

 新火种
2024-11-17
新火种
2024-11-17 

微调大模型,AMDMI300X就够了!跟着这篇博客微调Llama3.1405B,效果媲美H100
随着 AI 模型的参数量越来越大,对算力的需求也水涨船高。比如最近,Llama-3.1 登上了最强开源大模型的宝座,但超大杯 405B 版本的内存就高达 900 多 GB,这对算力构成了更加苛刻的挑战。如何降低算力的使用成本和使用门槛,已经成为许多公司寻求突破的关键。Felafax 就是其中的一家创业公司,致力于简化 AI 训练集群的搭建流程。 Nikhil Sonti 和 Nikhin Sonti 创立了 Felafax,他们的口号是在构建开源 AI 平台,为下一代 AI 硬件服务,将机器学习的训练成本降低 30%。与英伟达相比,AMD 的 GPU,尤其是 MI300X 系列,提供了更高的性价比,按每美元计算,其性能表现更为出色。最近,Felafax 的联合创始人 Nikhil Sonti 发布了一篇博客,详细分享了如何通过 8 张 AMD MI300X GPU 和 JAX 微调 LLaMA 3.1 405B 模型的方法,所有代码现已开源。
Nikhil Sonti 和 Nikhin Sonti 创立了 Felafax,他们的口号是在构建开源 AI 平台,为下一代 AI 硬件服务,将机器学习的训练成本降低 30%。与英伟达相比,AMD 的 GPU,尤其是 MI300X 系列,提供了更高的性价比,按每美元计算,其性能表现更为出色。最近,Felafax 的联合创始人 Nikhil Sonti 发布了一篇博客,详细分享了如何通过 8 张 AMD MI300X GPU 和 JAX 微调 LLaMA 3.1 405B 模型的方法,所有代码现已开源。 与英伟达 H100 的比较,来源:TensorWave训练 LLaMA 405B:性能与可扩展性使用 JAX,可以成功地在 AMD GPU 上训练 LLaMA 405B 模型。我们使用 LoRA 微调,将所有模型权重和 LoRA 参数都设为 bfloat16,LoRA rank 设为 8,LoRA alpha 设为 16:模型大小:LLaMA 模型的权重占用了约 800GB 的显存。LoRA 权重 + 优化器状态:大约占用了 400GB 的显存。显存总使用量:占总显存的 77%,约 1200GB。限制:由于 405B 模型的规模过大,batch 大小和序列长度的空间有限,使用的 batch size 为 16,序列长度为 64。JIT 编译:由于空间限制,无法运行 JIT 编译版本;它可能需要比急切模式稍多的空间。训练速度:使用 JAX 急切模式,约为 35 tokens / 秒。内存效率:稳定在约 70% 左右。扩展性:在 8 张 GPU 上,使用 JAX 的扩展性接近线性。由于硬件和显存的限制,我们无法运行 JIT 编译版本的 405B 模型,整个训练过程是在 JAX 的急切模式下执行的,因此还有很大的进步空间。下图中显示了在一次微调训练步骤中,8 张 GPU 的显存利用率和 rocm-smi 输出:GPU 利用率:
与英伟达 H100 的比较,来源:TensorWave训练 LLaMA 405B:性能与可扩展性使用 JAX,可以成功地在 AMD GPU 上训练 LLaMA 405B 模型。我们使用 LoRA 微调,将所有模型权重和 LoRA 参数都设为 bfloat16,LoRA rank 设为 8,LoRA alpha 设为 16:模型大小:LLaMA 模型的权重占用了约 800GB 的显存。LoRA 权重 + 优化器状态:大约占用了 400GB 的显存。显存总使用量:占总显存的 77%,约 1200GB。限制:由于 405B 模型的规模过大,batch 大小和序列长度的空间有限,使用的 batch size 为 16,序列长度为 64。JIT 编译:由于空间限制,无法运行 JIT 编译版本;它可能需要比急切模式稍多的空间。训练速度:使用 JAX 急切模式,约为 35 tokens / 秒。内存效率:稳定在约 70% 左右。扩展性:在 8 张 GPU 上,使用 JAX 的扩展性接近线性。由于硬件和显存的限制,我们无法运行 JIT 编译版本的 405B 模型,整个训练过程是在 JAX 的急切模式下执行的,因此还有很大的进步空间。下图中显示了在一次微调训练步骤中,8 张 GPU 的显存利用率和 rocm-smi 输出:GPU 利用率: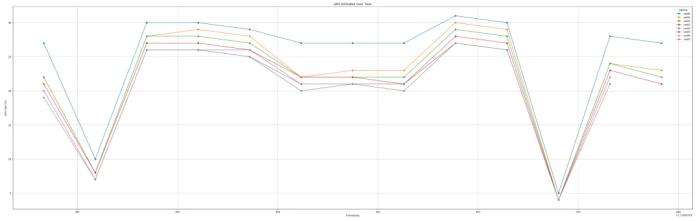 显存利用率:
