新火种 2023-11-13
新火种 2023-11-13 
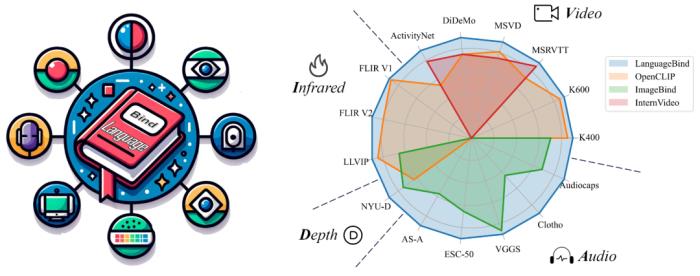
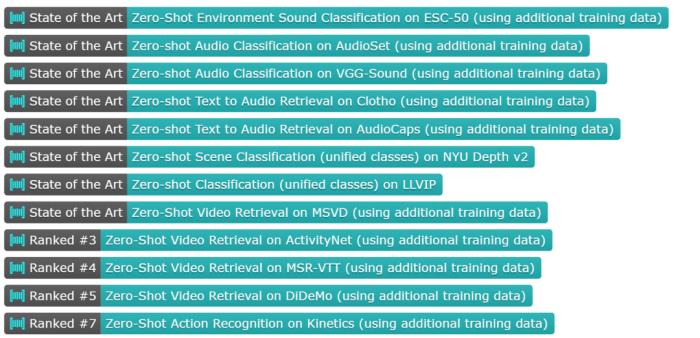
用语言对齐多模态信息,北大腾讯等提出LanguageBind,刷新多个榜单
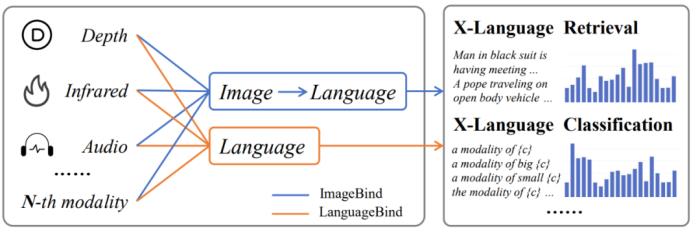
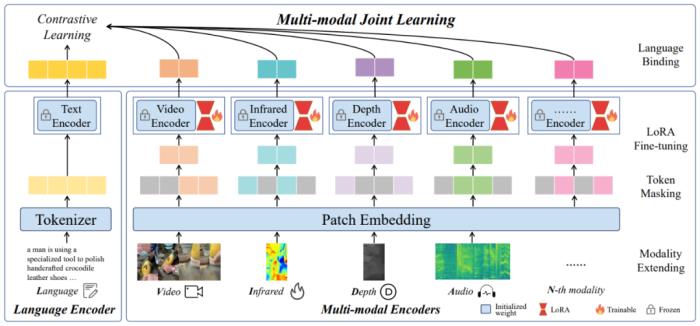
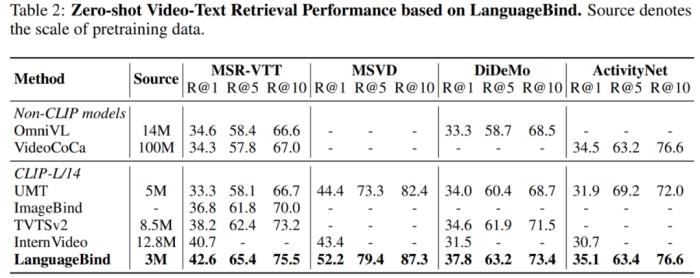
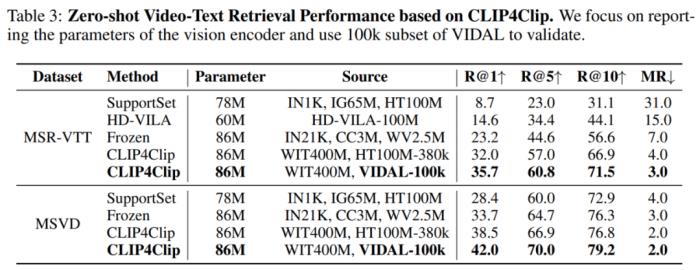
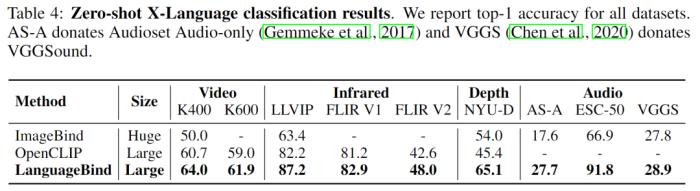
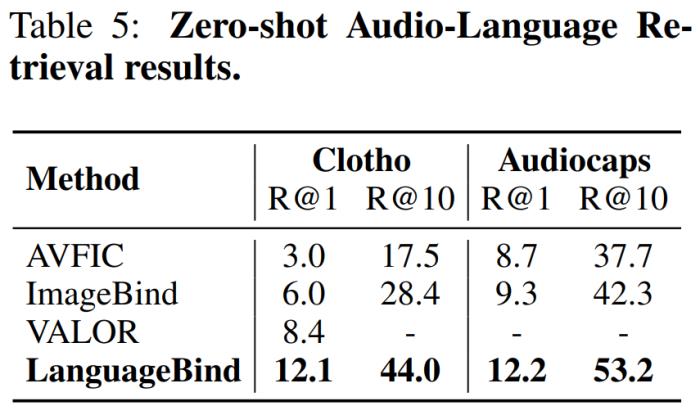
北京大学与腾讯等机构的研究者们提出了多模态对齐框架 ——LanguageBind。该框架在视频、音频、文本、深度图和热图像等五种不同模态的下游任务中取得了卓越的性能,刷榜多项评估榜单,这标志着多模态学习领域向着「大一统」理念迈进了重要一步。在现代社会,信息传递和交流不再局限于单一模态。我们生活在一个多模态的世界里,声音、视频、文字和深度图等模态信息相互交织,共同构成了我们丰富的感知体验。这种多模态的信息交互不仅存在于人类社会的沟通中,同样也是机器理解世界所必须面对的挑战。如何让机器像人类一样理解和处理这种多模态的数据,成为了人工智能领域研究的前沿问题。在过去的十年里,随着互联网和智能设备的普及,视频内容的数量呈爆炸式增长。视频平台如 YouTube、TikTok 和 Bilibili 等汇聚了亿万用户上传和分享的视频内容,涵盖了娱乐、教育、新闻报道、个人日志等各个方面。如此庞大的视频数据量为人类提供了前所未有的信息和知识。为了解决这些视频理解任务,人们采用了视频 - 语言(VL)预训练方法,将计算机视觉和自然语言处理结合起来,这些模型能够捕捉视频语义并解决下游任务。然而,目前的 VL 预训练方法通常仅适用于视觉和语言模态,而现实世界中的应用场景往往包含更多的模态信息,如深度图、热图像等。如何整合和分析不同模态的信息,并且能够在多个模态之间建立准确的语义对应关系,成为了多模态领域的一个新的挑战。为了应对这一难题,北大与腾讯的研究人员提出了一种新颖的多模态对齐框架 ——LanguageBind。与以往依赖图像作为主导模态的方法不同,LanguageBind 采用语言作为多模态信息对齐的纽带。



相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
热门文章