

 新火种
2024-11-19
新火种
2024-11-19 


对标o1,Kimi放出了最能打的国产模型
AI 领域正在经历新一轮技术范式的变化,预训练 Scaling Law 放缓之后,推理时间计算成为了新的性能提升关键。两个月前,OpenAI o1 的诞生再次引领了大模型技术的突破。从后训练阶段入手,通过更多的强化学习、原生的思维链和更长的推理时间,o1 将大模型的能力又往前推了一步。这段时间,国内大模型初创公司月之暗面的技术攻关经历了一场加速。继 Kimi 探索版 10 月开放之后,这家公司在 11 月 16 日交上又一份答卷:Kimi 的最新一代推理模型 k0-math,在数学能力已实现对标 OpenAI o1-mini 和 o1-preview。 这是 Kimi 推出的首款推理能力强化模型,k0-math 同样采用了全新的强化学习和思维链推理技术,通过模拟人脑的思考和反思过程,大幅提升了解决数学难题的能力,可以帮助用户完成更具挑战性的数学任务 。Kimi 创始人杨植麟表示,接下来 k0-math 模型会持续迭代,提升更难题目的解题能力,挑战数学模型的能力极限。同时,k0-math 数学模型和更强大的 Kimi 探索版,将会分批陆续上线 Kimi 网页版(kimi.ai)和 Kimi 智能助手 APP。在 Kimi Chat 全量开放一周年之际,还有一个数字吸引了大家的注意:截至2024 年 10 月,Kimi 智能助手在 PC 网页、手机 APP、小程序等全平台的月度活跃用户已超过 3600 万。数学能力对标 o1,k0-math 的表现如何?在多项基准能力测试中,k0-math 的数学能力可对标 OpenAI o1 系列公开发布的两个模型:o1-mini 和 o1-preview。具体来说,在中考、高考、考研以及包含入门竞赛题的 MATH 等 4 个数学基准测试中,k0-math 初代模型成绩超过 o1-mini 和 o1-preview 模型:k0-math 模型得分 93.8,o1-mini 为 90 分, o1-preview 为 85.5 分。k0-math 的成绩仅次于尚未正式上线的 o1 完全版的 94.8 分。而在两个难度更大的竞赛级别的数学题库 OMNI-MATH 和 AIME 基准测试中,k0-math 初代模型的表现分别达到了 o1-mini 最高成绩的 90% 和 83%。
这是 Kimi 推出的首款推理能力强化模型,k0-math 同样采用了全新的强化学习和思维链推理技术,通过模拟人脑的思考和反思过程,大幅提升了解决数学难题的能力,可以帮助用户完成更具挑战性的数学任务 。Kimi 创始人杨植麟表示,接下来 k0-math 模型会持续迭代,提升更难题目的解题能力,挑战数学模型的能力极限。同时,k0-math 数学模型和更强大的 Kimi 探索版,将会分批陆续上线 Kimi 网页版(kimi.ai)和 Kimi 智能助手 APP。在 Kimi Chat 全量开放一周年之际,还有一个数字吸引了大家的注意:截至2024 年 10 月,Kimi 智能助手在 PC 网页、手机 APP、小程序等全平台的月度活跃用户已超过 3600 万。数学能力对标 o1,k0-math 的表现如何?在多项基准能力测试中,k0-math 的数学能力可对标 OpenAI o1 系列公开发布的两个模型:o1-mini 和 o1-preview。具体来说,在中考、高考、考研以及包含入门竞赛题的 MATH 等 4 个数学基准测试中,k0-math 初代模型成绩超过 o1-mini 和 o1-preview 模型:k0-math 模型得分 93.8,o1-mini 为 90 分, o1-preview 为 85.5 分。k0-math 的成绩仅次于尚未正式上线的 o1 完全版的 94.8 分。而在两个难度更大的竞赛级别的数学题库 OMNI-MATH 和 AIME 基准测试中,k0-math 初代模型的表现分别达到了 o1-mini 最高成绩的 90% 和 83%。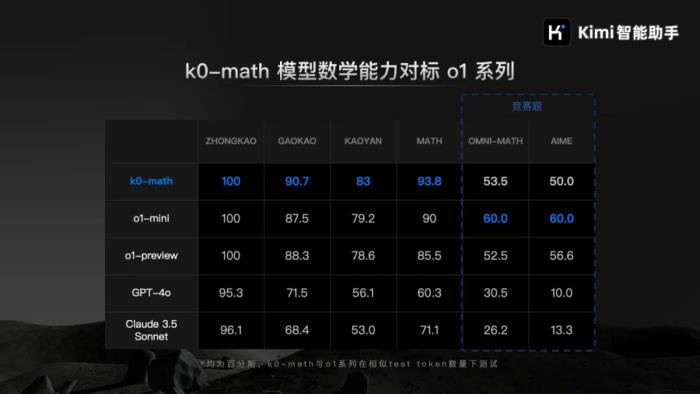
