

 新火种
2024-12-01
新火种
2024-12-01 


清华新VLA框架加速破解具身智能止步实验室“魔咒”,LLM内存开销平均降低4-6倍。
计算、存储消耗高,机器人使用多模态模型的障碍被解决了!
来自清华大学的研究者们设计了DeeR-VLA框架,一种适用于VLA的“动态推理”框架,能将LLM部分的相关计算、内存开销平均降低4-6倍。
(VLA:视觉-语言-动作模型,代表一类用于处理多模态输入的模型)

简单来说,DeeR-VLA就像人的决策系统:简单任务快速思考,复杂任务仔细思考。通过多出口架构,模型在足够计算后即可提前“刹车”,避免浪费算力。
在CALVIN机器人操作基准测试中,DeeR-VLA实现了大语言模型(LLM)计算成本减少5.2-6.5倍,GPU内存减少2-6倍,同时保持了性能不受影响。
 大模型存在冗余性
大模型存在冗余性近年来,多模态大语言模型(MLLM)让机器人具备了前所未有的理解与执行能力。通过语言指令和视觉信息的结合,机器人可以完成复杂任务,比如“抓起蓝色物体并放到桌上”。
一些前沿模型,如RT-2,甚至可以泛化到新任务或新物体。然而,要让这些强大的模型走进实际场景,还有一道难题需要解决——MLLM虽然聪明,但也“贪吃”。
这对于嵌入式机器人平台来说是致命的——GPU内存不足、计算时间长、电池续航不够,直接让“通用机器人”的梦想止步于实验室。
然而实际上,在机器人控制领域,很多实际应用场景并没有我们想象的那么复杂。
论文作者通过观察发现,绝大多数任务实际上可以通过较小的模型就能完成,只有在面对少数复杂场景时,才需要调用完整的大型多模态模型。
以Calvin数据集为例的实验结果便充分体现了这一点:当使用24层的OpenFlamingo作为基座模型时,相比于6层的模型,任务完成率仅提高了3.2%,但计算成本却增加了整整4倍。
这无疑凸显了现有的多模态大模型对大部分简单机器人任务的冗余性。