显存利用率: rocm-smi 输出:
rocm-smi 输出: 此前,Nikhil Sonti 分享过如何将 LLaMA 3.1 从 PyTorch 移植到 JAX。他指出,目前 90% 的大型语言模型(LLM)都运行在 NVIDIA GPU 上,但实际上还有一些同样强大且性价比更高的替代方案。例如,在 Google TPU 上训练和部署 Llama 3.1 的成本比 NVIDIA GPU 低约 30%。然而,支持非 NVIDIA 硬件的开发工具较为匮乏。Sonti 最初尝试使用 PyTorch XLA 在 TPU 上训练 Llama 3.1,但过程并不顺利。XLA 与 PyTorch 的集成不够完善,缺少一些关键的库(如 bitsandbytes 无法正常运行),同时还遇到了一些难以解决的 HuggingFace 错误。为此,他决定调整策略,将 Llama 3.1 从 PyTorch 移植到 JAX,成功解决了这些问题。Sonti 还录制了详细的教程视频,并开源了所有代码:
此前,Nikhil Sonti 分享过如何将 LLaMA 3.1 从 PyTorch 移植到 JAX。他指出,目前 90% 的大型语言模型(LLM)都运行在 NVIDIA GPU 上,但实际上还有一些同样强大且性价比更高的替代方案。例如,在 Google TPU 上训练和部署 Llama 3.1 的成本比 NVIDIA GPU 低约 30%。然而,支持非 NVIDIA 硬件的开发工具较为匮乏。Sonti 最初尝试使用 PyTorch XLA 在 TPU 上训练 Llama 3.1,但过程并不顺利。XLA 与 PyTorch 的集成不够完善,缺少一些关键的库(如 bitsandbytes 无法正常运行),同时还遇到了一些难以解决的 HuggingFace 错误。为此,他决定调整策略,将 Llama 3.1 从 PyTorch 移植到 JAX,成功解决了这些问题。Sonti 还录制了详细的教程视频,并开源了所有代码: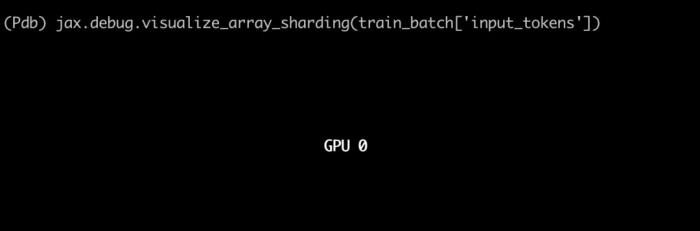 在调用 jax.device_put 之后:
在调用 jax.device_put 之后: 加入 LoRALoRA 通过将权重更新分解为低秩矩阵,减少了可训练参数的数量,这对于微调大型模型特别有效。以下是在 AMD GPU 上微调 Llama 3.1-405 的 LoRA 的要点:将 LoRA 参数(lora_a 和 lora_b)与主模型参数分开。使用 jax.lax.stop_gradient (kernel) 来防止对主模型权重的更新。使用 lax.dot_general 进行快速、精确控制的矩阵运算。LoRA 输出在添加到主输出之前会被缩放为 (self.lora_alpha/self.lora_rank)。LoRADense 层在此设定一个自定义的 LoRADense 层,该层集成了 LoRA 参数:class LoRADense (nn.Module): features: int lora_rank: int = 8 lora_alpha: float = 16.0@nn.compactdef __call__(self, inputs: Any) -> Any:# Original kernel parameter (frozen) kernel = self.param ('kernel', ...) y = lax.dot_general (inputs, jax.lax.stop_gradient (kernel), ...)# LoRA parameters (trainable) lora_a = self.variable ('lora_params', 'lora_a', ..., ...) lora_b = self.variable ('lora_params', 'lora_b', ..., ...)# Compute LoRA output lora_output = lax.dot_general (inputs, lora_a.value, ...) lora_output = lax.dot_general (lora_output, lora_b.value, ...)