新火种
2024-11-29
新火种
2024-11-29 


ScalingLaw百度最早提出!OpenAI/Claude受它启发,致谢中有Ilya
什么?Scaling Law最早是百度2017年提的?!
Meta研究员翻出经典论文:
大多数人可能不知道,Scaling law原始研究来自2017年的百度,而非三年后(2020年)的OpenAI。

此研究由吴恩达主持,来自百度硅谷人工智能实验室 (SVAIL) 系统团队。
他们探讨了深度学习中训练集大小、计算规模和模型精度之间的关系,并且通过大规模实证研究揭示了深度学习泛化误差和模型大小的缩放规律,还在图像和音频上进行了测试。
只不过他们使用的是 LSTM,而不是Transformer;也没有将他们的发现命名为「Law」。

再回头看,其中一位作者Gregory Diamos给自己当年在百度的介绍还是LLM Scaling Law Researcher。

又有一网友发现,OpenAI论文还引用了2019年这位作者Gregory Diamos等人的调查。但却不知道他们2017年就有了这么一项工作。

网友们纷纷表示这篇论文非常值得一读,而且完全被低估。
来赶紧看看这篇论文。
深度学习Scaling是可预测的在深度学习领域,随着模型架构的不断探索、训练数据集的不断增大以及计算能力的不断提升,模型的性能也在不断提高。
然而,对于训练集大小、计算规模和模型精度之间的具体关系,一直缺乏深入的理解。

