新火种
2024-12-13
新火种
2024-12-13 


准确率达95%,混合深度学习搜索纳米生物材料,登Nature子刊

编辑 | 萝卜皮
超分子肽基材料具有革新纳米技术和医学等领域的巨大潜力。然而,破译其实际应用所必需的复杂序列到组装途径仍然是一项艰巨的任务。
它们的发现主要依赖于需要大量资金的经验方法,这阻碍了它们的颠覆性潜力。因此,尽管自组装肽种类繁多,且具有明显的优势,但只有少数肽材料进入了市场。
基于实验验证数据进行训练的机器学习可以快速识别具有高自组装倾向的序列,从而将资源支出集中在最有前途的候选序列上。
克罗地亚里耶卡大学 (University of Rijeka)的研究人员介绍了一个框架,该框架在基于元启发式的生成模型中实现了精确的分类器,以在具有挑战性的肽序列空间中进行搜索。
为此,该团队训练了五个循环神经网络,其中使用聚集倾向和特定物理化学性质的序列信息的混合模型取得了优异的性能,准确率为 81.9%,F1 得分为 0.865。
分子动力学模拟和实验验证已证实,生成模型在自组装肽的发现中准确率为 80-95%,优于目前最先进的模型。
该研究以「Reshaping the discovery of self-assembling peptides with generative AI guided by hybrid deep learning」为题,于 2024 年 11 月 19 日发布在《Nature Machine Intelligence》。

