新火种
2024-05-15
新火种
2024-05-15 


首个中文原生DiT架构!腾讯混元文生图大模型宣布全面开源
5月14日消息,今日,腾讯旗下混元文生图大模型(混元DiT,Diffusion Models with Transformers)宣布全面开源。
目前已在Hugging Face、Github上发布,包含模型权重、推理代码、模型算法等完整模型,供企业与个人开发者免费商用。

据媒体报道,腾讯混元文生图负责人卢清林表示,混元DiT开源的价值有两方面。
一方面这是业内首个中文原生DiT架构,弥补了开源社区的空白,另一方面混元DiT为全面开放,与现网版本完全一致。
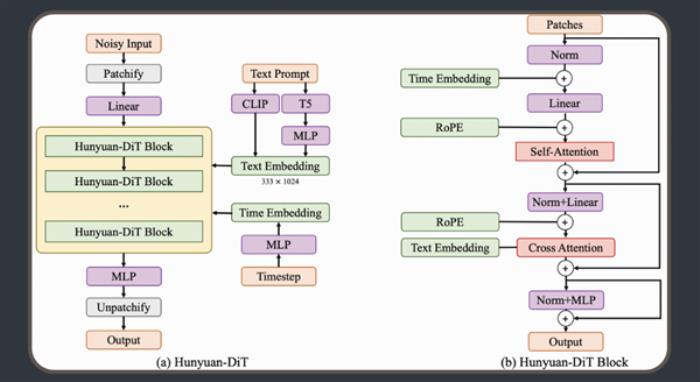
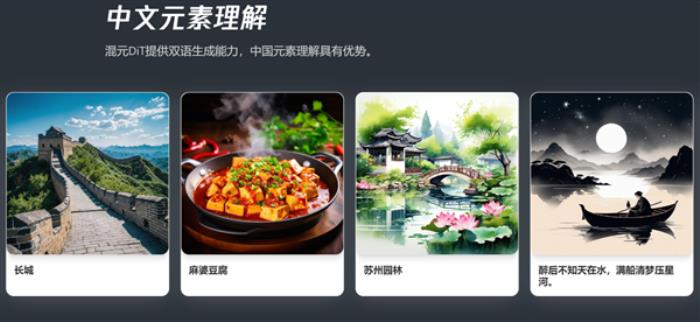
据介绍,此次开源的混元DiT采用了与Sora同样的背后关键技术——DiT架构,还支持256字中文理解,不仅支持文生图,也可作为视频等多模态视觉生成的基础。
腾讯方面表示,为了构建混元DiT设计了Transformer结构、文本编码器和位置编码,构建了完整的数据管道,用于更新和评估数据,为模型优化迭代提供帮助。
为了实现细粒度的文本理解,还训练了多模态大语言模型来优化图像的文本描述。
最终,混元DiT能够与用户进行多轮对话,根据上下文生成并完善图像。


相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
热门文章