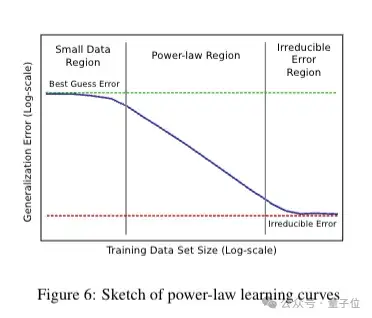
本文通过大规模的实证研究,对多个机器学习领域(如机器翻译、语言建模、图像分类和语音识别)进行了测试,发现了一些规律:
泛化误差(模型在新数据上的表现误差)与训练集大小呈现幂律关系,即随着训练集的增大,泛化误差会以一定的幂次下降。
模型大小与与数据大小也存在Scaling(缩放)关系,通常模型大小的增长速度比数据大小的增长速度慢。
具体来说,结合以往工作,团队将注意力集中在准确估计学习曲线和模型大小的缩放趋势上。
按照一般测量方法,是选择最先进的SOTA模型,并在训练集的更大子集(碎片)上训练这些模型的 “超参数缩减 ”版本,以观察模型的准确性如何随着训练集的大小而增长。
因此针对这四个领域,机器翻译、语言建模、图像分类和语音识别,找到了他们在大型数据集上显示出 SOTA 泛化误差的模型架构。
这里的 “大型数据集 ”是指规模可以缩小 2-3 个数量级,但仍足以进行有价值的模型架构研究的训练集。他们为某些 ML 领域选择了一种以上的模型架构,以比较它们的扩展行为。
机器翻译
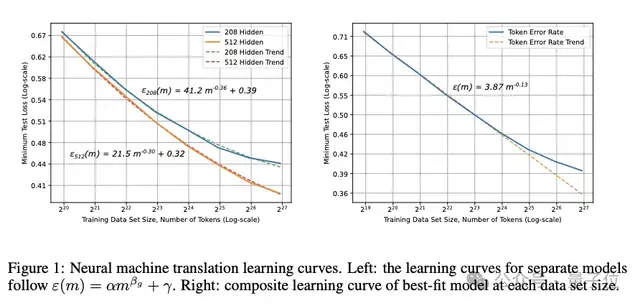
团队注意到,随着训练集规模的增大,优化变得更加困难,而且模型会出现容量不足的情况,因此经验误差会偏离幂律趋势。
词语言模型
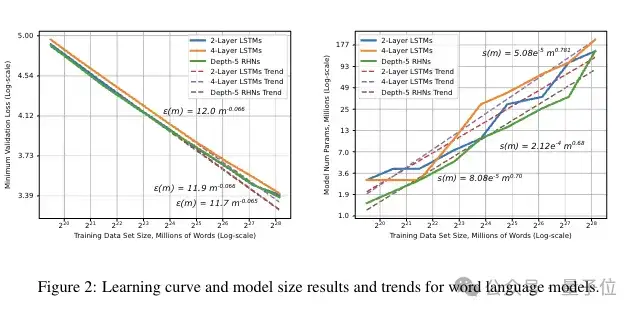
这一结果表明,最佳拟合模型随训练分片大小呈次线性增长。
字符级语言模型
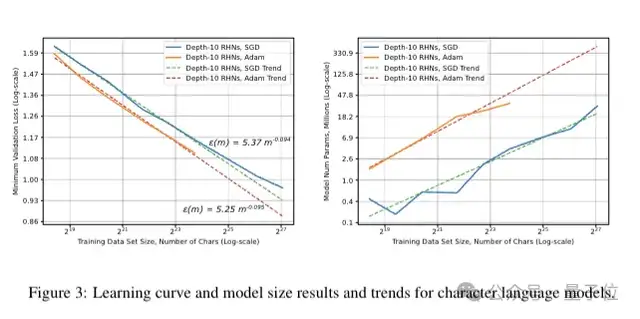
为了测试字符级语言建模,他们训练了深度为 10 的循环高速公路网络(RHN),结果发现该网络在十亿单词数据集上能达到最先进的(SOTA)准确率。
图像分类。
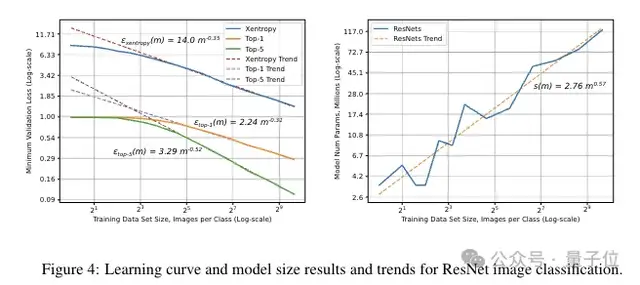
图像分类同样呈现出幂律学习曲线和模型大小的缩放关系。并且还表明,在非常小的训练集上,准确率会在接近随机猜测的水平上趋于平稳。
语音识别。
团队训练了一系列跨度较大的模型尺寸,所以针对每个训练数据大小得出的模型尺寸缩放结果,其意义不像在语言模型(LMs)或图像分类中那么明显。
随着数据量的增加,大多数模型会经历幂律泛化改进,直至数据量接近其有效容量。在这种情况下,参数为 170 万的模型的准确率在大约 170 小时的音频数据时开始趋于平稳,而参数为 600 万的模型在大约 860 小时的音频数据时趋于平稳(也就是说,大约是前者的 5 倍,这与模型尺寸的差异情况类似)。更大的模型(例如,参数为 8700 万的模型)在更大的数据集规模下,其泛化误差也更接近最佳拟合趋势。
最后对于这一发现,他们表示,这些比例关系对深度学习的研究、实践和系统都有重要影响。它们可以帮助模型调试、设定准确度目标和数据集增长决策,还可以指导计算系统设计,并强调持续计算扩展的重要性。
博客致谢中还有Ilya的名字此次研究主要是由当年吴恩达主持下,百度硅谷人工智能实验室 (SVAIL) 系统团队。
当时的一群合著者们已经各自去到各个机构实验室、大厂继续从事大模型相关的研究。

在当年博客致谢中,还出现了Ilya的名字,感谢他们参与了这一讨论。

两年后,也就是2019年,其中一位作者Gregory Diamos又带领团队探讨了深度学习的计算挑战。

后面的OpenAI论文正是引用了这篇论文的调查讨论了Scaling Law。
值得一提的是,Anthropic CEODario Amodei在百度研究院吴恩达团队工作过,他对Scaling Law的第一印象也是那时研究语音模型产生的。

Amodei刚开始研究语音神经网络时有一种“新手撞大运”的感觉,尝试把模型和数据规模同时扩大,发现模型性能随着规模的增加而不断提升。
最初,他以为这只是语音识别系统的特例。但到了2017年,看到GPT-1的结果后意识到这种现象在语言模型上同样适用。
当年(2015年)他一作发表的论文Deep Speech,合著者中这位Sharan Narang正是两年后这篇论文的主要作者之一。如今后者先后去到了谷歌担任PaLM项目TL大模型负责人,然后现在是Meta当研究员。


如今这一“冷知识”再次出现在大家的视野,让不少人回溯并重温。
这当中还有人进一步表示:真正的OG论文使用了seq2seq LSTM,并且确定了参数计算曲线。

当年的一作正是Ilya Sutskever。
参考链接:
相关推荐



- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
热门文章