

 新火种
2024-11-17
新火种
2024-11-17 

大模型已过时,小模型SLM才是未来?苹果正在研究这个
手机还是更适合小模型
大模型虽然好,但我的笔记本和手机都跑不动呀。就算勉强能跑起来,也是奇慢无比。而与此同时,对适合移动和边缘设备的小模型的需求却在不断增长,因为这些模型似乎才能真正满足人们的日常需求。正因为此,有不少研究者和应用开发者都认为小模型才是 AI 的未来。
 事实上,Meta 和 Mistral 等都已经发布了自己的 SLM,比如 Llama 3.2 的 1B 和 3B 版本以及 Ministral 3B。另外还有一些社区开发的 SLM,比如 BabyLlama 系列(不到 1B 参数)、 TinyLLaMA(1.1B 参数)。为了打造出真正好用的小型语言模型(SLM),AI 研究社区想出了各种各样的方法,像是对大模型进行蒸馏或量化或者就直接去训练性能优异的小模型。实际上, SLM 正在逐渐成为一个研究热门方向,简单检索 arXiv 上的关键词也能大致看见这一趋势:9 和 10 月份,SLM 相关研究论文的数量有了明显增长。
事实上,Meta 和 Mistral 等都已经发布了自己的 SLM,比如 Llama 3.2 的 1B 和 3B 版本以及 Ministral 3B。另外还有一些社区开发的 SLM,比如 BabyLlama 系列(不到 1B 参数)、 TinyLLaMA(1.1B 参数)。为了打造出真正好用的小型语言模型(SLM),AI 研究社区想出了各种各样的方法,像是对大模型进行蒸馏或量化或者就直接去训练性能优异的小模型。实际上, SLM 正在逐渐成为一个研究热门方向,简单检索 arXiv 上的关键词也能大致看见这一趋势:9 和 10 月份,SLM 相关研究论文的数量有了明显增长。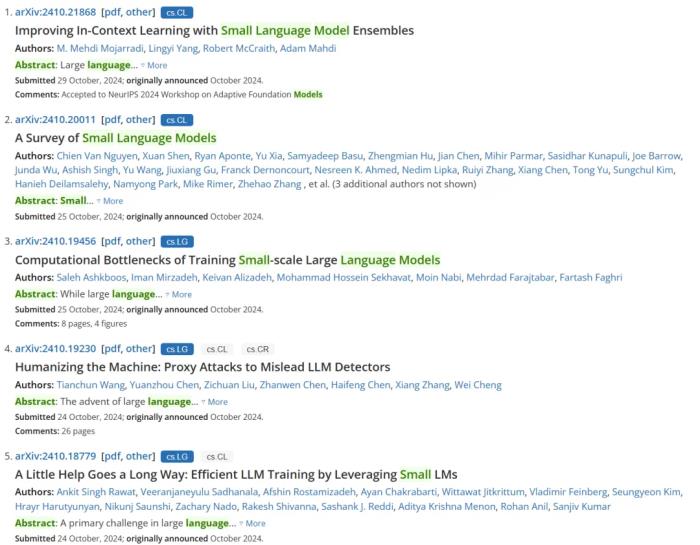 今天,我们就来看看苹果的一篇相关论文,其探讨了训练小型语言模型的计算瓶颈。
今天,我们就来看看苹果的一篇相关论文,其探讨了训练小型语言模型的计算瓶颈。
论文标题:Computational Bottlenecks of Training Small-scale Large Language Models
论文地址:https://arxiv.org/pdf/2410.19456
首先,多小的模型才能算是小型语言模型,或按苹果的说法 —— 小规模大型语言模型?这个苹果团队给出的指标是「参数量 ≤ 2B」。当然,这并非人们公认的标准,也有人认为 Ministral 3B 和 Llama 3.2 3B 等 3B 参数量的模型也算是 SLM。总之,大与小是一个会随着计算基础设施的演进而动态变化的标准,昨天的大模型可能就会成为明天的小模型。尽管 SLM 规模很小,但其表现并不一定很差,并且已经展现出了自己的巨大潜力。很多借助剪枝、蒸馏和量化等技术得到的 SLM 的性能并不比大得多的模型差,甚至有时候还能更胜一筹。举个例子,Gemma-2B 的性能就优于大得多的 OPT-175B,这就挑战了大多数人的一个固有观念:模型大小是有效性的主导决定因素。另外,也有采用互相验证等其它新颖方法提升 SLM 能力的研究思路,比如机器之心曾报道过的《两个小模型互相验证,直接比肩大模型?微软的 rStar 甚至没用 CoT 和微调》。事实上,随着 OpenAI ο1 系列模型的发布,通过优化推理时间计算也成了提升 SLM 性能的重要途径。性能足够好的 SLM 具有很大的好处,最基本的就是速度快、效率高、性价比高。因此,SLM 对计算资源有限的组织(如小型企业和学术机构)非常有吸引力。