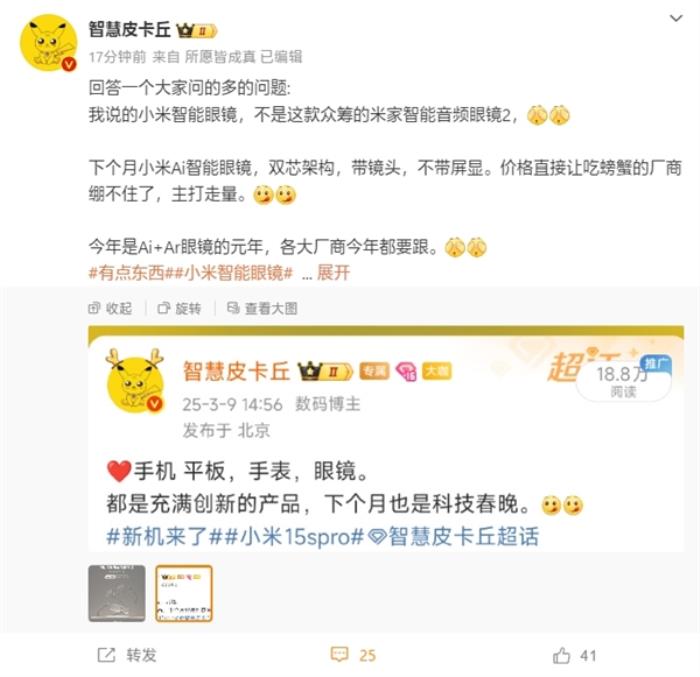
新火种
2024-01-17
新火种
2024-01-17 


Meta承认使用盗版书籍训练AI:拒绝赔偿作家
1月14日消息,据国内媒体报道,Meta最近因使用数千本盗版书籍训练人工智能模型存在法律风险而引发版权侵权诉讼。
据悉,Meta使用大量盗版书籍的“Books3”数据集训练其LLAM 1和LLAM 2模型,Meta虽承认使用了 Books3 数据集,却拒绝向作者支付适当的补偿。
Books3是一个包含19.5万本图书、总容量近37GB的文本数据集,由AI研究者Shawn Presser于2020年创建,旨在为改进机器学习算法提供更好的数据源。
Meta也将其用于训练自己的LLAM模型,然而Books3中包含大量从盗版网站Bibliotik爬取的受版权保护作品,使得Meta的行为面临法律风险。
多位科技公司今年面临类似的投诉,指责他们在构建生成式AI模型时侵犯了艺术家、作者和其他内容创作者的版权。
此外,欧盟关于人工智能的新临时规则可能会迫使公司披露用于训练模型的数据集,这可能会使他们面临更大的法律风险。

相关推荐



- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
热门文章