新火种
2024-12-04
新火种
2024-12-04 


VBench直接干到了第一!这一次,视频生成「压番」全场的是家央企
高难度武打视频,也能「手拿把掐」。
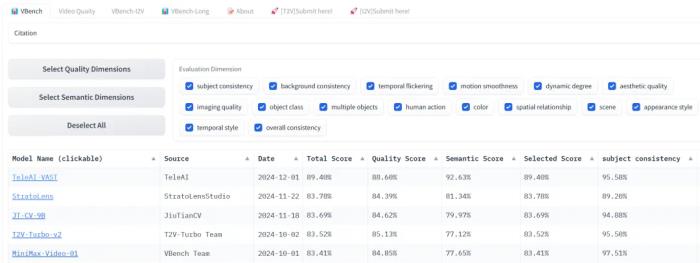
回想起来,年初对国内文生视频技术迭代速度的预估还是保守了。OpenAI 在 2 月发布 Sora 后,至今还是期货,但国内科技界迅速跟进,几乎月月有战报。字节 3 月底就端出「即梦」,3-6 秒的小视频随心所欲地玩。生数科技 4 月底放出 Vidu 模型,硬刚 Sora。快手 6 月祭出「可灵」,又把 AI 吃播玩出新水平。9月,字节又有新动作。腾讯「混元」姗姗来迟,还搞了个开源。没想到的是,眼瞅着 2024 快要翻篇了,赛道里居然又挤进一位大牌选手,身份还有些特殊。央企、也是三大运营商之一:中国电信。凭借全自研技术、海量数据和万卡 「家底」 ,中国电信人工智能研究院(以下简称 TeleAI )发布了视频生成大模型。继星辰语义大模型、星辰语音大模型之后,TeleAI 再次展示了中国电信在大模型领域与科技巨头同台竞技的雄心。这家 7 月才挂牌的研究院,正携手中电信人工智能科技有限公司用一个个创新,重新定义传统运营商在 AI 时代的角色。这个视频生成大模型有多能打?作为 12 月 1 日最新上榜的模型,它在 VBench 上直接干到了第一,大幅领先第二名。VBench 是一个全面的「视频生成模型的评测框架」,它将「视频生成质量」细分为 16 个评分维度,从人物形象一致性、动作流畅度、画面稳定性到空间关系等方面对模型进行细致、客观的评估。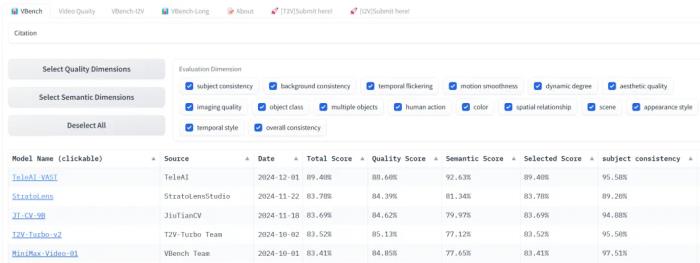
TeleAI-VAST在VBench榜单上表现亮眼。
项目链接:https://huggingface.co/spaces/Vchitect/VBench_Leaderboard
TeleAI 视频生成大模型在 VBench 的 16 个评分项目中,一举夺得 9 项第一,覆盖了模型最核心的几个能力。如,画面稳定性(时序闪烁)、语义一致性(物体分类、多物体、人体动作)、空间场景(空间关系、场景),以及视觉风格(颜色、外观、时序风格)。其中,有 5 项得分超过 99%,更有两项——物体分类和人体动作——拿了满分 100% 。模型的语义表达能力尤其亮眼。以 92.63% 的总分领先第二名整整 11 个百分点,几乎横扫了所有相关指标第一名,从语义一致性、多物体生成到空间场景把控,都展现出超出同侪的专业水准。视频质量同样出色,以 88.60% 的总分独占鳌头。无论是画面稳定性、时序连贯性,还是视觉风格的把控,均表现不俗。
这么看,不管是「理解视频」还是「做视频」,这模型都挺全面,成功超越Runway Gen-3、可灵、Vidu、MiniMax-Video-01、Pika 等一众劲敌。它算是把物理玩明白了作为中国电信 2024 年数字科技生态大会的重要环节,今天的 TeleAI 开发者大会展示了一段令人印象深刻的 AI 视频。
这段 3 分钟的视频不仅能从容驾驭 4 个主角,还能流畅切换多个场景。

