新火种
2024-11-16
新火种
2024-11-16 


深度学习时代,Kubernetes调度的创新实践
如今,人工智能领域的开发者越来越多地接受 Kubernetes 作为实际的容器编排工具,当大家共享计算资源时,一个公平调度的方案成为了迫切需求。尤其是在深度学习工作负载需要持续长时间运行的情况下,决定哪位用户将获得下一个 GPU 资源变得尤为关键。一个错误的决策可能导致某些用户或任务长时间无法获得所需资源,这种资源短缺可能对整体业务进度产生负面影响。因此,制定一个合理、公平的调度方案,确保资源分配效率,对于推动人工智能开发的顺利进行至关重要。
01
调度问题有哪些
在本文中,我们将从以下几个方面为大家解释关于调度的相关问题:
Kubernetes 调度 Pod 的方式
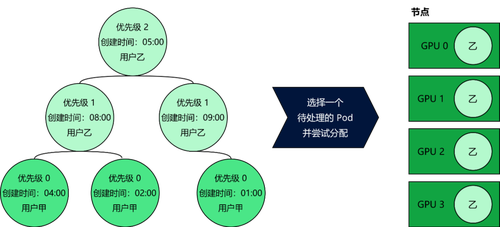
简单来说,Kubernetes 调度器会选择一个状态为 pending 的 Pod,然后尝试将这个 Pod 绑定到最合适的节点上,但调度器是如何挑选正确 Pod 的呢?默认的调度器将状态为 pending(挂起)的那些 Pod 存储在一个堆数据结构中。这个堆会根据 Pod 的优先级和创建时间对 Pod 进行排序,并按照这个顺序进行资源的分配。如果在共享集群中使用默认的 Kubernetes 调度器,在 GPU 数量有限时,可能会引起公平性问题,因为某些任务很容易垄断整个集群的资源。
垄断 GPU 集群的方法
优先级:用户垄断 GPU 集群的一种方法是提交设置为最高优先级的 Pod。这时,他们的 Pod 会移到堆的顶部,从而首先被分配。最终,优先级高的用户就可以垄断并使用集群中的所有 GPU。
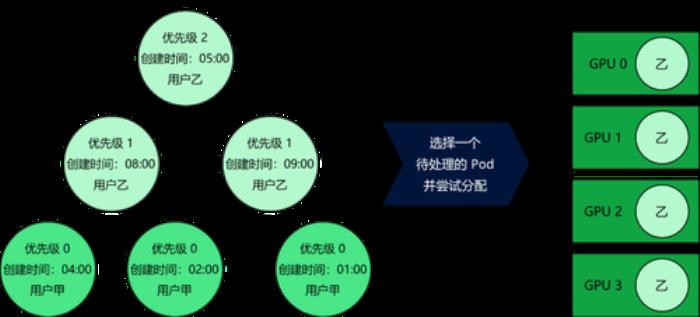
批量提交:垄断 GPU 集群的另一种方式是尽可能多地提交 Pod。这样会导致堆中有更多的 Pod,并且缩短它们的创建时间。堆中的 Pod 数量越多, GPU 资源分配也就越多。

基于上述两种情况的出现,为了防止集群的垄断,需要构建一个调度程序,它可以在用户之间公平地共享 GPU 资源,而不管创建时间和 Pod 优先级如何。
02
Kubernetes
调度框架
Kubernetes 的 V1.15 版本对调度器的架构进行了重大调整,采用了新的调度框架。这一框架采用了更为模块化的设计思路,提供了多个扩展接口,允许用户根据需要调整调度器的工作方式。这一变化对于寻求默认调度器替代方案的开发者来说是一个巨大的突破,因为它简化了开发流程,减少了从零开始构建调度器并持续集成 Kubernetes 新特性的工作量。
在 d.run 算力一体化方案中,「DaoCloud 道客」重新评估了这个新的调度框架,最终决定对此调度策略做升级。我们认为现有的堆结构限制了我们的调度策略,无法满足我们对调度灵活性和效率的特定需求,并希望对此进行改进优化调度过程,提高资源分配的效率和智能性。
03
d.run 调度策略
d.run 除了基础的 Kubernetes 调度之外,还结合了开源项目 Kueue 的调度策略,可以采用公平调度、亲和、组调度、紧凑等调度算法来应对不同的算力场景。这避免了 GPU 资源浪费、大任务长期占用影响小任务资源使用、碎片化资源的浪费等常见的 GPU 利用率低下的问题。
GPU 资源优化
d.run 支持单块物理卡切分给不同的租户使用,并支持按照算力、显存进行 GPU 资源配额,这让单个任务可以使用更多的 GPU 资源而无需关心本身的 GPU 数量。用户在部署应用时可按照 1% 的算力颗粒度和 1MB 的显存颗粒度极致压榨 GPU 资源,这有效提高资源利用率。同时,它还可以支持集群、节点、应用等多维度 GPU 资源的可视化监控,能够帮助运维人员更好地管理 GPU 资源。
GPU 调度的分配算法和抢占算法
为了尽可能保障资源的公平分配,我们会根据具体的应用场景和性能要求采用不同的调度算法。这里简单介绍两种常见的调度算法:分配算法和抢占算法。
1. 分配算法:
静态分配:在任务开始之前,根据任务的特性和需求,预先分配 GPU 资源。这种方法的优点是可以避免运行时的调度开销,但缺点是不够灵活,难以适应任务执行过程中的变化。
动态分配:根据任务的实际执行情况,实时调整资源分配。这种方法更加灵活,能够更好地适应任务需求的变化,但可能会增加调度的复杂性和开销。
2. 抢占算法:
抢占式调度:允许调度器在任务执行过程中,根据某些策略(如优先级、资源使用情况等)中断当前任务,将资源重新分配给其他任务。这种方法可以提高资源的利用率,但可能会导致任务执行的延迟增加。
非抢占式调度:任务一旦开始执行,就会持续运行直到完成,不会在中途被中断。这种方法的优点是可以减少任务切换的开销,但可能会导致资源长时间被单一任务占用,影响其他任务的执行。
在需要高吞吐量和实时性的场景中,可能会采用动态分配和抢占式调度;而在需要低延迟和高确定性的场景中,则可能更倾向于静态分配和非抢占式调度。
在 Kubernetes 中实现深度学习工作负载的公平调度是一项复杂但至关重要的任务。我们通过理解 Kubernetes 调度框架的演变,并在 d.run 平台上整合多种调度策略,助力构建一个高效且公平的算力调度引擎,以适应不同的业务需求。这种综合调度策略的实施,确保了资源的高效利用和公平分配,避免了资源浪费和任务执行的延迟,为深度学习工作负载提供了一个强大而灵活的解决方案。
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。