

 新火种
2023-11-30
新火种
2023-11-30 


北大最新多模态大模型开源:混合数据集训练,图像视频任务直接用
训完130亿参数通用视觉语言大模型,只需3天!
北大和中山大学团队又出招了——在最新研究中,研究团队提出了一种构建统一的图片和视频表征的框架。
利用这种框架,可以大大减少VLM(视觉语言大模型)在训练和推理过程中的开销。

具体而言,团队按照提出的新框架,训练了一个新的VLM:Chat-UniVi。
Chat-UniVi能在混合图片和视频数据的情况下进行训练,并同时处理图片任务和视频理解任务。
以此为基础,Chat-UniVi在图片及视频上的17个基准上,都表现得还不错。
现在,项目已经在GitHub和抱抱脸上开源。
更多关于新方法和Chat-UniVi的详细信息,我们一起进一步来看看~
Chat-UniVi是什么?了解基础信息后,我们详细地聊聊Chat-UniVi究竟是什么——
简单来说,Chat-UniVi是一个统一的多模态大型语言模型,可以同时理解图像和视频。
目前VLM运用的方法,偏图片理解的,往往使用大量视觉tokens来获得更精细的空间分辨率。
偏视频理解的方法,则常常选择牺牲每帧的空间分辨率,以输入更多帧来构建更精细的时间理解能力。
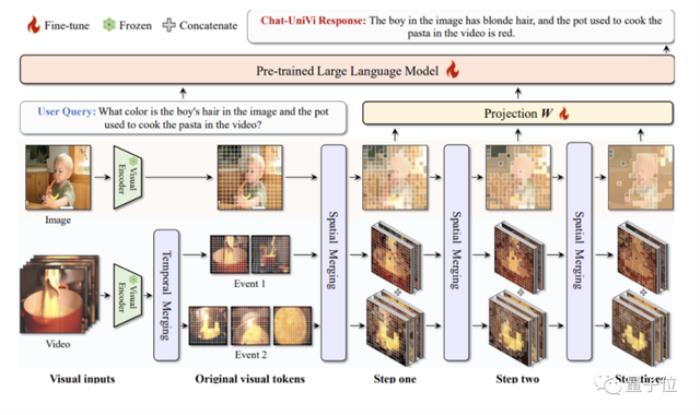
与它们不同,Chat-UniVi采用动态视觉token来统一表示图像和视频,动态token合并方法是无参数的,不需要额外训练。
而动态token的来源,是渐进地聚类视觉token。
为了获取这些动态的视觉token,研究人员基于最近邻的密度峰聚类算法,逐步对视觉token进行分组和合并。
其中,图片可以通过不同大小的视觉token进行建模。
举个:
图中的羊就需要相对更多的视觉token进行细粒度表示;但背景里的雪山,一个视觉token就可以充分搞定建模。

至于视频,处理视频时,同样采用最近邻的密度峰聚类算法,以获取事件的帧集合。
Chat-UniVi会把它划分为多个关键事件,然后在事件内部拓展视觉token。
当然了,如果使用这种方法,更长的视频就会被分配到更多的视觉token,因此如果身处可变长度视频的情境下,这种方式比现有方式更有优势。
总而言之,这种图片和视频的统一表示,一边减少了视觉token的数量,一边又保持了模型的表达能力。
同时又由于视觉token数量的减少,利用这种方式训练模型和进行推理的成本,会大幅度降低——练一个具有130亿参数的VLM,只需要3天。
多提一嘴,为了进一步提升模型性能,团队还为LLM提供了一个多尺度表征。
多尺度表征的上层特征表示高级语义概念,而下层特征则强调了视觉细节的表示。
说到这,我们可以总结出Chat-UniVi的2大特点:
第一,因为独特的建模方法,Chat-UniVi的训练数据集可以是图片与视频的混合版,并且无需任何修改,就可以直接应用在图片和视频任务上。
第二,多尺度表征能帮助Chat-UniVi对图片和视频进行更到位、更全面的理解。
这也导致了Chat-UniVi的任务适应性更强,包括使用高层次特征进行语义理解,以及利用低层次特征生成详细描述。
 分两阶段训练
分两阶段训练Chat-UniVi的训练分为两个阶段。
第一步是多模态预训练。
在这个阶段,研究人员冻结了LLM和视觉编码器,同时只对投影矩阵进行训练。
这种训练策略使得模型能够有效地捕获视觉信息,而不会对LLM的性能造成任何明显的损害。
第二步是联合指令微调。
在第二阶段,团队对整个模型进行了全参数微调,使用了一个包含图片和视频的混合数据集。
通过在混合数据集上进行联合训练,Chat-UniVi实现了对大量指令的卓越理解,并生成了更自然、更可靠的输出。

