新火种
2023-09-07
新火种
2023-09-07 

出门问问发布语音识别开源框架WeNet半年势破Github1000星
来源:钥城网
2021年2月19日,出门问问联合西北工业大学联合推出全球首个面向产品和工业界的端到端语音识别开源工具 —— WeNet。自发布以来,WeNet 因其简洁性、易用性和产品优先 (Production First and Production Ready) 的定位,受到了广泛关注、使用和好评。目前,短短6个月的时间里,WeNet 已在世界最大的代码托管平台Github 上获得超过1000个 star,成为当前最流行的产品级端到端语音识别框架。
WeNet 1.0 正式发布 从横空出世到迅速流行
2020年10月,WeNet 项目在出门问问内部启动,经过3个月的内部开发于2021年2月初在 Github 发布了第一个开源版本。随后 WeNet 快速更新多项重要功能,在学术界和工业界引起了热烈反响。2021年6月,WeNet 正式发布1.0版本,其完善的功能和优秀的性能极大地赋能了众多行业的语音识别应用。
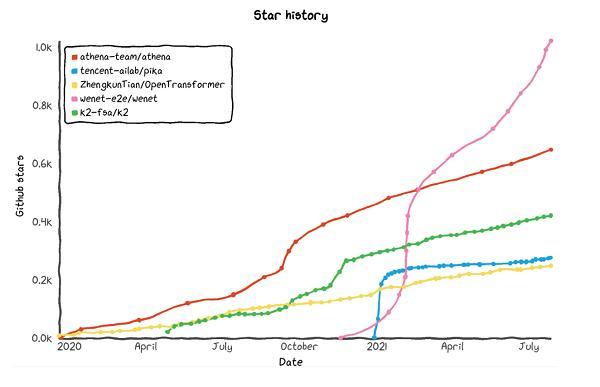
国产开源端到端语音识别框架流行度
相较于目前主流语音识别开源工具,WeNet 在研发之前就明确了几项基本原则,以指导项目的开发。
易用性:使用方便,提供一键式训练脚本、预训练模型和多平台运行时工具。
可用性:专注于 ASR 落地,提供一套适合工业场景的性能最优的训练和部署方案。
可读性:代码简明直接,减少抽象,提供详实的注释和文档,方便语音识别初学者学习。
从 WeNet 1.0 版本的功能,可以看出 WeNet 的开发团队一直坚持践行着这些基本原则,不忘初心,方得始终。
支持 Aishell-1 ,Aishell-2 ,Librispeech ,Gigaspeech ,Multi_cn 一键式脚本,提供数据量最大的中文和英文预训练模型,在 Aishell-1 ,Aishell-2 和 Gigaspeech 上准确率达到 SOTA 。
推理方案支持 Android 平台和 x86 平台,支持基于 GRPC 和 Websocket 的服务端推理和端侧推理。
支持时间戳,端点检测,长语音模式,语言模型等工业场景关键功能。
提供中英文双语文档和详尽的代码注释,WeNet 步行街 微信公众号对每个重要功能都有图文并茂的详细介绍。
WeNet“小而精” 广泛赋能各行业
WeNet 一经问世,即被广大用户誉为“产品化集成度最好的框架”。根据不完全统计,目前已有数百家公司采用 WeNet 进行语音识别产品研发,或借助 WeNet 设计思想来构建自己的语音识别系统。这其中包括几十家互联网和其他垂直行业的知名头部公司,其应用范围涵盖了智能车载、智能家居、智能客服、音频内容生产、直播、会议等大量语音识别应用场景。
出门问问内部利用 WeNet 方案,在各个真实场景上相比原系统获得了10%-30%以上的相对提升。WeNet 的用户也均反馈在各类产品中得到了同数量级的一致性提升。
西北工业大学计算机学院教授、博士生导师、音频语音与语言处理研究组(ASLP@NPU)负责人谢磊表示:和其他语音识别相关工具包“大而全”的理念不同,正如 WeNet 名字中所表达的,WeNet 是面向大众都可以快速学习和在实际应用部署的工具包,具有鲜明的“小而精”的特色。WeNet 基于SOTA 的深度学习模型架构,具备数据准备、模型训练、工程部署整条易用的链路,同时融合了面向实际应用的各种特性,比如面向领域适配增加了语言模型的支持,又如时间戳和端点检测等功能的支持等。据了解,很多高校都已经使用 WeNet 作为学习和科研工具,同时众多公司也在实际产品中应用 WeNet 作为重要部署工具。
WeNet 的出现解决了目前主流语音开源工具之痛点,且各项性能指标达到业界最优,成为世界级技术领先的开源工具。如果用简单的几个词总结 WeNet 1.0 的特性的话,那就是“更快、更高、更强、更有生产力”。
