

 新火种
2024-11-15
新火种
2024-11-15 


DenseNet共一作者刘壮官宣新去向,将任普林斯顿大学助理教授
「还离这世界上最棒的地儿不远。」
最新消息,DenseNet 作者之一刘壮将于 2025 年 9 月加盟普林斯顿大学,担任计算机科学系助理教授一职。
刘壮主导了 DenseNet 和 ConvNeXt 的开发,这两款模型如今已成为深度学习和计算机视觉领域最主流的神经网络架构之一。
在正式踏入学术界之前,刘壮还会在 Meta AI Fair 继续担任研究科学家。因为普林斯顿大学离纽约不远的,刘壮在官宣新去向后,还晒了张地图:「我离这世界上最棒的地儿不远。」
田渊栋等各路大佬第一时间齐刷刷地送上了祝福:
在 AI 技术骨干纷纷离职单飞,投入 AI 创业大军的时候,拥抱学术界的选择似乎并不多见。
大三就提出了 DenseNet
2013 年,刘壮以安徽省理科高考第一名的成绩,考进了清华大学计算机科学实验班(姚班)。大三期间,在康奈尔大学访学的刘壮与黄高合作了 DenseNet,这篇论文后来成为了 CVPR 2017 的最佳论文。

在 CVPR 还没「通货膨胀」的时代,突破了传统深度网络的单向直链结构的 DenseNet 在 CV 圈掀起了一阵热潮。

论文链接:https://arxiv.org/pdf/1608.06993
DenseNet 通过将前面所有层与后面的层进行密集连接,实现了特征重用,不仅缓解了随着网络深度增加产生的梯度消失现象,也能让网络以更少的参数和计算量实现更优的性能。
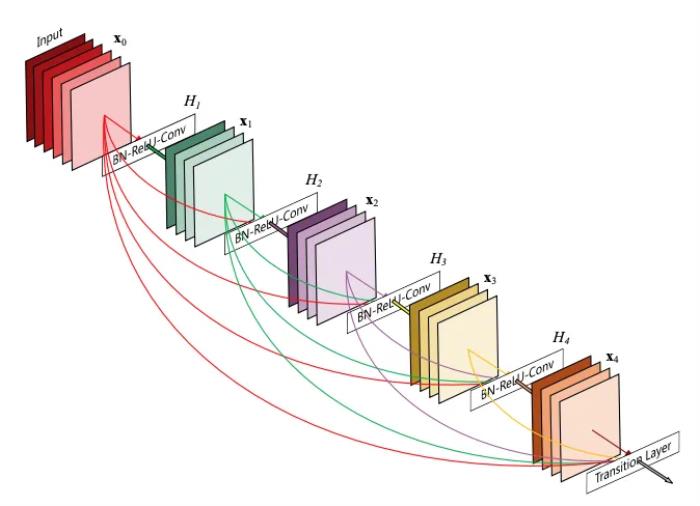
DenseNet网络结构
在学术界,DenseNet 被图灵奖得主 Yann LeCun 与 VGG、GoogleNet、ResNet 并列为当代四种主流深度网络。至今,DenseNet 的论文引用量超过 4.8 万次,成为了教科书上的范本。
2017 年,从清华毕业后,刘壮前往加州大学伯克利分校深造博士学位,拜入 Trevor Darrell 教授门下,和贾扬清成为了同门师兄弟。读博期间,刘壮笔耕不辍,入选顶会的论文源源不断,其中不少还获选 Spotlight。
博士毕业后,刘壮进入 Meta AI Research 工作。在此之前,他曾在康奈尔大学、英特尔实验室、Adobe Research 和 FAIR 担任访问研究员 / 实习生。
在 Meta 实习期间,刘壮和谢赛宁合作,发表了 ConvNeXt,这是一篇「make CNN great again」的代表性工作。

论文链接:https://arxiv.org/pdf/2201.03545
自从 ViT 提出,视觉识别开启了「咆哮的 20 年代」,基于 Transformer 的模型在计算机视觉的各个领域开始全面超越 CNN。然而,这种混合方法的有效性在很大程度上仍归功于 Transformer 的内在优势,而不是卷积固有的归纳偏置。
那么,纯 ConvNet 的极限在哪里?能否设计一个纯 CNN 模型,让它实现和基于 Transformer 的视觉模型同样的效果呢?
刘壮及其研究团队参考了 Swin Transformer,基于标准 ResNet,升级出了 ConvNeXt。无论在图像分类还是检测分割任务上,ConvNeXt 均超过了 Swin Transformer,同时还能保持标准 ConvNet 的简单性和有效性。
入职 Meta 后,刘壮似乎更加高产,对数据集以及(多模态)大型语言模型也产生了研究兴趣。

近期,他和何恺明关于数据集偏差的研究也引发了广泛关注。

论文链接:https://arxiv.org/abs/2403.08632
论文的结论指出:虽然业界为构建更多样化、更全面的数据集付出了诸多努力,但神经网络似乎越来越善于「过拟合」到特定的数据集上,也就是说,AI 更加擅长用一种「模板答案」来套不同的数据集中的题目了。
正如刘壮在主页所说:「我的研究经常挑战现有的观念(例如,架构、数据集、剪枝、训练)」。未来在学术界,刘壮将会在哪些方向上发出新挑战,让我们拭目以待。
参考链接:
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。