常规模型的关键目标是尽快提供答案。与之不同,在做题过程中,k0-math 模型会花更长的时间来推理,包括思考和规划思路,并且在必要时自行反思改进解题思路,提升答题的成功率。k0-math 的解题思考过程,常常会让数学高手也受到启发。以这道 AIME 竞赛题目为例,k0-math 模型通过不断探索和试错,经历了八九次失败,意识到自己之前用了过于复杂的方法,最终得出了正确结果。
不过,需要注意的是,k0-math 模型虽然擅长解答大部分很有难度的数学题,但是当前版本还无法解答 LaTeX 格式难以描述的几何图形类问题。此外,它还有一些局限性需要突破,包括对于过于简单的数学问题。例如「1+1=?」,k0-math 模型可能会过度思考。「意图增强」等三大推理能力注入 Kimi 探索版新的强化学习技术范式带来的推理能力提升,也将会泛化到更多日常任务上。在上个月推出的 Kimi 探索版中,月之暗面已将推理能力运用到 AI 搜索任务上,通过模拟人类的推理思考过程,多级分解复杂问题,执行深度搜索,并即时反思改进结果,帮助用户更高效地完成复杂的搜索调研任务。据杨植麟介绍,基于强化学习层面的技术创新,Kimi 探索版已在三大推理能力上实现突破:意图增强、信源分析和链式思考。意图增强:Kimi 探索版可以将抽象的问题和模糊的概念具体化,拓展用户的真实搜索意图。例如,当互联网产品经理调研某产品的用户忠诚度,Kimi 探索版会思考当用户搜索「忠诚度」时,本质上是想做数据的分析,然后找到可以体现忠诚度的维度,将这个比较模糊和抽象的概念,转化为更加具体的「活跃度、留存率、使用频率、使用时长」等关键词,然后通过机器更擅长的海量并行搜索,查找更全面和准确的答案。信源分析:Kimi 探索版会从大量的搜索来源结果中,分析筛选出更具权威性和可靠性的信源,并且在答案中提供溯源链接,可一键定位信源具体出处,精确到段落级别,让条信息都有据可查。例如,在咨询顾问调查人群市场规模的场景,借助 Kimi 探索版查找中国不同年龄的人口占比情况时,Kimi 会筛选最权威和最新的人口普查报告信息。链式思考:Kimi 探索版可以更好地基于思维链推理能力处理产品、公司、行业等研究问题。例如,当程序员做技术选型,想要了解「react 中有哪些状态管理库,最好用的是什么」。Kimi 首先会拆解问题,找到 react 的状态管理库有哪些,然后分别搜索每个状态管理库的优缺点、使用场景和推荐理由,最后分析总结找到的所有高质量信息,推荐一个最适合大多数情况的状态管理库和理由。面向推理 Scaling Law 时代在过去几年中,LLM 使用来自网站、书籍和其他来源的公开文本和其他数据进行预训练,但模型开发者基本上已经从这类数据中榨干了尽可能多的资源。有研究预计,如果 LLM 保持现在的发展势头,预计在 2028 年左右,已有的数据储量将被全部利用完。届时,基于大数据的大模型的发展将可能放缓甚至陷入停滞。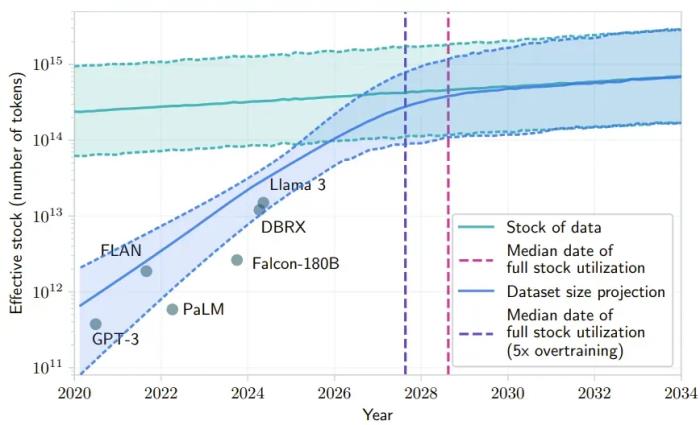
来源:论文《Will we run out of data? Limits of LLM scaling based on human-generated data》好在以 o1 为代表的「推理 Scaling Law」成果,给大模型规模扩展 vs 性能的曲线带来了一次上翘。领域内认为,这让大模型领域重现了类似当年 AlphaGo 强化学习的成功 —— 给越多算力,就输出越多智能,一直到超越人类水平。在这条赛道,不论海外的 OpenAI、谷歌,还是国内的月之暗面,都重新站在了全新的起跑线上。当然,这种范式转变,首先加剧了科技公司之间的人才争夺。去年 7 月,德扑 AI 作者 Noam Brown 就加入 OpenAI,并在 o1 项目中发挥了至关重要的作用。近日,Anthropic 又从谷歌挖走了 AlphaGo 核心作者、强化学习大牛 Julian Schrittwieser。对此,月之暗面是否有所准备?「我们是很早看到这一点的。只不过在早期,预训练的很多红利还没有被充分发挥出来,所以可能更关注怎么通过预测下一个 Token 去压缩更多的智能,但关于强化学习,不管是在人才还是在技术的储备上,我们都有很早地去铺垫。」杨植麟表示。
相关推荐



- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。