提示词:An overhead view of a parrot flying through a verdant Costa Rica jungle, then landing on a tree branch to eat a piece of fruit with a group of monkeys. Golden hour, 35mm film.
而随着视频时长延长、主体数量增加,一致性难度会呈指数级上升。但从 VBench 评测榜单可见,TeleAI 的模型在主体一致性(subject consistency)方面表现出色,对付这一技术难点自然有一手。
从大会展示的视频效果看,四位女主角在多场景切换中保持了高度的形象稳定性,也印证了这一点。



下面两个视频展示了视频生成大模型在多场景连续性上的实力。
从公交车、大街,再到酒吧和餐厅,目标主体的外观始终保持一致:面部特征(包括佩戴墨镜)、服装、发型都很稳定,没有出现不连贯的情况。
从坐在教室听课的学生到穿学士服领毕业证,服装、造型随着场景在变,但一眼就能认出「这就是那个姑娘」。

更值得注意的是,凭借强大的语义表达能力,模型还展现出了类似 Sora 的镜头调度能力。
它能在一个视频中创建多个镜头,并准确保留角色特征和视觉风格。这种多镜头叙事的手法让画面具有了强烈的电影叙事感。

这段 AI演练视频也展现了令人印象深刻的多镜头叙事。
一会儿在天上俯拍,把整个舰队尽收眼底;一会儿从航母甲板上,特写舰载机起飞的瞬间。还有从摄影船上水平拍摄、空中跟拍,甚至水下拍摄。
一套「组合拳」打下来,确实玩出了大片的味道。
事实上,与目前 Sora 生成的默片相比,这个 AI 演练作品还有一个更胜一筹的地方。
Sora 虽然在画面生成上表现出色,但缺少声音确实削弱了视频的感染力。TeleAI 视频生成大模型在这方面实现了突破,能够同步生成与画面完美契合的音频效果。
不过,当前的视频大模型除了要应对目标一致性的挑战,还面临着一个更基础的问题:对物理规律和常识的理解还很肤浅。这导致它们经常翻车。
人在跑步机上莫名其妙地倒着跑。

体育视频更是重灾区。体操运动员四肢横飞、身体扭曲、与单杠、垫子的交互完全脱离物理法则,场面非常恐怖。

TeleAI 视频生成大模型在遵循物理和常识方面展现出突出实力,在 VBench 测试中的人体动作和物体分类两项指标都拿下了满分。
就说这个跳水片段。人物从悬崖边腾空到入水的整个过程,动作姿态流畅自然,符合物理定律,也没有 AI 生成常见的扭曲变形。悬崖边的浪花效果也很逼真。
TeleAI 开发者大会秀出的视频中,女主跃入大海时,肢体没有横飞和扭曲。
跳水还只是单人项目,再看这段打戏,难度可就更大了。
一个是动作要协调。两个人打起来,一个出拳另一个要躲,动作配合要天衣无缝。其次,距离感也得把握好,打近了怕穿模,太远又显得够不着。
这段视频展现了 AI 在多主体互动场景中的出色表现。
武器碰撞、进攻防守都很到位,真假美猴王和武器也没有穿模,打斗场面比较自然流畅。即使在高速运动中,美猴王的外貌、服装和武器也没走样。
回看此前的 AI 演练视频,模型在多主体场景的物理模拟方面同样表现出色。
无论是空中编队飞行,还是多个主体的动态位置和姿态,都保持了合理的空间关系,避免了穿模问题。
火焰和烟雾的形态与扩散过程,也都严格遵循物理规律,呈现出真实可信的视觉效果。