苹果的这项研究关注的是 SLM 的训练动态。事实上,在训练方面,LLM 和 SLM 的差距很大。LLM 的计算需求和基础设施需求并不一定适用于 SLM。考虑到云平台可用的硬件配置多种多样(包括 GPU 类型、批量大小和通信协议),有必要对这些影响 SLM 训练效率的因素进行系统性的分析,尤其是要考虑一些符合实际的指标,比如每美元的损失和每秒 token 数。该团队的研究结果表明,对于更小型的模型,可以使用 A100-40GB GPU 和分布式数据并行(DDP)等更低成本选择,同时不会对性能产生负面影响。对于更大型的模型,就必需更高级的配置了(例如 A100-80GB 和 H100-80GB GPU 搭配 Flash Attention(FA)和完全分片式数据并行(FSDP)),这样才能处理更大的数据批以及防止内存相关的问题。SLM 领域的最近研究进展表明,扩展 AI 系统不仅是要追求先进的性能,也要考虑实际应用。目前这股研发 SLM 的趋势表明,重新评估硬件和计算策略是非常重要的。苹果这项研究为此做出了贡献,他们系统性地研究了在不同的云基础设施和设置上,训练最多 2B 参数大小的 SLM 的计算瓶颈和成本效率。他们发现:1. 相比于 LLM,FlashAttention 对 SLM 来说更重要;2. H100-80GB 和 A100-80GB 等昂贵硬件对 SLM 训练来说不一定具有成本效益;3. DDP 是 SLM 的最佳分布式训练方案;4. 对 SLM 训练来说,最大化 GPU 内存利用率并不是成本最优的。模型和参数该团队研究的是 LLaMa 架构,毕竟不管是 LLM 还是 SLM,这都是当今最流行的架构。LLaMa-2 和 3 最小的版本分别是 7B 和 8B,但这对大多数移动硬件来说还是太大了。为此,该团队进行了一番操作:为了定义他们自己的模型,他们通过在 Llama 模型上拟合一条曲线而提取了模型的解码器模块和参数数量。见下图 5。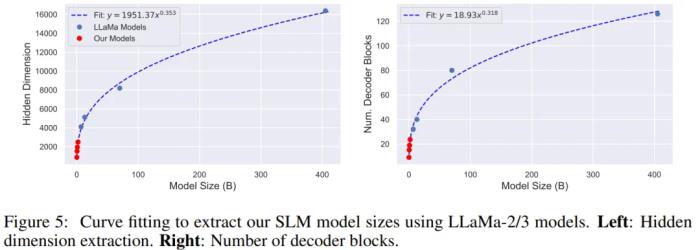 他们评估了四种不同的模型大小:100M、500M、1B 和 2B。值得注意的是,他们最大化了图中 x 轴或图例中未显示的所有配置参数。也就是说,他们对下面列出的所有配置参数组合进行大型网格搜索,并且每个图中的每个点都是给定图中指定的所有参数的最佳配置。这样,他们找到了最佳的 Token/Dollar 比值,并假设可以通过调整优化超参数(例如学习率)来实现与硬件最佳配置的最佳收敛。
他们评估了四种不同的模型大小:100M、500M、1B 和 2B。值得注意的是,他们最大化了图中 x 轴或图例中未显示的所有配置参数。也就是说,他们对下面列出的所有配置参数组合进行大型网格搜索,并且每个图中的每个点都是给定图中指定的所有参数的最佳配置。这样,他们找到了最佳的 Token/Dollar 比值,并假设可以通过调整优化超参数(例如学习率)来实现与硬件最佳配置的最佳收敛。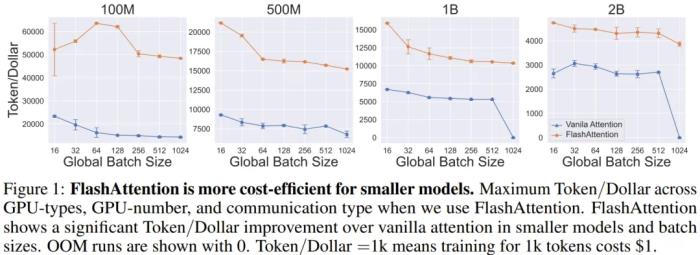 接下来,给出这些配置参数的定义
接下来,给出这些配置参数的定义GPU 类型:他们评估了三种英伟达 GPU:A100-40GB、A100-80GB 和 H100-80GB。所有 GPU 使用的数据类型都是 BFloat16。
GPU 数量和通信:每种 GPU 类型都有三种主要训练配置,包括:单节点单 GPU(1 台 GPU)、单节点多 GPU(2、4 和 8 台 GPU)和多节点多 GPU(16、32 和 64 台 GPU)。当 GPU 超过 1 台时,还会评估分布式数据并行(DDP)和完全分片式数据并行(FSDP)这两种通信方法。对于分片,他们也研究了两种策略:1) 完全分片,即对所有梯度、优化器状态和权重进行分片;2) grad_op 分片,即仅对梯度和优化器状态进行分片(但权重不分片)。他们使用了 RDMA/EFA。