# Combine original output with LoRA modifications y += (self.lora_alpha/self.lora_rank) * lora_output return y.astype (self.dtype)分片 LoRA 参数为了高效地在设备之间分配 LoRA 参数,我们也通过 JAX 设定了分片规则,这确保了 LoRA 参数与主模型参数的分片一致,优化了内存使用和计算效率。LoRA A matrices (lora_a)LoRA A 矩阵(lora_a)分片规则:PS ("fsdp", "mp")可视化结果:如下图所示,lora_a 参数被分片为 (8, 1),这意味着第一个轴在 8 个设备上进行分片("fsdp" 轴),而第二个轴未进行分片。
加入 LoRALoRA 通过将权重更新分解为低秩矩阵,减少了可训练参数的数量,这对于微调大型模型特别有效。以下是在 AMD GPU 上微调 Llama 3.1-405 的 LoRA 的要点:将 LoRA 参数(lora_a 和 lora_b)与主模型参数分开。使用 jax.lax.stop_gradient (kernel) 来防止对主模型权重的更新。使用 lax.dot_general 进行快速、精确控制的矩阵运算。LoRA 输出在添加到主输出之前会被缩放为 (self.lora_alpha/self.lora_rank)。LoRADense 层在此设定一个自定义的 LoRADense 层,该层集成了 LoRA 参数:class LoRADense (nn.Module): features: int lora_rank: int = 8 lora_alpha: float = 16.0@nn.compactdef __call__(self, inputs: Any) -> Any:# Original kernel parameter (frozen) kernel = self.param ('kernel', ...) y = lax.dot_general (inputs, jax.lax.stop_gradient (kernel), ...)# LoRA parameters (trainable) lora_a = self.variable ('lora_params', 'lora_a', ..., ...) lora_b = self.variable ('lora_params', 'lora_b', ..., ...)# Compute LoRA output lora_output = lax.dot_general (inputs, lora_a.value, ...) lora_output = lax.dot_general (lora_output, lora_b.value, ...)# Combine original output with LoRA modifications y += (self.lora_alpha/self.lora_rank) * lora_output return y.astype (self.dtype)分片 LoRA 参数为了高效地在设备之间分配 LoRA 参数,我们也通过 JAX 设定了分片规则,这确保了 LoRA 参数与主模型参数的分片一致,优化了内存使用和计算效率。LoRA A matrices (lora_a)LoRA A 矩阵(lora_a)分片规则:PS ("fsdp", "mp")可视化结果:如下图所示,lora_a 参数被分片为 (8, 1),这意味着第一个轴在 8 个设备上进行分片("fsdp" 轴),而第二个轴未进行分片。 LoRA B 矩阵(lora_b)分片规则:PS ("mp", "fsdp")可视化结果:如下图所示,lora_b 参数被分片为 (1, 8),这意味着第二个轴在 8 个设备上进行分片(fsdp 轴),而第一个轴未进行分片。