而这个摘头盔的片段,特别能说明大模型处理复杂动作序列时的能力。
人的手指与头盔的交互准确自然,摘头盔时头发的晃动效果逼真,整个动作序列显得连贯流畅。画面中没有出现「六指」或手指穿模等常见缺陷。
场景的远近层次感也处理得当。远处的火山爆发场景自然虚化,而近处的人物保持清晰,使整个画面看起来层次分明又不显呆板。
应用为王:从视频到短剧平台TeleAI 在保持目标主体一致性和还原真实世界细节方面的突破性进展,可不仅仅是为了玩视频生成,他们盯上了一块更大的蛋糕:AI 短剧市场。
短剧近年来太火,打开 App Store ,榜首基本被短剧应用霸占。用户就爱这种几分钟的「快餐」,剧情快,看着过瘾。
要说市场规模,去年短剧就已经到了 373.9 亿,比前年暴增 267.65% 。这数字已经顶得上电影票房的七成了。今年预计还要突破 500 亿,直逼电影市场。

周星驰出品的《金猪玉叶》6月在抖音上线,短短几天播放量就冲破3000万,这部剧总共24集,每集也就5分钟左右,整个拍摄周期才用了13天。
目前已有创作者使用 AI 制作短视频,一些作品播放量轻松突破百万。业内普遍看好视频生成在中国的发展前景,认为 AI 将为短视频产业,特别是短剧行业带来重大机遇。
不过,要说用 AI 拍完整短剧,还有不少坑要填。短剧制作很复杂,要搞定剧本、人物、视频、音频,最后还得串成完整的故事。现在创作者得在各种 AI 工具间倒腾,连 Sora 都做不到「一条龙」服务。
TeleAI 在这件事上拿出了态度:
他们已经完成了语义、语音、视觉、多模态等技术的全模态布局,目标是将这些能力整合,实现用户输入故事构思即可「一键生成」短剧的愿景。
在具体实现上,他们的星辰大模型可将创意构思转化为成熟剧本,通过文生图技术塑造人物形象,根据剧本生成分镜图,最后基于这些素材生成外观统一、情节连贯的视频片段,最终合成完整短剧。
就拿这个视频模型来说,为了做短剧,TeleAI 没跟着 Sora 走一样的路,而是另起炉灶,全自研了二阶段视频生成技术 VAST。
通过两阶段生成框架——先画分镜,再生成视频,这项关键技术显著提升了短剧创作过程的可控性。
说得更具体一些。
第一阶段就像导演画分镜,借助多模态大模型和自回归技术,将文字描述转换成一系列分镜头。这些「分镜」包含了人物姿势、场景分布、远近关系等关键信息,相当于给后面的视频生成打好了草稿。
第二阶段如同真实拍摄,让扩散模型根据这些「分镜」开始生成视频画面。通过将「分镜」作为条件输入,并结合文本描述和目标主体的外观特征,生成能够精准控制主体位置、动作和外观的视频内容。
比如短剧的一场打戏,大模型会先规划出完整的动作编排:从出手角度、躲闪走位到环境互动,都在分镜中预先设定。
当系统生成实际画面时,就能严格按照这份草稿来呈现,确保每个出招防守都准确到位,武打场面既符合物理规律,又富有观赏性。

实现对复杂动作的精确控制
TeleAI 视频生成大模型的进化仍在加速。它的下一步规划令人期待:多目标控制、镜头运动、3D 渲染全面升级。而这一切,都将在即将到来的一站式 AI 短剧平台中实现。
想象一下:一个创意、一台电脑,就能完成从剧本创作到视频生成的全流程。当 Sora 还在实验室里磨练时,为什么不先来尝试已经触手可及的创作利器?
对于每个怀揣故事梦想的创作者来说,TeleAI 正在让「一个人拍一部剧」成为现实。这扇通向 AI 短剧时代的大门已经打开,而你,准备好成为下一个创作先锋了吗?
相关推荐



- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。