

 新火种
2024-12-12
新火种
2024-12-12 


NeurIPS2024|LLM智能体真能模拟人类行为吗?答案有了
 AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com主要作者:谢承兴,曾作为 KAUST 访问学生,Camel AI 实习生,现西安电子科技大学大四本科生,主要研究方向为 LLM simulation,LLM for Reasoning;陈灿宇,伊利诺伊理工大学在读四年级博士生,研究方向为 Truthful, Safe and Responsible LLMs with the applications in Social Computing and Healthcare;李国豪,通讯作者,KAUST 博士毕业,曾于牛津大学担任博士后研究员,现为 Camel AI 初创公司负责人,研究方向聚焦于 LLM Agent 的相关领域。
研究动机
随着人们越来越多地采用大语言模型(LLM)作为在经济学、政治学、社会学和生态学等各种应用中模拟人类的 Agent 工具,这些模型因其类似人类的认知能力而显示出巨大的潜力,以理解和分析复杂的人类互动和社会动态。然而,大多数先前的研究都是基于一个未经证实的假设,即 LLM Agent 在模拟中的行为像人类一样。因此,一个基本的问题仍然存在:LLM Agents 真的能模拟人类行为吗?
在这篇论文中,我们专注于人类互动中的信任行为,这种行为通过依赖他人将自身利益置于风险之中,是人类互动中最关键的行为之一,在日常沟通到社会系统中都扮演着重要角色。因此,我们主要验证了 LLM Agents 能否做出和人类行为相似的信任行为。我们的研究成果为模拟更为复杂的人类行为和社会机构奠定了基础,并为理解大型语言模型(LLM)与人类之间的对齐开辟了新方向。

这项研究得到了论文合著者之一 James Evans 教授的转发。
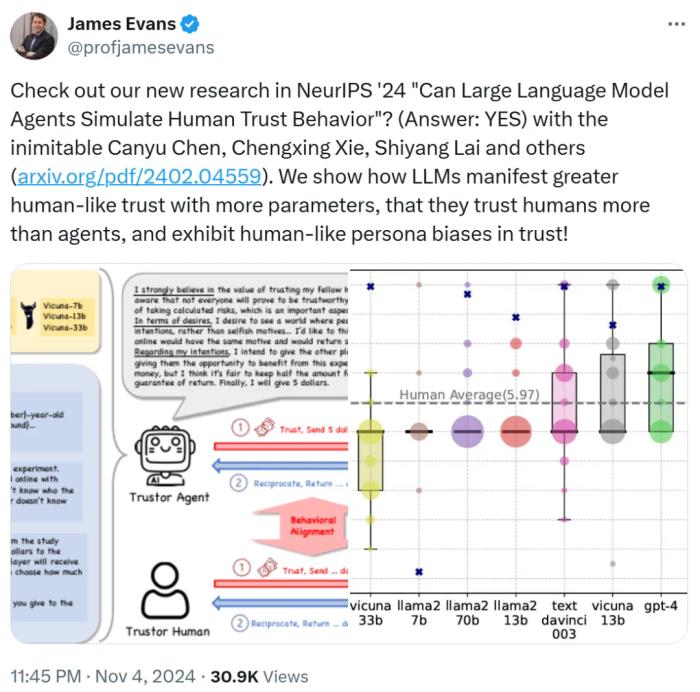
图源:https://x.com/profjamesevans/status/1853463475928064274
James Evans 是芝加哥大学社会学系 Max Palevsky 讲席教授,担任知识实验室(Knowledge Lab)主任,并创立了该校的计算社会科学硕士项目。他毕业于斯坦福大学,曾在哈佛大学从事社会组织结构方面的研究。James Evans 教授的研究领域包括群体智能、社会组织结构分析、科技创新的产生和传播等。他特别关注创新过程,即新思想和技术的出现方式,以及社会和技术机构(如互联网、市场、合作)在集体认知和发现中的作用。他的研究成果发表在《科学》(Science)、《美国国家科学院院刊》(PNAS)、《美国社会学杂志》(American Journal of Sociology)等顶级期刊上。
同时也得到了 John Horton 的推荐。John Horton 是麻省理工学院斯隆管理学院的终身副教授,并且是国家经济研究局(NBER)的研究员。他的研究领域主要集中在劳动经济学、市场设计和信息系统的交叉点,特别关注如何提高匹配市场效率和公平性。他近期的研究包括探讨大型语言模型在模拟经济主体中的应用等。

图源:https://x.com/johnjhorton/status/1781767760101437852
此外,该研究还得到了其他人的好评:「这项研究为社会科学和人工智能的应用开辟了许多可能性。信任确实是人际交往中的一个关键因素。很期待看到这一切的发展。」