样本数量:他们还评估了训练期间适合单个 GPU 的各种样本数量。他们将序列长度固定为 1028,并迭代适合单台设备的批量大小。由于即使在最小(100M)的模型中也无法将 128 个样本放入单个 GPU 内存中,因此他们研究了每台设备的批量大小为 4、8、16、32 和 64 的情况。这里不使用梯度累积
Flash Attention:他们研究了在注意力模块中使用 Flash Attention 的影响。
实验结果该团队展示了 SLM 在 A100-40GB、A100-80GB 和 H100-80GB 上运行的结果。他们在 HuggingFace 中部署了模型,没有附加任何额外的框架,batch size=1024,并使用 PyTorch 运行了如下表数值设置的实验。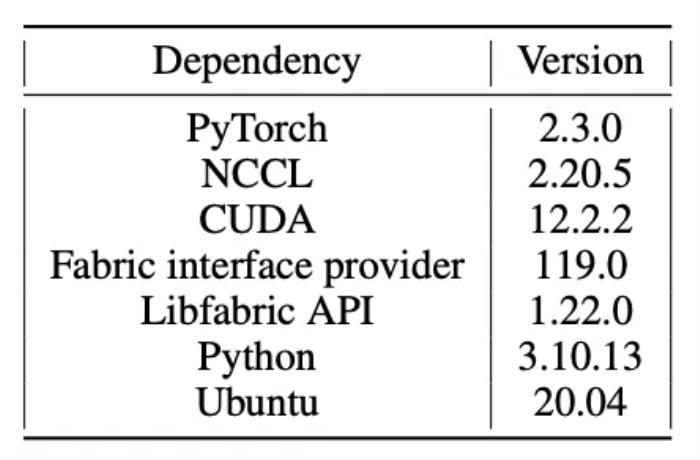 通过多次实验,研究团队得出了以下观察:Q1:在 SLM 训练中使用 FlashAttention 有多重要?图 1 比较了不同 batch size 下 FlashAttention2 与普通注意力的区别。首先,使用 FlashAttention 显著提高了 SLM 的 Token/Dollar 效率,用同样的钱(Dollar)能处理更多数据(Token)。对于较小的模型,FA 对 Token/Dollar 的提升更为显著。这是因为注意力机制的成本会随上下文长度变长以平方的速度增长。当模型的隐藏层维度减少时,这个因素变得尤为重要。这样的 SLM,其性能受限于数据处理能力,其中数据在 CPU/GPU、GPU/GPU 之间传输是主要瓶颈。最后,可以看到对于较大的模型(1B 和 2B),FA 能够训练更大的 batch size(1024),而普通注意力会导致内存溢出(OOM)。Q2:GPU 数量一定,哪类 GPU 最适合训练 SLM?
通过多次实验,研究团队得出了以下观察:Q1:在 SLM 训练中使用 FlashAttention 有多重要?图 1 比较了不同 batch size 下 FlashAttention2 与普通注意力的区别。首先,使用 FlashAttention 显著提高了 SLM 的 Token/Dollar 效率,用同样的钱(Dollar)能处理更多数据(Token)。对于较小的模型,FA 对 Token/Dollar 的提升更为显著。这是因为注意力机制的成本会随上下文长度变长以平方的速度增长。当模型的隐藏层维度减少时,这个因素变得尤为重要。这样的 SLM,其性能受限于数据处理能力,其中数据在 CPU/GPU、GPU/GPU 之间传输是主要瓶颈。最后,可以看到对于较大的模型(1B 和 2B),FA 能够训练更大的 batch size(1024),而普通注意力会导致内存溢出(OOM)。Q2:GPU 数量一定,哪类 GPU 最适合训练 SLM?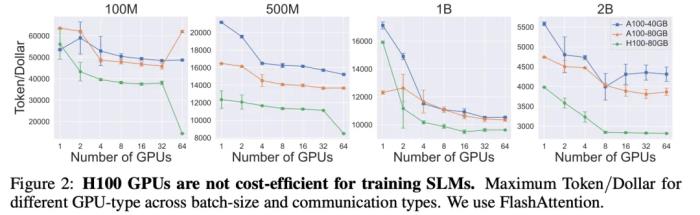 图 2 展示了使用 A100-40GB 和 A100-80GB GPU 训练模型的效果。尽管不同模型间没有统一的趋势,但当使用用大量 GPU 训练 1B、2B 参数规模的模型时,A100-80GB GPU 表现更佳。这种 GPU 适合处理更大的 batch size。对于更小的模型,则可以选择成本更低的 40GB GPU。Q3:在不同节点数量下,哪种通信方案最适合训练 SLM?
