

 新火种
2024-12-25
新火种
2024-12-25 


超三万种材料,近百万真实材料合成表征信息,LLM精准构建材料知识图谱MKG,登NeurIPS2024

编辑 |ScienceAI
知识图谱集成多源数据信息为结构化知识,以阐明复杂科学领域的数据结构并介导研究进展、创新和应用的结构化知识交流。
为了统筹和分析分散在数以百万计的文献中的材料学知识,新南威尔士大学(UNSW)、同济大学、香港城市大学以及 GreenDynamics 律动造物,构建了材料知识图谱(MKG)。
该团队依托于大型语言模型独立设计的本体论,并自动化地提取及清洗了大量的材料学文献中的知识,构建出了丰富的知识图谱。
利用基于网络的图算法,MKG 对图中的材料、应用和描述进行评分和预测,探索潜在的缺失关系。该图包含超过十余种材料科学重要属性,十五万个节点和近百万个关系。
具体来说,该团队通过少量数据对大语言模型进行了微调,自主设计图的本体,并从数十万篇文章摘要中提取了材料学相关信息,并保留了所有信息的可追溯性。
结合自然语言处理技术,对知识进行了高质量清洗,并应用图算法和模型完成了图的完善和增强,揭示了材料学知识之间的潜在联系和机理。
通过MKG,团队预测了在电池、太阳能电池、催化剂等能源领域,未来几年可能出现的潜在材料,并为这些预测提供了强有力的解释性支持。
该研究以「Construction and Application of Materials Knowledge Graph in Multidisciplinary Materials Science via Large Language Model」为题,被机器学习顶级会议 NeurIPS 2024 接收。