这一发现引发了对现有模型设计的深刻思考:
在很多情况下,使用更大的模型不仅没有带来明显的性能提升,反而浪费了宝贵的计算资源。
作者认为,如何根据任务的复杂性动态调整模型的规模,才能在不牺牲性能的情况下,最大化计算效率,成为了提升机器人智能的关键。
 DeeR-VLA的设计
DeeR-VLA的设计DeeR-VLA框架的核心在于其灵活的动态推理机制,能够根据任务复杂度智能调节LLM的计算深度。
这意味着,DeeR-VLA能够在不同场景中激活任意规模的模型。
为了实现这一目标,DeeR-VLA引入了多出口架构,该架构能在多模态大语言模型中按需选择性激活不同的层级。
以下是其关键技术组件:
多出口MLLM结构: DeeR-VLA通过在MLLM中引入多出口架构,将模型划分为多个阶段,每个阶段都可以输出中间结果。一旦任务复杂度达到某个出口的需求,模型就会提前停止计算,避免激活更多层级。特征池化方法: 每个出口的中间特征通过特征池化技术进行压缩,提取出最核心的信息。这种方法确保即便在早期退出,模型也能生成适用于后续动作预测的高质量特征。动作预测头设计: 在每个出口后,模型通过轻量级的动作预测头,将特征转化为机器人具体的执行动作(如机械臂的位置和夹爪的开合状态)。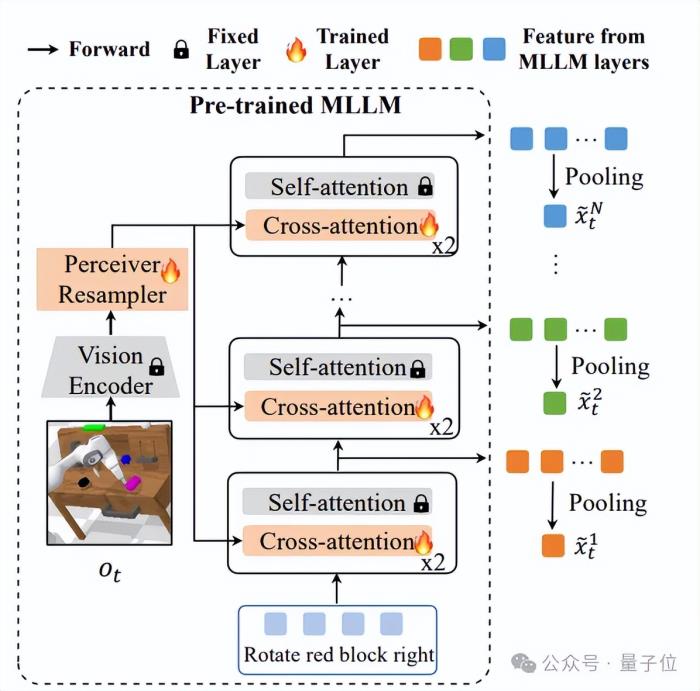
DeeR-VLA使用了一种独特的动作一致性准则来决定是否提前退出。
通过对比相邻出口的动作预测结果,若结果差异小于阈值,则推断模型已经达到收敛状态,无需进一步计算。
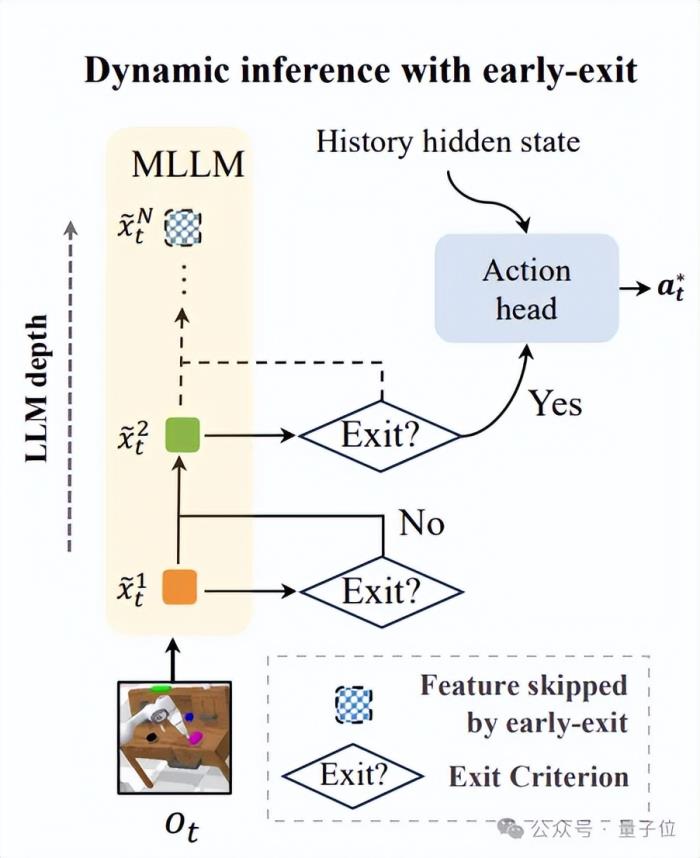
动作一致性的阈值无需手动设置,模型可以自动计算出合适的阈值来满足给定的设定平均计算成本、峰值计算、显存预算,动态调整计算规模,以适应不同的硬件环境和实时性需求。
为了自动寻找最佳退出阈值,DeeR-VLA还引入了贝叶斯优化方法。在训练或实际应用中,该方法通过探索和反馈不断微调退出策略,确保计算资源的最优分配。

