

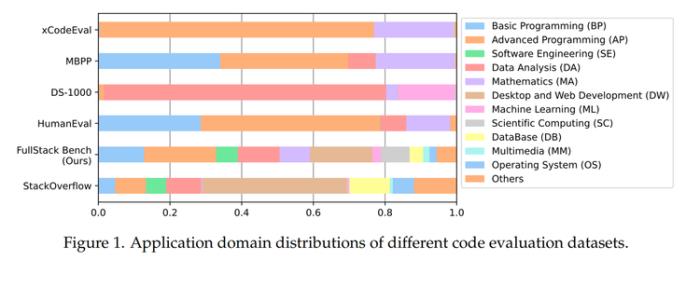
首次覆盖超11类编程场景!字节开源最全面代码大模型基准fullstackbench
代码大模型越来越卷,评估AI编程水平的“考卷”也被迫升级。12月5日,字节豆包大模型团队开源最新代码大模型评估基准FullStack Bench,在业界首次囊括编程全栈技术中超11类真实场景,覆盖16种编程语言,包含3374个问题,相比此前基准,可以更有效地评估大模型在现实世界中的代码开发能力。代码
代码大模型越来越卷,评估AI编程水平的“考卷”也被迫升级。12月5日,字节豆包大模型团队开源最新代码大模型评估基准FullStack Bench,在业界首次囊括编程全栈技术中超11类真实场景,覆盖16种编程语言,包含3374个问题,相比此前基准,可以更有效地评估大模型在现实世界中的代码开发能力。代码

上海交通大学 APEX 实验室“Write the code. Change the world.”If computers can write code, then it is a new world.打造能自己写代码的机器,这是计算机科学和人工智能先锋者一直在追寻的目标。

1、SuperCLUE发布2023中文大模型基准测评报告2、谷歌推出AI Core应用,管控手机本地AI模型3、微软Copilot将升级至GPT-4 Turbo4、HF CEO分享2024年AI行业六大预测5、Salesforce将在AWS上销售AI软件等6、中英加强AI等领域合作交流7、百度资本等

编辑 | ScienceAI近日,认知智能全国重点实验室、中国科学技术大学陈恩红教授团队,科大讯飞研究院 AI for Science 团队发布了论文《ChemEval: A Comprehensive Multi-Level Chemical Evaluation for Large Langua

12月30日,清华大学教授孙茂松带领的团队在北京发布了机器中文语言能力评测基准“智源指数”CUGE,在北京智源人工智能研究院自然语言处理(简称NLP)重大研究方向前沿技术开放日活动上,由清华大学教授孙茂松带领的团队发布了机器中文语言能力评测基准“智源指数”(CUGE)。

12月21日,OpenAI 发布了具有超强推理能力的大模型o3,引起了业内对大模型推理能力的广泛讨论和深入研究。o3的发布也带来了三个引人深思的问题:市面上主流大模型的推理能力究竟如何?在真实应用场景中,是否总是需要具有极强推理能力的模型?在实际应用中,如何根据应用需求选择合适参数量的大模型而避免“
GPT-4o再次掀起多模态大模型的浪潮。如果他们能以近似人类的熟练程度,在不同领域执行广泛的任务,这对许多领域带来革命性进展。因而,构建一个全面的评估基准测试就显得格外重要。然而评估大型视觉语言模型能力的进程显著落后于它们自身的发展。

12月25日至26日,以“大模型·大未来”为主题的“2024人工智能大模型基准测试科创发展大会”(下称“大会”)在成都举办。来自中国科学院、北京大学等高校和研究机构的专家学者、中国信通院人工智能研究中心等权威机构以及超过百家人工智能产业企业齐聚一堂,共同探讨人工智能产业发展新方向

概要复旦DISC实验室推出了ReForm-Eval,一个用于综合评估大视觉语言模型的基准数据集。ReForm-Eval通过对已有的、不同任务形式的多模态基准数据集进行重构,构建了一个具有统一且适用于大模型评测形式的基准数据集。所构建的ReForm-Eval具有如下特点:构建了横跨8个评估维度,并为每

中国科大等机构联合团队发布了SciGuard和SciMT-Safety,用于保护AI for Science模型,防止在生物、化学、药物等领域滥用,并建立了首个专注于化学科学领域安全的基准测试。研究团队发现开源AI模型存在潜在风险,可被用于制造有害物质并规避法规。