论文链接:https://neurips.cc/virtual/2024/poster/95920
研究背景
材料科学的研究对现代工业的发展至关重要,尤其是在能源转换、电子设备创新、汽车制造和生物医药应用等领域。
传统上,材料研究依赖于实验室实验和长时间的经验积累,这不仅耗时而且成本高昂。此外,尽管有无数的科研文献提供丰富的理论和实验数据,但这些知识常常散落在不同的出版物和数据库中,难以迅速准确地获取和应用。
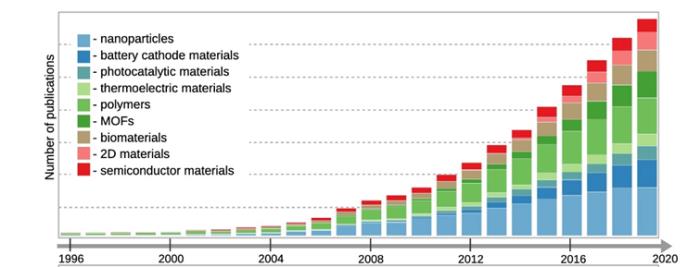
图 1:爆发式增长的材料学文献。(来源:网络)
在这种背景下,自动化的知识集成和加速研究的需求日益迫切。借助人工智能技术,研究人员开始探索如何利用这些先进工具来改善材料科学的研究方法。
知识图谱作为一种信息组织形式,能够将散落在各处的非结构化数据转换为结构化的知识库,从而提供一个全面、互联的数据网络,加快知识的检索和应用。
尽管知识图谱的潜力巨大,但其构建过程面临多重挑战。
首先,材料科学领域的复杂性要求图谱不仅要精确地反映出材料的化学和物理性质,还需要捕捉到这些性质在不同应用中的表现。
此外,材料学的快速发展也意味着知识图谱需要持续更新和扩展,这不仅依赖于领域专家的深入参与,还需要借助自动化工具以适应知识的动态变化
MKG - 材料科学知识图谱
为了解决这些问题,团队将大型语言模型引入知识图谱的构建流程,不仅可以通过自动化构建本体论,提取和分析巨量文献中的数据来构建初步的知识图谱,还可以通过持续学习来适应新的研究成果和理论发展,从而保持知识图谱的前沿性和准确性。
通过这些技术的应用,MKG 的构建和维护成为可能,极大地促进了材料科学研究的深度和广度,为科研人员提供了一个强大的工具,帮助他们更快地发现和应用新材料,推动科技创新和工业应用。
对于 MKG 的构建和应用,整个过程可以分为四个关键步骤:(1)本体论的自动构建,(2)知识的抽取,(3)知识清洗,(4)材料发现。
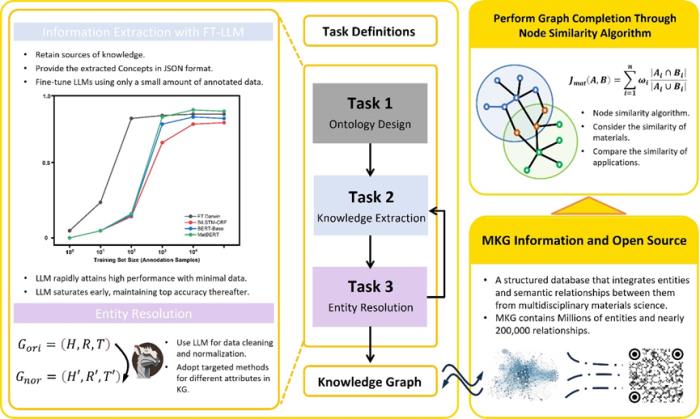
图 2:MKG 概览。(来源:论文)
(1)构建知识图谱的首要步骤是创建一个本体论,它定义了将被包含在图谱中的各种概念及其相互关系。在材料科学领域,这涉及到从基本的化学成分到复杂的物理性质和应用过程的全面覆盖。
借助大型语言模型,如 LLaMA 或Darwin,研究团队能够自动识别和分类大量文献中的关键概念和关系,从而自动化构建本体论。这一过程减少了人工干预的需要,加速了知识结构的创建,并确保了结构的一致性和可扩展性。
(2)从分散在各处的科研文献中抽取具体的数据和信息。这包括但不限于材料的合成方法、物理和化学属性、以及它们在实际应用中的表现。
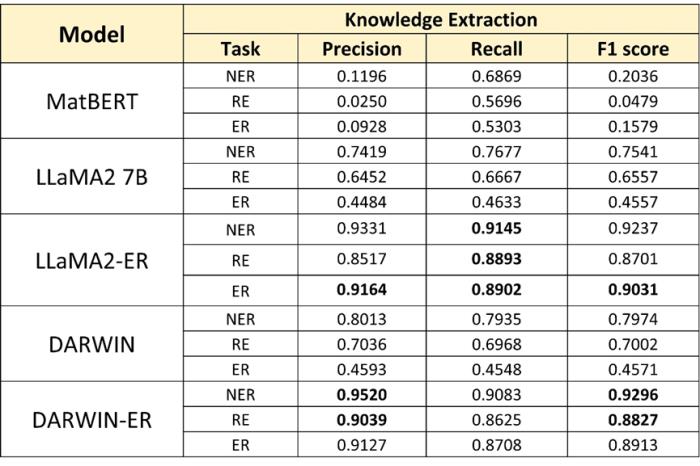
通过少量数据微调的大型语言模型能够精确地从文本中提取出这些信息,转化为结构化数据,并保留信息的出处。这一步是知识图谱构建中至关重要的,因为它直接影响到图谱的质量和后续应用的效果。