训练过程中,团队进行了如下实验:
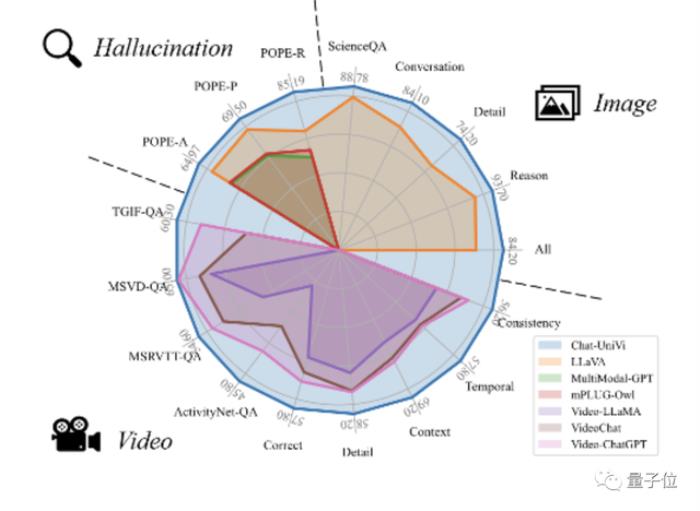
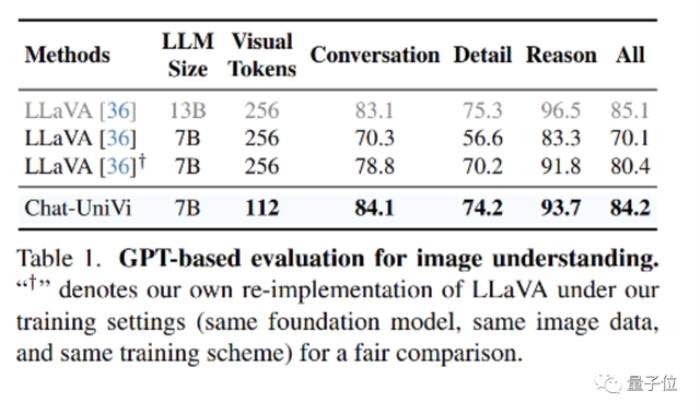
图片理解实验Chat-UniVi在使用更少的视觉标记的同时,性能表现也很不错。
7B参数的Chat-UniVi模型能达到13B大小LLaVA模型的性能水平。这证明了该方法的有效性。
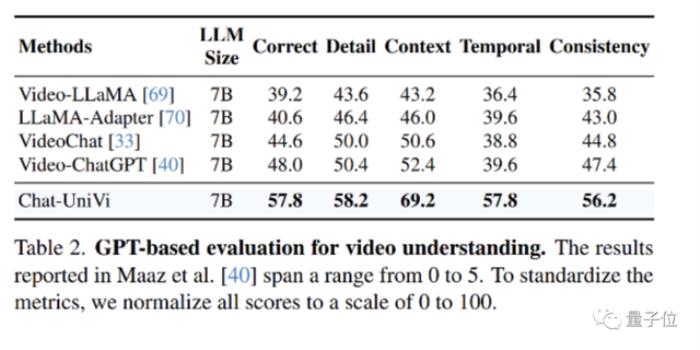
 视频理解实验
视频理解实验作为一个统一的VLM,Chat-UniVi超越了专门针对视频设计的方法,如VideoChat和Video-ChatGPT。
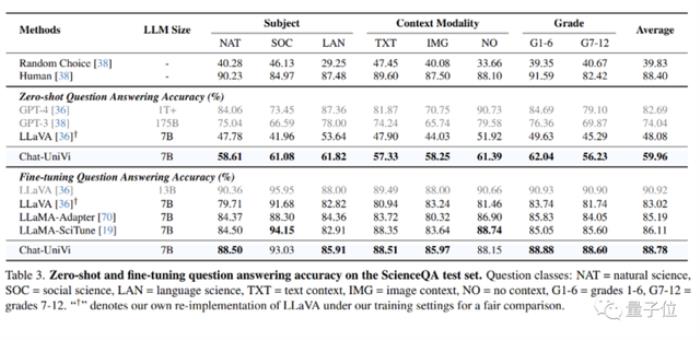
 图片问答实验
图片问答实验Chat-UniVi在ScienceQA数据集上性能表现良好,其性能优于专门针对科学问答进行优化的LLaMA-SciTune模型。
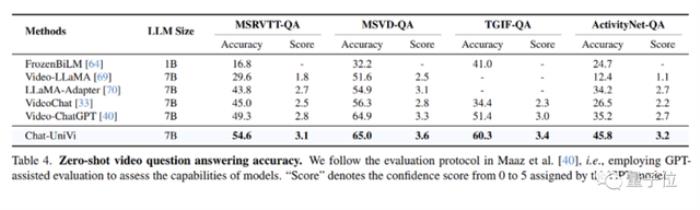
 视频问答实验
视频问答实验在所有数据集上,Chat-UniVi均表现优于最先进的方法,如VideoChat和Video-ChatGPT等。
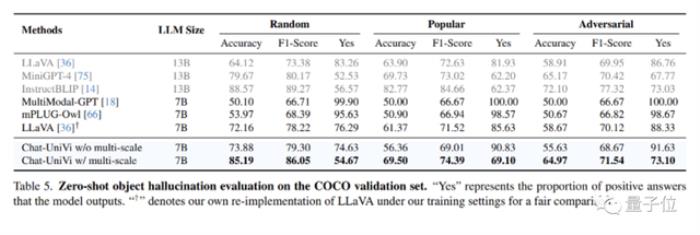
 幻觉实验
幻觉实验在幻觉评估方面,Chat-UniVi表现优于最近提出的最先进方法。