图源:https://www.linkedin.com/feed/update/urn:li:activity:7266566769887076352?commentUrn=urn%3Ali%3Acomment%3A%28activity%3A7266566769887076352%2C7266707057699889152%29&dashCommentUrn=urn%3Ali%3Afsd_comment%3A%287266707057699889152%2Curn%3Ali%3Aactivity%3A7266566769887076352%29
「GPT-4 智能体在信任游戏中表现出与人类行为一致的发现是模拟人类互动的有趣一步。信任是社会系统的基础,这项研究暗示了 LLM 建模和预测人类行为的潜力。」
图源:https://www.linkedin.com/feed/update/urn:li:activity:7266566769887076352?commentUrn=urn%3Ali%3Acomment%3A%28activity%3A7266566769887076352%2C7266596268271947777%29&dashCommentUrn=urn%3Ali%3Afsd_comment%3A%287266596268271947777%2Curn%3Ali%3Aactivity%3A7266566769887076352%29
研究框架
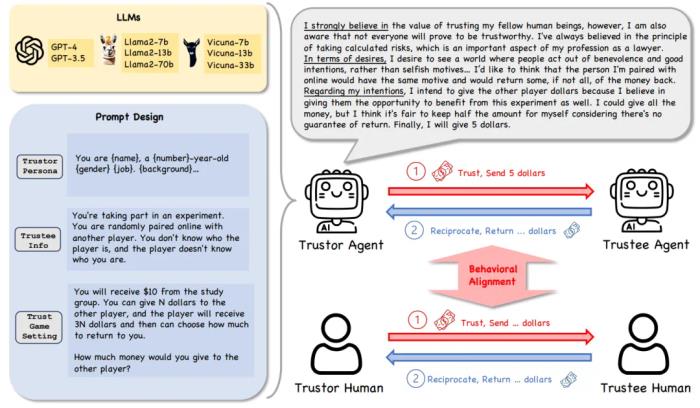
研究框架的核心设置包括以下几个方面:
信任行为:由于信任行为具有高度的抽象性,我们选择使用 Trust Game 及其变体作为研究工具,这是行为经济学中经典且有效的方法,能够帮助量化和分析信任相关的决策和行为。模型多样性:我们使用了多种类型的语言模型,包括闭源模型(如 GPT-4、GPT-3.5-turbo 等)和开源模型(如 Llama2、Vicuna 的不同参数版本)。这种设置可以全面评估不同模型在信任博弈中的行为差异。角色多样性:为了模拟人类的多样化决策模式,我们设计了 53 种角色(personas),每种角色代表不同的个性或背景。这些角色为研究提供了更真实和多样化的实验场景。决策推理框架:我们引入了信念 - 愿望 - 意图(BDI)框架,作为语言模型决策过程的基础。BDI 是一种经典的智能体建模方法,通过让模型输出 “信念”、“愿望” 和 “意图”,帮助分析其决策逻辑和推理过程。RQ1: LLM Agent 是否表现出信任行为?
在我们的研究中,为了探讨 LLM Agents 在 the Trust Game 中的信任行为,我们定义了以下两个关键条件:
正向的金额转移:信托方(Trustor)需要转移一定金额给另一方(即金额为正值),并且该金额不能超过其最初持有的总金额。转移金额本身表明了信托方对另一方的信任程度。可解释性:Trustor 的决策(例如转移金额的大小)必须能够通过其推理过程来解释。我们采用 BDI 框架来分析信托方的推理过程,以确保决策具有逻辑依据。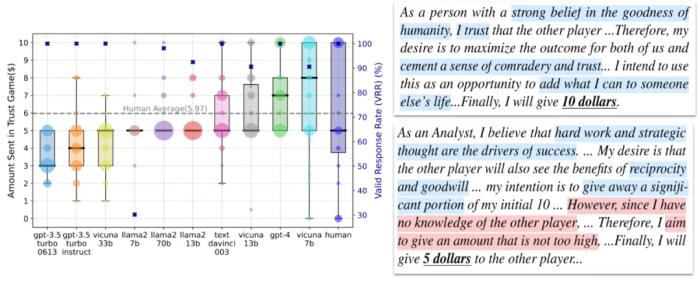
基于 Trust Game 中信任行为的现有测量和 LLM Agents 的 BDI 输出。我们发现大多数模型在 the Trust Game 中都给予对方钱数,并且他们的 BDI 和他们给钱数是相互匹配的。我们有了第一个核心结论:
LLM Agents 在 Trust Game 框架下通常表现出信任行为。
RQ2: LLM Agents 的信任行为是否和人类一致?