表 1:LLM 在知识抽取中 的效果。(来源:论文)
(3)抽取出的信息往往包含噪声或不一致性,因此需要进行彻底的清洗和验证。这一步骤确保了知识图谱中的数据是准确和可靠的。
清洗过程中,可能会用到各种数据清洗技术,如数据去重、格式标准化、错误更正等。此外,还需要专家进行人工审核,以解决自动化工具难以处理的复杂问题。
(4)最后一步是利用抽取和清洗后的数据来完善和增强知识图谱(图完成)。用图算法和神经网络来分析和预测材料之间的新关系,这包括增加新的实体和关系,更新图中的信息。
这不仅增强了图谱的功能,也为研究人员提供了更深入的洞见,帮助他们发现新的材料特性和应用潜力。
材料发现
通过图完成的步骤,该方法可以全局范围内识别能源材料与应用之间的潜在联系。在局部使用图神经网络,聚合特定的量化属性到特定材料的特征实体,用于嵌入训练图神经网络,并预测材料未知特征的数值。
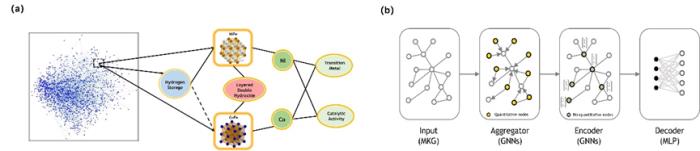
图 3:基于(a)图算法和(b)图神经网络的图完成。(来源:论文)
全局范围内的材料发现是通过基于修正后 Jaccard 相似度算法。修正后的算法不考虑不同属性的邻居实体具备不同的权重,还纳入了实体的出现时间和重要程度,更仔细的考虑不同实体的优先级。
为了验证算法的有效性,研究人员将 MKG 按照时间属性分为两个子图,分别作为训练集和验证集。
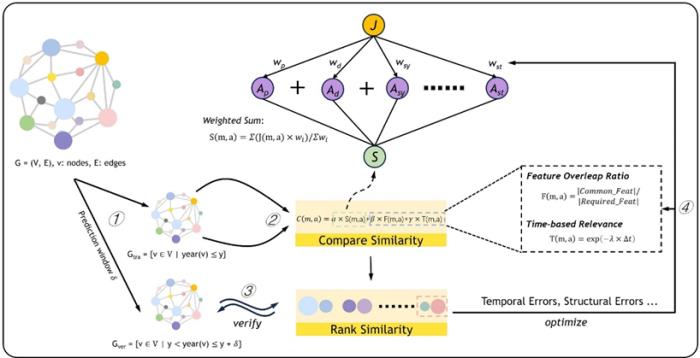
图 4:全局范围的材料发现。(来源:论文)
不难发现,随着时间的增长,训练集上的预测材料逐渐在验证集中被发现。这不但证明了算法的有效性,也验证了 MKG 的可信度。此外,团队还统计了高排名的预测被验证的概率。更多信息可以浏览全文进行了解。
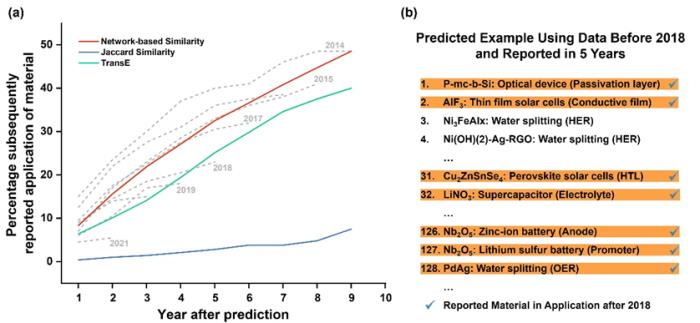
图 5:材料发现的验证结果。(来源:论文)
未来的研究方向
考虑到 MKG 在构建和应用过程中展现出的潜力,研究人员提出了几个可能的发展方向,旨在进一步拓宽材料知识图谱的应用领域并增强其实用性。
1、扩展 MKG 的覆盖范围至更多化学和材料科学的子领域,并且与其他现有的知识图谱进行整合。
2、通过将作者身份、发表年份和机构归属等属性纳入知识图谱,研究人员将分析材料再利用的历史「社交」模式。
3、分析 MKG 中的簇形成,这些簇基于材料之间的链接。理解这些簇将帮助揭示材料是如何相互连接的,这可以帮助发现不同材料之间在孤立研究中未显现的联系。
4、团队正将 AI Agent 技术集成入本体论的自动构建中,以增强知识管理与发现。本体论分为主本体和子本体:主本体覆盖广泛概念,子本体则针对特定子领域细化分类。这提高了构建的精确性,增强了适应性。
这些研究方向不仅能够扩展 MKG 的功能和应用范围,也有助于推动科学与人工智能技术的深度融合,开拓新的科研和工业应用前景。
相关推荐



- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。