在DeeR-VLA中,动态推理时,模型根据确定性的标准在每个时间步选择合适的出口,并汇集时序上每一个时刻的特征生成最终的预测。
然而,在训练阶段,由于缺乏明确的终止标准,模型并不清楚时序上出口特征的分布,这导致训练时的行为与推理时有所不同。
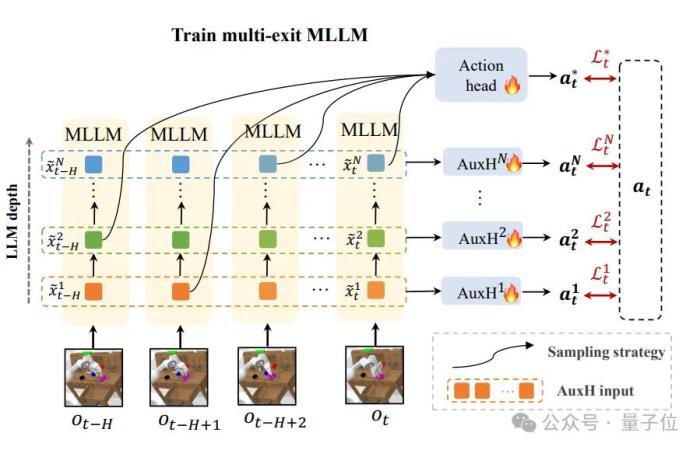
为了解决这一问题,DeeR-VLA引入了随机出口采样策略。
在训练过程中,模型在每个时间步随机选择一个出口进行计算,这样可以确保模型在所有出口序列上都能进行有效学习,并生成高质量的预测。
这种策略有效减少了训练和推理之间的分布差异,使得模型能够更好地应对动态推理过程中的不确定性。
此外,论文作者还引入了辅助预测头(Auxiliary Heads)作为额外的监督信号,对每个出口的特征进行优化,使其更适合于动作预测任务。
 实验验证
实验验证DeeR-VLA框架在CALVIN长Horizon多任务语言控制挑战(LH-MTLC)基准上进行评估。该基准目的是测试机器人在自然语言指令下执行任务序列的能力,其中每个任务序列包含五个子任务。
由于多模态大模型中LLM部分占据主要的参数量,DeeR-VLA主要关注LLM部分的计算量和显存占用,而不是整体框架的节省。
通过在不同环境设置下的测试,DeeR-VLA展现了出色的表现,尤其是在任务成功率与计算效率之间的平衡。
与其他SOTA方法相比,DeeR-VLA在任务成功率上保持竞争力的同时,LLM部分的计算资源消耗大幅减少。
例如,在D→D设置下,DeeR-VLA以更少的计算量(5.9倍减少的FLOPs)和2倍更低的GPU内存消耗,依然达到了RoboFlamingo++的性能。
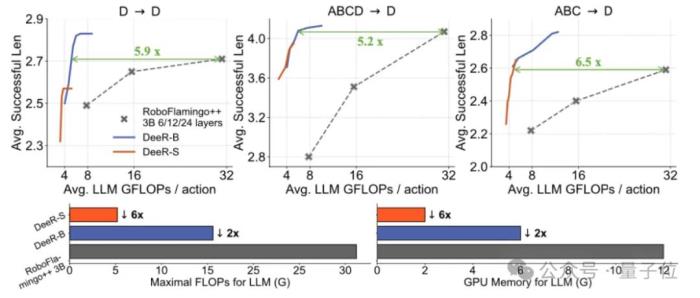
为了验证DeeR-VLA在实际推理中的效率,研究团队在Nvidia V100 GPU上对DeeR和RoboFlamingo++进行了比较。
结果表明,DeeR-VLA的LLM部分的推理时间比RoboFlamingo++减少了68.1%,且两者在任务成功率上几乎相同。
这一实验证明了DeeR-VLA框架不仅在理论上能够减少计算负担,而且在实际应用中也能显著提升推理速度。
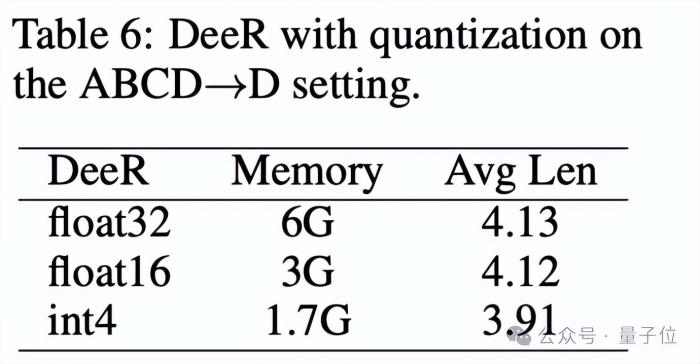
同时,DeeR-VLA框架能够与量化技术相结合,进一步减少模型LLM部分的内存使用。
 论文作者介绍
论文作者介绍该论文的一作是清华大学自动化系三年级博士生Yue Yang,他专注于强化学习、世界模型、多模态大模型和具身智能的研究。
此前他作为核心作者的论文《How Far is Video Generation from World Model: A Physical Law Perspective》被国内外众多大佬Yan Lecun,xie saining,Kevin Murphy等转发。
另一位一作王语霖同样是清华大学的博士生。两位作者的导师都是黄高。
论文作者主页:https://yueyang130.github.io/论文链接:https://arxiv.org/abs/2411.02359v1代码和模型链接:https://github.com/yueyang130/DeeR-VLA
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。