值得注意的是,作为一个7B模型,Chat-UniVi在性能上超越了13B参数大小的MiniGPT-4。
研究人员将这一成功归功于多尺度表征,这使得模型能够同时感知高级语义概念和低级视觉外观。
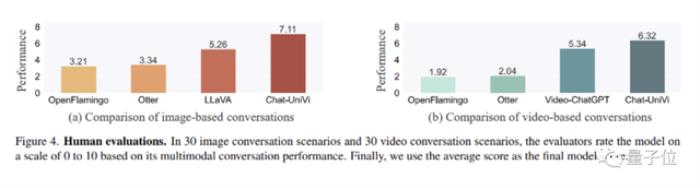
 人工评测实验
人工评测实验同时,研究人员还进行了人工评估实验。
他们发现,基于Flamingo的方法在理解视频的能力上存在局限性。这种限制归因于它们使用Q-Former从不同长度的视频中提取固定数量的视觉标记,这阻碍了它们在建模时间理解方面的有效性。
相比之下,作为一个统一的模型,Chat-UniVi不仅优于基于Flamingo构建的方法,而且超越了专门为图片和视频设计的模型。
 可视化
可视化Chat-UniVi所采用的动态视觉token巧妙地概括了对象和背景。
这使得Chat-UniVi能够以有限数量的视觉token,同时建模图片理解所需的细粒度空间分辨率和视频理解所需的细粒度时间分辨率。
 团队介绍
团队介绍论文一作是北大信息工程学院博三学生金鹏。
通讯作者袁粒,北大信息工程学院助理教授、博士生导师。
其研究方向为多模态深度学习和AI4S,其中AI4S方向主要研究深度学习解决化学生物中的重大问题。
此前网络大火的ChatExcel、ChatLaw等垂直领域大模型项目都出自袁粒团队。
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。