更快:WeNet 1.0 中支持了多机多卡的分布式训练,训练更快;解码时也可以做历史chunk限制,解码更快。
更高:更高的识别率。WeNet 1.0 中升级 U2 算法到 U2++,识别率更高,并支持了语言模型,进一步提高识别率。目前 WeNet 的识别准确率和速度指标均达到业界最优。
更强:更强大的功能。WeNet 完善了标准数据集的支持;支持了时间戳、n-best、对齐、endpoint 等识别强相关任务;并建立了系统的文档。
更有生产力:在 x86 server 和 on-device android的基础上,结合语言模型支持、gRPC 支持、n-best、时间戳、endpoint 等的支持,WeNet 1.0 已经构建了一个完整完善的语音识别所需的方方面面的能力,也有工业界应用的典型案例。
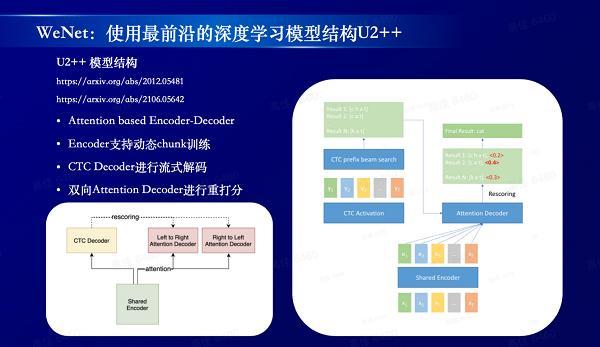
WeNet使用最前沿的深度学习模型结构U2++
WeNet开放开源 AI生态生生不息
“只有愿意以自己为基石,开放自己的资源和能力,形成的产业链和生态体系,才能够生生不息的去发展。”这也是WeNet 的团队初心。
WeNet 是由出门问问发起和主导的开源项目,同时 Wenet 能够快速发展并获得广泛的认可,离不开西北工业大学和开源社区的大力支持。
联国内顶级语音实验室
出门问问和西工大 ASLP 实验室(音频、语音与语言处理研究组)长期保持着密切合作。2015年双方合作研发了TicWatch手表上的语音合成(TTS)技术,实现了首个支持语音播报的智能手表,近期则一直联合探索端到端语音识别架构,以及最适合工业界应用落地的语音识别方案。如今 WeNet 成功用于各行业语音产品的事实已经证明,CTC + WFST + AED Rescoring 方案是目前端到端语音识别的最佳实践方案之一,而 WeNet 能够在项目一开始就找到这条正确的路,离不开 ASLP 实验室的老师同学们提供的宝贵经验和建议。
拥抱开源社区的力量
WeNet 是站在巨人肩膀上的。Espnet 提供了模型的实现方法,Pytorch 生态提供了简单高效的建模和推理框架,Essen 和 Kaldi 提供了CTC WFST 的构建和解码的实现方法。正是使用和借鉴了这些优秀开源项目,WeNet 才能在短期内支持众多的功能并提供优秀的性能。
WeNet 的开发团队中除了出门问问的工程师,也包含来自京东、网易互娱、喜马拉雅、 Bigo 、商汤科技 、声瀚科技等公司的同学,他们利用自己的业余时间帮助 WeNet 完善功能、修复 bug 、解答用户问题,为 WeNet 的发展做了巨大的贡献。
希尔贝壳和 Gigaspeech 社区则分别为 WeNet 提供了中文 Aishell-2 和英文 Gigaspeech 数据,助力 WeNet 发布了高性能的中文和英文预训练模型。
喜马拉雅团队使用 WeNet 构建了自己语音服务,并为 WeNet 项目贡献了其 grpc 版本的服务端实现。作业帮团队使用 ONNX 对 WeNet 模型进行推理优化,并将其实现方案分享给了社区。
而对 WeNet 最重要的贡献则来自于每一位 WeNet 的用户,Wenet 的微信交流群里已经有1200多名用户,他们对框架的功能和性能进行了成千上万次的验证,反馈了大量的问题、需求和建议,推动着 WeNet 的改进和成长。
正是因为开源,让 WeNet 可以有机会经受千锤百炼,在遇到问题时能及时得到八方支援,迅速成长为一个健壮的高性能的框架。
“这是一个大生态、大协同、大成长的时代,开放开源,共生协同,各得其所,是我们面向未来的态度。”目前,出门问问 WeNet 正在迅速迭代,专注语音识别,坚持 “Production First and Production Ready”,追求极致的产品力,同时也追求项目和工程上的极致。出门问问 WeNet 秉以侠之大者、为国为民,将与开发者们共同探索 AI 和中国科技的未来。
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
热门文章