

 新火种
2024-11-28
新火种
2024-11-28 


数研所、央行金融科技研究院专利:通过对应领域大模型,生成软件测试数据
11月8日,中国人民银行数字货币研究所、深圳金融科技研究院(中国人民银行金融科技研究院)一项名为“一种测试数据的生成方法和装置”的发明专利授权公告。其申请于2023年11月16日,涉及人工智能技术领域。
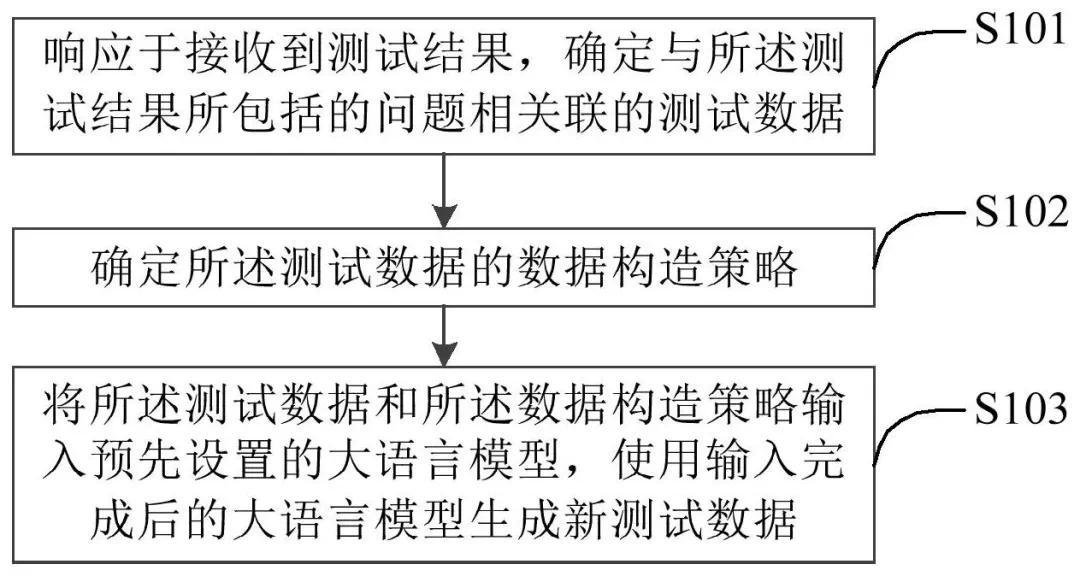
方法包括:响应于接收到测试结果,确定与测试结果所包括的问题相关联的测试数据;确定测试数据的数据构造策略(步骤A,下有详述);将测试数据和数据构造策略输入预先设置的大语言模型(步骤B,下有详述),使用输入完成后的大语言模型生成新测试数据。

而在接收到测试结果之前,需要:响应于接收到样例数据,确定样例数据的数据构造策略,将样例数据和样例数据的数据构造策略输入大语言模型,使用大语言模型生成初始测试数据;使用初始测试数据对待测试系统进行测试,得到测试结果。
更具体的,确定测试数据的数据构造策略(步骤A),包括:从预先设置的数据构造策略集中筛选出与测试数据匹配的目标数据构造策略。而在将测试数据和数据构造策略输入预先设置的大语言模型之前,需要:接收自定义数据构造策略,将自定义数据构造策略和目标数据构造策略作为输入大语言模型的数据构造策略。
在将测试数据和数据构造策略输入预先设置的大语言模型之前,还需要:识别出自定义数据构造策略和目标数据构造策略所包括的关键词,对关键词进行标记。因此,将测试数据和数据构造策略输入预先设置的大语言模型(步骤B),包括:将测试数据和包括标记后的关键词的自定义数据构造策略、目标数据构造策略输入大语言模型。
此外,响应于接收到补充说明,从关键词中确定与补充说明匹配的目标关键词,将补充说明和目标关键词进行关联;将与目标关键词关联的补充说明输入大语言模型。
值得注意的是,该方法中,需要:判断新测试数据是否符合预先设置的数据规范;在新测试数据不符合数据规范的情况下,响应于接收到新数据构造策略,根据新数据构造策略调整新测试数据,使调整后的新测试数据符合数据规范。
权利要求书提到,在将测试数据和数据构造策略输入预先设置的大语言模型之前,方法还包括:响应于接收到训练数据,根据训练数据所属的业务领域对训练数据进行分类;使用分类后的多组训练数据分别对预先设置的通用大模型进行微调,得到应用于不同业务领域的多个大语言模型;根据测试数据所属的业务领域,从多个大语言模型中确定目标大语言模型。因此,将测试数据和数据构造策略输入预先设置的大语言模型(步骤B),还包括:将测试数据和数据构造策略输入目标大语言模型。
说明书提到该发明的背景为,在进行软件测试之前需要先准备测试数据,测试数据的质量往往能够决定软件测试的效果,例如,数据量大、数据格式丰富、数据取值范围随机的测试数据能够帮助用户发现尽可能多的问题,达到较好的测试效果。在准备测试数据时,通常由人工直接编写测试数据,或者根据人工编写的生成脚本批量生成测试数据。
但是,现有技术至少存在如下问题:人工编写的测试数据或者脚本通常受编写者的知识背景、编写习惯的影响,导致得到的测试数据缺乏随机性,仅能够测试出软件的部分问题,软件测试效率较低。
该发明根据与测试结果中的问题相关的测试数据和数据构造策略生成新测试数据,能够提高测试数据的随机性,有利于测试出更多的问题,提高软件测试效率,降低人力成本。
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。