分子自组装(SA)是由非共价弱相互作用驱动的基本化学过程,肽作为结构多样的分子构件,能够组装成复杂的超分子材料。然而,实验发现新型自组装肽效率低、成本高,并因搜索空间庞大而受限。
分子动力学(MD)模拟和机器学习(ML)为肽设计提供了新思路,尤其是ML模型通过更快的运算和更高效的数据处理,展现了在肽自组装预测中的潜力。
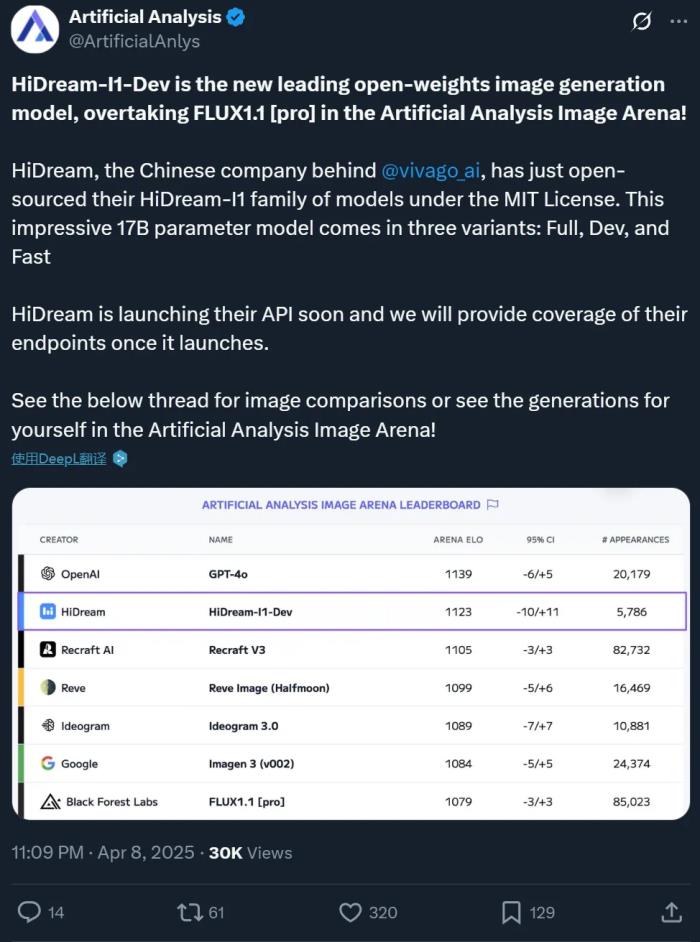
图示:拟议研究流程的概述。(来源:论文)
在最新的研究中,里耶卡大学的研究团队开发了一种基于 RNN 的方法,使用不规则采样的不等长特征来评估未分类肽的 SA 潜力,该方法基于氨基酸、二肽和三肽的 AP 分数作为任何给定目标肽的预测变量。
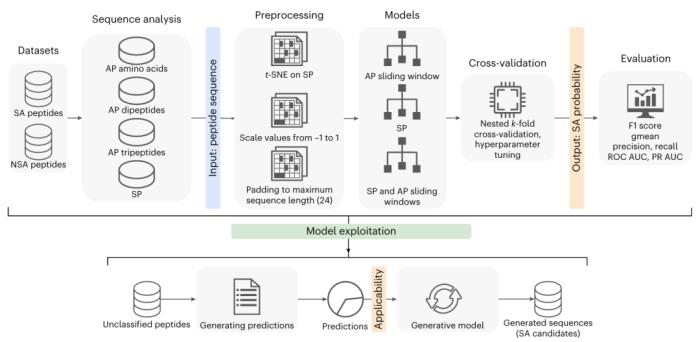
图示:从数据集到滑动窗口机制和超参数优化的神经网络设置。(来源:论文)
此外,RNN 分类器用作基于搜索的遗传算法中的适应度函数,以形成生成模型,用于发现具有高 SA 倾向的序列。该模型补充了人类的直觉,试图基于 ML 辅助的无偏序列空间探索来识别具有高 SA 倾向的新肽。
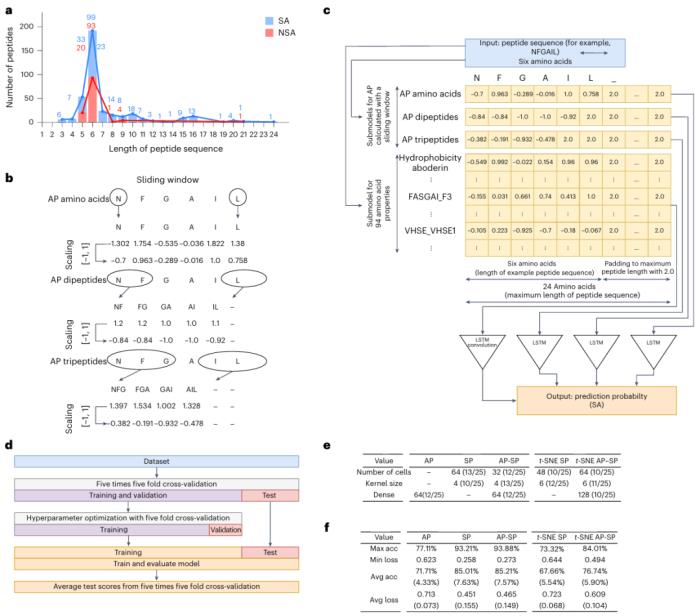
具体来说,研究人员通过改变架构、输入数据和训练参数,开发了五种基于序列到组装 RNN 的预测模型。使用通过长度为 1、2 或 3 个残基的滑动窗口获得的预先计算的 AP 分数以及特定的物理化学特性,然后用从文献中整理的实验数据对模型进行训练。这使得模型能够分析任意长度的序列,而无需使用 MD 进行大量的 AP 分数计算。
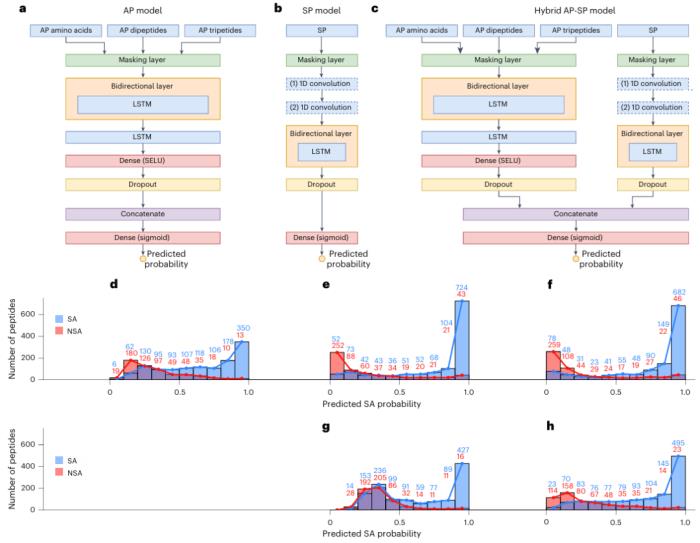
图示:RNN 架构和各种性能评估。(来源:论文)
混合 AP–SP 模型可区分 SA 和 NSA 肽,F1 得分高达 0.865,并且其将知识推广到现有数据集未探索的化学空间区域的能力已在生成模型中进行测试。使用 MD 模拟对生成的肽(十个 SA 和十个 NSA)进行验证,证实了模型精度为 90–100%。
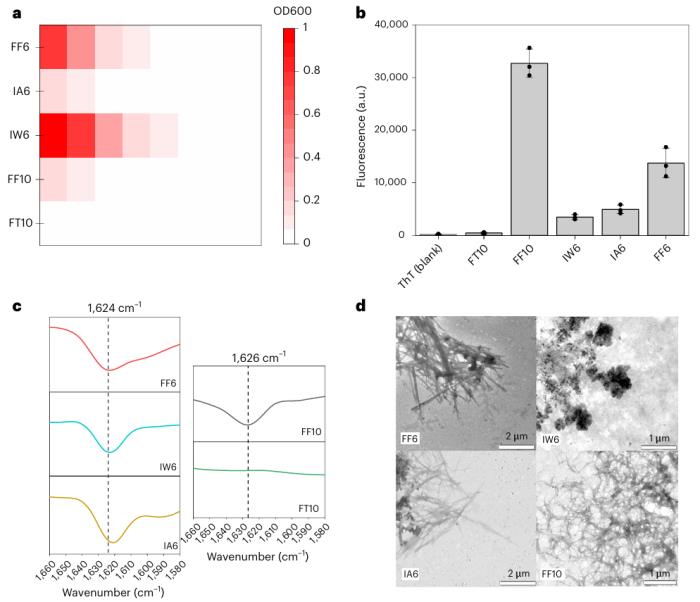
研究人员对三种六肽和两种十肽进行了真实实验验证。OD、衰减全反射 (ATR)-FTIR、ThT测定和 TEM 测量证实,五种肽中有四种发生自组装,这与 ML 引导生成模型中使用的 AP-SP 分类器 (81.9%) 的准确率一致。
因此,生成模型的表现优于人类和人工智能专家,准确率高出 25% 至 35%。鉴于现有 SA 推理方法的资源密集型特性,ML 模型可以精确定位具有 SA 高度倾向的序列,同时所需的时间和资源更少。
研究人员相信,生成模型的准确性表明,他们开发的 ML 模型成功捕获了存储在实验验证数据中的底层规则。这在发现具有高自组装概率的肽方面,提供了一种补充人类直觉的方法,并为未来智能和自动驾驶实验室的发展提供了机会,从而可以更快、更可持续地发现新材料。
论文链接:
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
热门文章