LoRA B 矩阵(lora_b)分片规则:PS ("mp", "fsdp")可视化结果:如下图所示,lora_b 参数被分片为 (1, 8),这意味着第二个轴在 8 个设备上进行分片(fsdp 轴),而第一个轴未进行分片。 这种分片策略优化了参数的分配,减少了通信开销,并在训练过程中增强了并行性。它确保每个设备仅持有一部分 LoRA 参数,使得大模型如 LLaMA 405B 的高效扩展成为可能。仅更新 LoRA 参数为了优化训练,在微调 LLaMA 405B 模型,只计算 LoRA 参数的梯度,保持主模型参数不变。这个方法减少了内存使用,并加速了训练,因为只更新较少的参数。可以移步 GitHub 仓库,查看实现细节。在训练过程中,每一步都涉及将一批输入数据通过模型进行处理。由于只有 LoRA 参数是可训练的,因此模型的预测和计算的损失仅依赖于这些参数,然后对 LoRA 参数进行反向传播。只更新这些参数简化了训练过程,使得在多个 GPU 上高效微调像 LLaMA 405B 这样的大型模型成为可能。更多研究细节,请参考原博客。
这种分片策略优化了参数的分配,减少了通信开销,并在训练过程中增强了并行性。它确保每个设备仅持有一部分 LoRA 参数,使得大模型如 LLaMA 405B 的高效扩展成为可能。仅更新 LoRA 参数为了优化训练,在微调 LLaMA 405B 模型,只计算 LoRA 参数的梯度,保持主模型参数不变。这个方法减少了内存使用,并加速了训练,因为只更新较少的参数。可以移步 GitHub 仓库,查看实现细节。在训练过程中,每一步都涉及将一批输入数据通过模型进行处理。由于只有 LoRA 参数是可训练的,因此模型的预测和计算的损失仅依赖于这些参数,然后对 LoRA 参数进行反向传播。只更新这些参数简化了训练过程,使得在多个 GPU 上高效微调像 LLaMA 405B 这样的大型模型成为可能。更多研究细节,请参考原博客。
Nikhil Sonti 和 Nikhin Sonti 创立了 Felafax,他们的口号是在构建开源 AI 平台,为下一代 AI 硬件服务,将机器学习的训练成本降低 30%。与英伟达相比,AMD 的 GPU,尤其是 MI300X 系列,提供了更高的性价比,按每美元计算,其性能表现更为出色。最近,Felafax 的联合创始人 Nikhil Sonti 发布了一篇博客,详细分享了如何通过 8 张 AMD MI300X GPU 和 JAX 微调 LLaMA 3.1 405B 模型的方法,所有代码现已开源。
与英伟达 H100 的比较,来源:TensorWave训练 LLaMA 405B:性能与可扩展性使用 JAX,可以成功地在 AMD GPU 上训练 LLaMA 405B 模型。我们使用 LoRA 微调,将所有模型权重和 LoRA 参数都设为 bfloat16,LoRA rank 设为 8,LoRA alpha 设为 16:模型大小:LLaMA 模型的权重占用了约 800GB 的显存。LoRA 权重 + 优化器状态:大约占用了 400GB 的显存。显存总使用量:占总显存的 77%,约 1200GB。限制:由于 405B 模型的规模过大,batch 大小和序列长度的空间有限,使用的 batch size 为 16,序列长度为 64。JIT 编译:由于空间限制,无法运行 JIT 编译版本;它可能需要比急切模式稍多的空间。训练速度:使用 JAX 急切模式,约为 35 tokens / 秒。内存效率:稳定在约 70% 左右。扩展性:在 8 张 GPU 上,使用 JAX 的扩展性接近线性。由于硬件和显存的限制,我们无法运行 JIT 编译版本的 405B 模型,整个训练过程是在 JAX 的急切模式下执行的,因此还有很大的进步空间。下图中显示了在一次微调训练步骤中,8 张 GPU 的显存利用率和 rocm-smi 输出:GPU 利用率:显存利用率:rocm-smi 输出: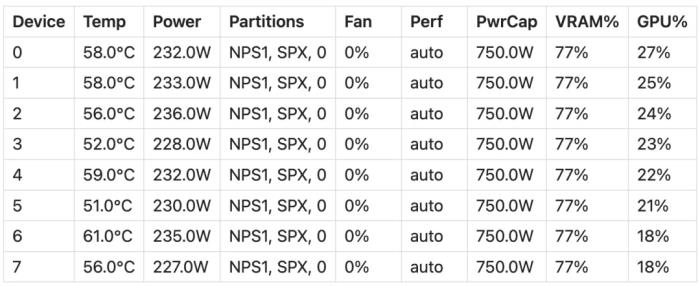
此前,Nikhil Sonti 分享过如何将 LLaMA 3.1 从 PyTorch 移植到 JAX。他指出,目前 90% 的大型语言模型(LLM)都运行在 NVIDIA GPU 上,但实际上还有一些同样强大且性价比更高的替代方案。例如,在 Google TPU 上训练和部署 Llama 3.1 的成本比 NVIDIA GPU 低约 30%。然而,支持非 NVIDIA 硬件的开发工具较为匮乏。Sonti 最初尝试使用 PyTorch XLA 在 TPU 上训练 Llama 3.1,但过程并不顺利。XLA 与 PyTorch 的集成不够完善,缺少一些关键的库(如 bitsandbytes 无法正常运行),同时还遇到了一些难以解决的 HuggingFace 错误。为此,他决定调整策略,将 Llama 3.1 从 PyTorch 移植到 JAX,成功解决了这些问题。Sonti 还录制了详细的教程视频,并开源了所有代码:
在调用 jax.device_put 之后:加入 LoRALoRA 通过将权重更新分解为低秩矩阵,减少了可训练参数的数量,这对于微调大型模型特别有效。以下是在 AMD GPU 上微调 Llama 3.1-405 的 LoRA 的要点:将 LoRA 参数(lora_a 和 lora_b)与主模型参数分开。使用 jax.lax.stop_gradient (kernel) 来防止对主模型权重的更新。使用 lax.dot_general 进行快速、精确控制的矩阵运算。LoRA 输出在添加到主输出之前会被缩放为 (self.lora_alpha/self.lora_rank)。LoRADense 层在此设定一个自定义的 LoRADense 层,该层集成了 LoRA 参数:class LoRADense (nn.Module): features: int lora_rank: int = 8 lora_alpha: float = 16.0@nn.compactdef __call__(self, inputs: Any) -> Any:# Original kernel parameter (frozen) kernel = self.param ('kernel', ...) y = lax.dot_general (inputs, jax.lax.stop_gradient (kernel), ...)# LoRA parameters (trainable) lora_a = self.variable ('lora_params', 'lora_a', ..., ...) lora_b = self.variable ('lora_params', 'lora_b', ..., ...)# Compute LoRA output lora_output = lax.dot_general (inputs, lora_a.value, ...) lora_output = lax.dot_general (lora_output, lora_b.value, ...)# Combine original output with LoRA modifications y += (self.lora_alpha/self.lora_rank) * lora_output return y.astype (self.dtype)分片 LoRA 参数为了高效地在设备之间分配 LoRA 参数,我们也通过 JAX 设定了分片规则,这确保了 LoRA 参数与主模型参数的分片一致,优化了内存使用和计算效率。LoRA A matrices (lora_a)LoRA A 矩阵(lora_a)分片规则:PS ("fsdp", "mp")可视化结果:如下图所示,lora_a 参数被分片为 (8, 1),这意味着第一个轴在 8 个设备上进行分片("fsdp" 轴),而第二个轴未进行分片。LoRA B 矩阵(lora_b)分片规则:PS ("mp", "fsdp")可视化结果:如下图所示,lora_b 参数被分片为 (1, 8),这意味着第二个轴在 8 个设备上进行分片(fsdp 轴),而第一个轴未进行分片。这种分片策略优化了参数的分配,减少了通信开销,并在训练过程中增强了并行性。它确保每个设备仅持有一部分 LoRA 参数,使得大模型如 LLaMA 405B 的高效扩展成为可能。仅更新 LoRA 参数为了优化训练,在微调 LLaMA 405B 模型,只计算 LoRA 参数的梯度,保持主模型参数不变。这个方法减少了内存使用,并加速了训练,因为只更新较少的参数。可以移步 GitHub 仓库,查看实现细节。在训练过程中,每一步都涉及将一批输入数据通过模型进行处理。由于只有 LoRA 参数是可训练的,因此模型的预测和计算的损失仅依赖于这些参数,然后对 LoRA 参数进行反向传播。只更新这些参数简化了训练过程,使得在多个 GPU 上高效微调像 LLaMA 405B 这样的大型模型成为可能。更多研究细节,请参考原博客。 相关推荐


- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。