图 2 展示了使用 A100-40GB 和 A100-80GB GPU 训练模型的效果。尽管不同模型间没有统一的趋势,但当使用用大量 GPU 训练 1B、2B 参数规模的模型时,A100-80GB GPU 表现更佳。这种 GPU 适合处理更大的 batch size。对于更小的模型,则可以选择成本更低的 40GB GPU。Q3:在不同节点数量下,哪种通信方案最适合训练 SLM?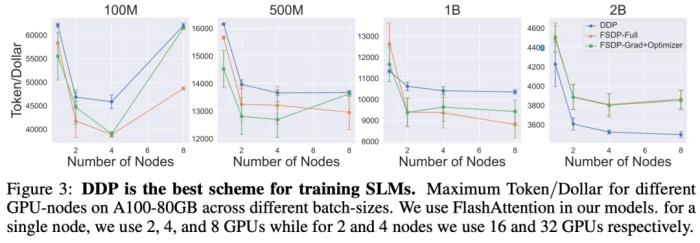 该团队探讨了不同并行策略对 SLM 训练的影响,分布式数据并行(DDP)、完全分片数据并行(FSDP-Full)、还是 FSDPGrad+Optimizer,那种方法更优秀?图 3 展示了在 A100-80GB GPU 上,这些并行策略训练模型的效果。结果显示,对于小型模型,对通信需求最小的 DDP 更优。但对于 2B 参数的模型,FSDP 由于能处理更大的 batch size,表现超越了 DDP。此外,FSDP-Grad+Optimizer 因其较低的通信开销,表现优于 FSDP-Full。简而言之,选择合适的并行策略可以优化 SLM 的训练效率。Q4:对于不同的全局 batch size,训练 SLM 的最佳通信方案是什么?图 4 显示了使用 DDP、FSDP-Full 和 FSDP-Grad+Optimizer 在不同 batch size 下训练 SLM 的结果。
该团队探讨了不同并行策略对 SLM 训练的影响,分布式数据并行(DDP)、完全分片数据并行(FSDP-Full)、还是 FSDPGrad+Optimizer,那种方法更优秀?图 3 展示了在 A100-80GB GPU 上,这些并行策略训练模型的效果。结果显示,对于小型模型,对通信需求最小的 DDP 更优。但对于 2B 参数的模型,FSDP 由于能处理更大的 batch size,表现超越了 DDP。此外,FSDP-Grad+Optimizer 因其较低的通信开销,表现优于 FSDP-Full。简而言之,选择合适的并行策略可以优化 SLM 的训练效率。Q4:对于不同的全局 batch size,训练 SLM 的最佳通信方案是什么?图 4 显示了使用 DDP、FSDP-Full 和 FSDP-Grad+Optimizer 在不同 batch size 下训练 SLM 的结果。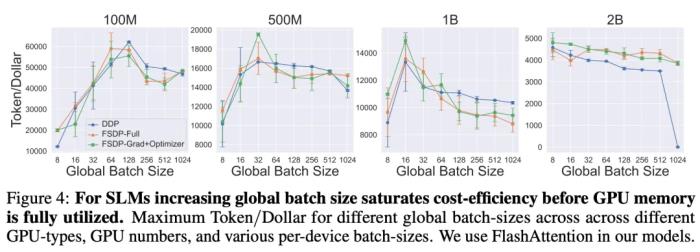 可以看到,batch size 较小时,通信方案的差异不大。然而,与上个问题类似,对于 2B 模型和 batch size,FSDP 方案的性能优于 DDP,并且能够处理比 DDP 更大的批量大小,而 DDP 在这种情况下会导致内存溢出。更多研究细节,请访问原论文。参考链接:https://arxiv.org/pdf/2410.19456
可以看到,batch size 较小时,通信方案的差异不大。然而,与上个问题类似,对于 2B 模型和 batch size,FSDP 方案的性能优于 DDP,并且能够处理比 DDP 更大的批量大小,而 DDP 在这种情况下会导致内存溢出。更多研究细节,请访问原论文。参考链接:https://arxiv.org/pdf/2410.19456 相关推荐


- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。










