法:自由式文本生成,通过设计prompt引导模型检测目标文本;b. 视觉描述任务:
评估指标:CIDEr评估方法:自由式文本生成,通过设计prompt要求简短的输出,并额外基于对应数据集的特点限制模型生成文本最大长度2. 对于单选题的评估:
评估指标:准确率,检测模型输出中的选项标记,比如“(A)”来判断模型的输出类别评估方法:我们发现很多模型无法遵循单选题的指令,无法正确输出特定格式的选项,我们通过两种方式进行辅助评估:a. 黑盒方法(Generation Evaluation):通过仅文本的in-context sample来引导模型按期望的格式输出,例子如下

其中红色部分为提供的in-context sample,需要注意该样本不提供图片相关的信息,仅提供输出结构的引导,实验过程中我们发现该策略非常有效,能引导模型在多数情况下输出期望的格式
b. 白盒方法 (Likelihood Evaluation):直接计算模型在给定图片、问 题下对于不同选项的生成概率,选择最高的作为模型的选择
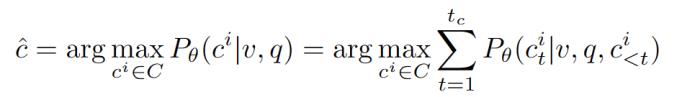
其中v,q,c分别为图片,问题和候选答案,P是目标大模型预测的生成概率(自回归式)。
3. 考虑稳定性的评估方法:因为大模型对于输入的文本非常敏感,所以ReForm-Eval考虑了评估中的不稳定性,并进行了稳定性的度量
a. 重复测试:对于同一个任务,ReForm-Eval提供了不同的问题模板,对于每个样本,将会进行N次测试,每次使用不同的模板,如果是选择题还会打乱选项的顺序,使用不同的选项记号,取多次测试的平均值作为正确率;
b. 不稳定性度量:对于单选题,取N次实验中对于预测答案分布的熵作为不稳定性的度量;对于文本生成任务,因为无法度量输出的分布,所以无法直接进行度量。
03 定量分析与发现
我们评估了包括BLIP-2,LLaVA,MiniGPT-4,Lynx等等一系列13个方法训练得到的16个模型,并进行了相关的分析,具体的表现与分析请参考我们的论文,以下为读者总结了一些我们初步的发现:

1. 对于基座模型的选择(Figure 3):
a. 对于语言模型的选择,需要考虑选择本身具有一定指令遵循能力的基座,如FlanT5,Vicuna,LLaMA2-Chat
b. 对于视觉编码器的选择,基于CLIP,EVA-CLIP的ViT是普遍且较优的选择,越大的ViT也能为大视觉语言模型提供更好的视觉表示,进一步需要根据不同的视觉模型选择一个合适的连接模块(如q-former,linear等);
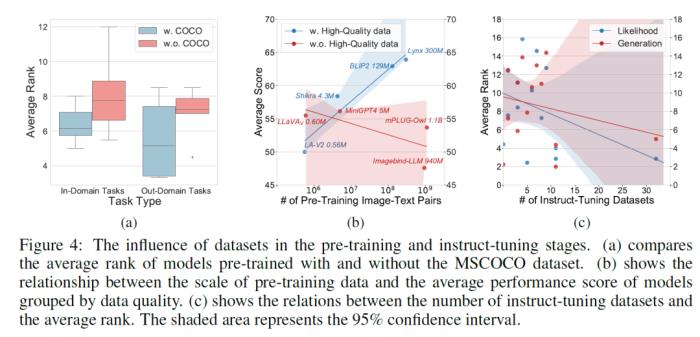
2. 训练数据方面(Figure 4):
a. 预训练数据:质量是非常重要的,表现好的LVLM普遍使用高质量的人工标注数据集COCO;如果需要在数据数量的进一步扩展,直接使用质量较低的LAION效果并不好,使用BLIP中重新为图片生成的字幕(BLIPCapFilt数据集)会是更有效率的选择,这很可能是BLIP-2,Lynx,BLIVA成功的原因;
b. 指令微调数据集的丰富程度是最重要的,指令微调的数据集数量越多,模型的泛化能力和表现越强,然而目前很多模型都只在有限的数据集上进行了指令微调。
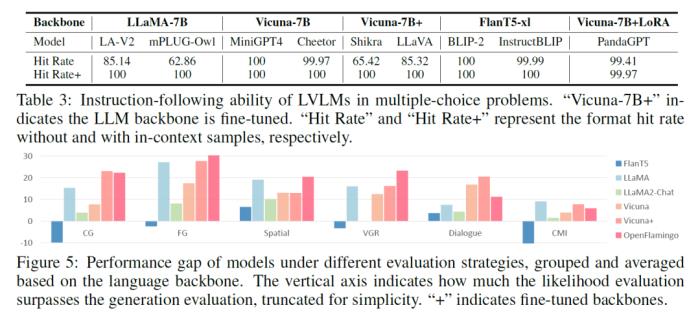
3. 指令遵循能力方面(Table 3 和 Figure 5):
a. 目前的LVLMs指令遵循能力有限,但通过黑盒方法里的in-context样本能有效地提供结构信息,引导模型以期望的形式进行输出,是当下帮助完成LVLM评估的有效解决方案;
b. 指令遵循能力主要与模型使用的语言基座相关,基于FlanT5,Vicuna,LLaMA2-Chat的模型遵循能力会比基于llama的模型较好;
c.与此同时,全参微调语言基座反而会损害模型的这方面能力(LoRA微调则不会);
d. 很多模型,比如BLIVA,Lynx只有在白盒测试方法下才体现出其有效性。说明虽然黑盒方法下很多模型可以成功输出选项,但是模型因为对与选择题理解不够,无法将内部的知识输出到文本中,需要白盒方法作为额外的辅助;
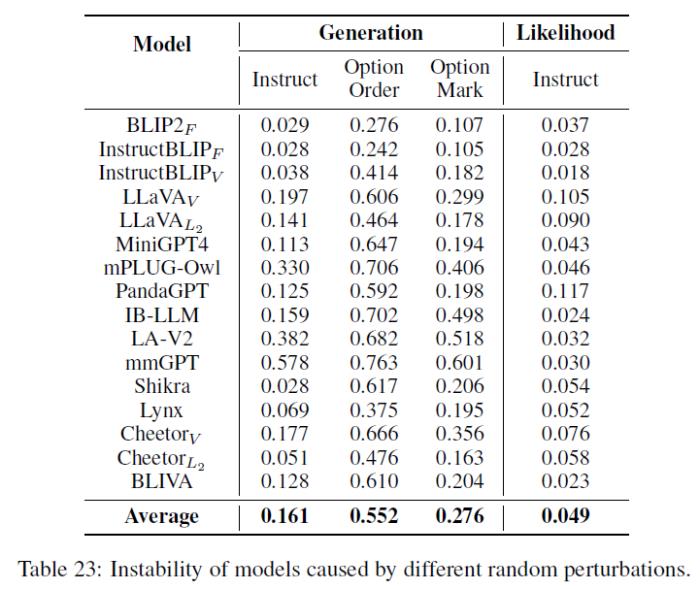
4. 模型都存在一定的不稳定性(Table 23):
a. 对于输入的prompt中较小的改变敏感,尤其是选项的顺序,说明整体上模型对于选择题指令的理解有限;
b. 不同模型存在一定程度的对于选项的偏好(具体请参考论文中的Figure 10);
c. 基于白盒方法的度量的不稳定性较小,因为其直接评估了模型内部的建模概率,且不需要生成时的采样。
04使用ReForm-Eval
ReForm-Eval的数据以及评估框架已经开源,请参考https://github.com/FudanDISC/ReForm-Eval/。
这里我们给出关于具体使用方法的简单介绍,我们为用户提供了两种主要的使用方法:
1. 用户将需要评测的模型迁移到ReForm-Eval适配的interface形式,基于ReFrom-Eval的框架进行评测:
a. 用户可以参考GitHub中Create Your Own Model Interface一节,通过将新的模型推理接口迁移到ReForm-Eval中的interface类形式,提供generation / likelihood evaluation的接口,并提供正确的读取方式(用户还需注意提供preprocessor方法,来将评测数据处理成模型需要的文本输入形式);
b. 构建完成后直接调用评估入口run_eval.py,修改其中的模型参数来调用新的模型接口即可完成对新模型的评估,ReForm-Eval支持多卡、半精度评测,输出的结果以及指标会分别存储在json,log文件中;
2. ReForm-Eval仅提供dataset和evaluate接口,用户通过自己的模型接口进行推理:
a. 通过ReForm-Eval提供的build.load_reform_dataset的接口获取ReForm-Eval评测的数据集,读取到的数据将以字典的形式提供给用户(需要注意用户需要自己实现或使用ReForm-Eval中的Preprocessor类功能来讲字典里的结构数据处理成模型需要的文本输入形式);
b. 用户使用自己的模型推理接口对读取到的数据进行推理,并将模型的预测写入“prediction”字段,将完整的结果输出到json文件中;
c. 使用ReForm-Eval中提供的评估接口run_loader_eval.py对上一步输出的json文件进行评估;
上述描述未尽之处,请参见GitHub中的Getting start部分的pipeline节。
用户基于上述流程,通过修改data相关的参数就能完成对多个数据集的评估,所有61个数据集对应的参数请参考GitHub中的Data Usage部分。
ReForm-Eval默认通过huggingface来提供数据的自动下载和读取,不需要手动进行下载,如果在huggingface下载中遇到问题,也可以通过手动下载等方式来获取数据。
如果您在使用过程中遇到困难,请务必通过Github Issue告知我们,或者邮件联系yewang22@m.fudan.edu.cn。
*封面图生成自DALL·E 3,提示词“A tree grows from a withered seed in ice, in the new era, digital art”相关推荐



- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。