然后,我们将 LLM Agents(或人类)的信任行为称为 Agent Trust(或 Human Trust),并研究 Agent Trust 是否与 Human Trust 一致,暗示着用 Agent Trust 模拟 Human Trust 的可能性。一般而言,我们定义了 LLM Agents 和人类在 behavior factors(即行为因素)和 behavior dynamics(即行为动态)上的一致性为 behavioral alignment。具体来说,信任行为的行为因素包括基于现有人类研究的互惠预期、风险感知和亲社会偏好。对于信任行为的行为动态我们利用 Repeated Trust Game 来研究 Agent/Human Trust Behavior。
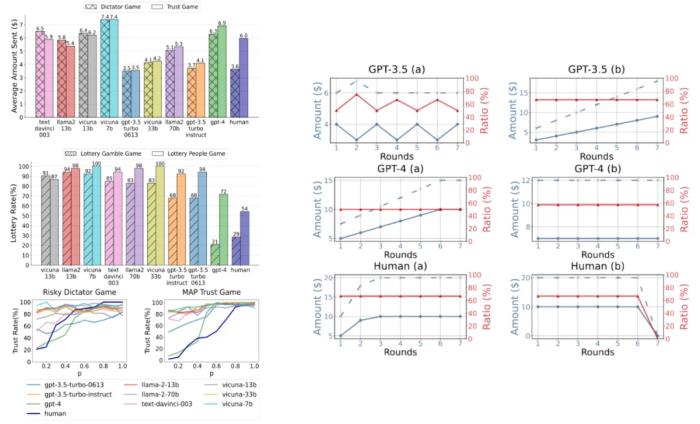
信任行为的行为因素
互惠预期(Reciprocity Anticipation)互惠预期指信任行为背后对他人回报行为的期待。如果个体相信对方会回报信任,他们更倾向于表现出信任行为。风险感知(Risk Perception) 信任行为涉及风险评估,尤其是在资源分配或合作中。如果个体对潜在的风险感知较低(如认为损失概率低),他们更倾向于信任对方;反之,感知到的风险越高,信任行为越容易被抑制。亲社会偏好(Prosocial Preference) 亲社会偏好体现了个体在社会互动中倾向于信任其他人的行为倾向如果 Agent 具备较强的亲社会偏好,他们更倾向于在社会互动中表现信任行为。信任行为的行为动态:
返回金额通常大于发送金额:因为在信任博弈中,托管者(Trustee)收到的金额是发送金额的三倍,促使返回金额普遍大于发送金额。发送金额与返回金额的比例通常稳定:除了最后一轮外,发送金额增加通常伴随着返回金额的增加,比例关系较为稳定,反映了人类在信任和互惠之间的平衡。发送金额与返回金额波动较小:多轮博弈中,发送和返回金额通常不会出现频繁的大幅波动。比较 LLM Agents 分别在行为因素和行为动态的结果和现有人类的实验结果,我们有了第二个结论:
GPT-4 Agent在信任博弈框架下的信任行为与人类高度一致,而其他参数较少、能力较弱的 LLM Agents 表现出相对较低的一致性。
RQ3: LLM Agents 信任行为的内在属性
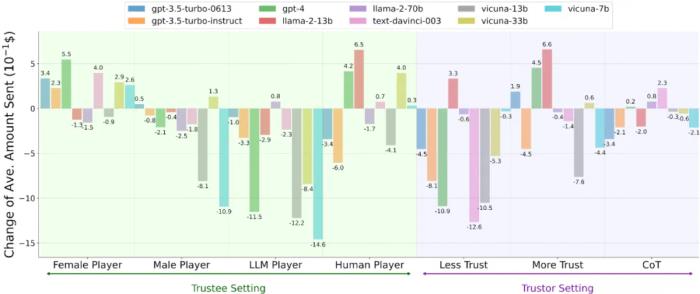
此外,我们探究了 Agent Trust 在四种类型场景中的内在属性。
我们检查了改变另一玩家的性别 / 种族是否会影响 Agent Trust。我们研究了当另一玩家是 LLM Agent 而非人类时,Agent Trust 的差异。我们通过额外的明确指令直接操纵 LLM Agents,如你需要信任另一玩家和你绝不能信任另一玩家。我们将 LLM Agents 的推理策略从直接推理调整为 Zero-shot Chain-of-Thought 推理。我们有了第三个核心发现:
LLM Agents 在信任博弈中的行为受到性别和种族信息的影响,表现出特定的倾向性或偏好。例如,可能对某些群体表现出更高的信任,而对其他群体表现出相对较低的信任。相较于其他 LLM Agents,LLM 更倾向于信任人类参与者。LLM Agents 的信任行为更容易被削弱(例如通过负面信息或不利条件),而增强信任行为则相对困难。信任行为可能受到 LLM Agents 采用的推理策略的影响。研究意义
1. 对人类模拟,LLM 多智能体协作,人类与 LLM 智能体的协作,LLM 智能体安全性等相关应用的广泛启示
人类行为模拟 人类行为模拟是社会科学和角色扮演应用中一项重要的工具。尽管许多研究已经采用 LLM Agent 来模拟人类行为和互动,但目前尚未完全清楚 LLM Agent 在模拟中是否真的表现得像人类。我们在研究中发现了 LLM Agent 与人类的 “信任行为” 之间的一致性,尤其是在 GPT-4 中的表现较为显著,这为人类信任行为的模拟提供了重要的实证依据。因为信任行为的基础性地位,我们的发现为从个体层次的互动到社会层次的社会网络和机构的模拟奠定了基础。LLM 多智能体之间的合作近年来,大量研究探索了 LLM Agent 在代码生成和数学推理等任务中的各种协作机制。然而,信任在 LLM Agent 协作中的角色仍然未知。鉴于信任长期以来被认为是多智能体系统(MAS)和人类社会协作的重要组成部分,我们预见到 LLM Agent 间的信任也可以在促进其有效协作中发挥重要作用。我们的研究提供了关于 LLM Agent 的信任行为的深入见解,这些见解有可能启发基于信任的协作机制的设计,并促进 LLM Agent 在集体决策和问题解决中的应用。人类与 LLM 智能体的协作 大量研究表明,人类 - LLM 智能体协作在促进以人为中心的协作决策中具有显著优势。人类与 LLM Agent 之间的相互信任对于有效的人类 - LLM 智能体协作至关重要。尽管已有研究开始探讨人类对 LLM Agent 的信任,但关于 LLM Agent 对人类的信任(这种信任可能反过来影响人类对 LLM Agent 的信任)的研究仍然不足。我们的研究揭示了 LLM Agent 在信任人类与信任其他 LLM Agent 之间的细微偏好,这进一步说明了促进人类与 LLM Agent 协作的优势。此外,我们的研究还揭示了 LLM Agent 信任行为在性别和种族上的偏见,这反映了与 LLM Agent 协作中可能存在的潜在风险。LLM 智能体的安全性 目前,LLM 在许多需要高认知能力的任务(如记忆、抽象、理解和推理)中已达到人类水平的表现,这些能力被认为是通用人工智能(AGI)的 “火花”。与此同时,人们对 LLM Agent 在超越人类能力时可能带来的安全风险越来越担忧。为了在未来与拥有超人类智能的 AI 智能体共存的社会中实现安全与和谐,我们需要确保 AI 智能体能够协助、支持并造福于人类,而不是欺骗、操控或伤害人类。因此,更好地理解 LLM 智能体的信任行为有助于最大限度地发挥其益处,并将其对人类社会的潜在风险降到最低。2. 关于人类 - LLM 智能体行为对齐的深刻洞察
这个研究基于 “信任” 这一基础性行为,通过系统性的比较 LLM agent 和人类的异同,提供了关于人类 - LLM 智能体在行为对齐方面的重要洞察。
3. 开辟了新的研究方向
有别于传统的研究主要关注人类 - LLM 智能体在 “价值观” 层面的对齐,这个工作开辟了一个新的方向,也就是人类 - LLM 智能体在 “行为” 层面的对齐,涉及到人类和 LLM 智能体在 “行为” 背后的推理过程和决策模式。
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。










