

 新火种
2024-11-15
新火种
2024-11-15 


无需训练即可创建数字人,字节PersonaTalk视频口型编辑超SOTA
在 AIGC 的热潮下,基于语音驱动的视频口型编辑技术成为了视频内容个性化与智能化的重要手段之一。尤其是近两年爆火的数字人直播带货,以及传遍全网的霉霉讲中文、郭德纲用英语讲相声,都印证着视频口型编辑技术已经逐渐在行业中被广泛应用,备受市场关注。
近期,字节跳动一项名为 PersonaTalk 的相关技术成果入选了 SIGGRAPH Asia 2024-Conference Track,该方案能不受原视频质量的影响,保障生成视频质量的同时兼顾 zero-shot 技术的便捷和稳定,可以通过非常便捷高效的方式用语音修改视频中人物的口型,完成高质量视频编辑,快速实现数字人视频制作以及口播内容的二次创作。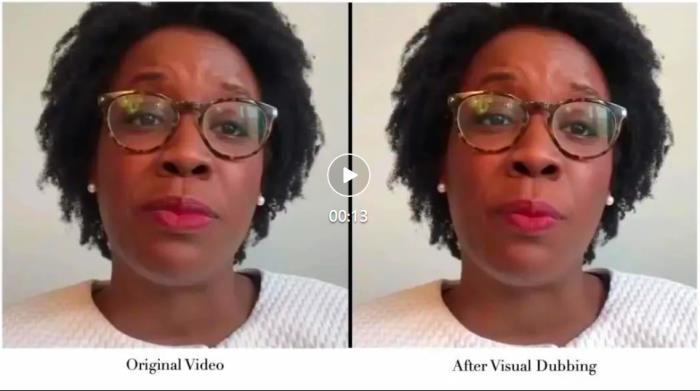
肖像来自学术数据集 HDTF
目前的视频改口型技术大致可以分为两类。一类是市面上最常见的定制化训练,需要用户首先提供 2-3mins 的人物视频数据,然后通过训练让模型对这段数据中的人物特征进行过拟合,最终实现该数据片段中人物口型的修改。这类方案在效果上相对成熟,但是需要耗费几个小时甚至几天的模型训练时间,成本较高,很难实现视频内容的快速生产;与此同时,这类方案对人物视频的质量要求往往偏高,如果视频中的人物口型动作不标准或者环境变化太复杂,训练后的效果会大打折扣。除了定制化训练之外,还有另一类 zero-shot 方案,可以通过大量数据来对模型进行预训练,让模型具备较强的泛化性,在实际使用的过程中不需要再针对特定人物去做模型微调,能做到即插即用,成功解决了定制化方案成本高,效果不鲁棒的问题。但这类方案大都把重点放在如何实现声音和口型的匹配上,往往忽略了视频生成的质量。这会导致一个重要的问题,最终生成的视频不论是在外貌等面部细节,还是说话的风格,跟本人会有明显的差异。
PersonaTalk 作为一项创新视频生成技术,构建了一个基于注意力机制的双阶段框架,实现了这两类方案优势的统一。
 论文链接:https://arxiv.org/pdf/2409.05379项目网页:https://grisoon.github.io/PersonaTalk技术方案为了达到上述目标,技术团队首先用一个风格感知的动画生成模块(Style-Aware Geometry Construction)在 3D 几何空间生成人物的口型动画序列;然后通过一个双分支并行的注意力模块(Dual-Attention Face Rendering)进行人像渲染,生成最终的视频。
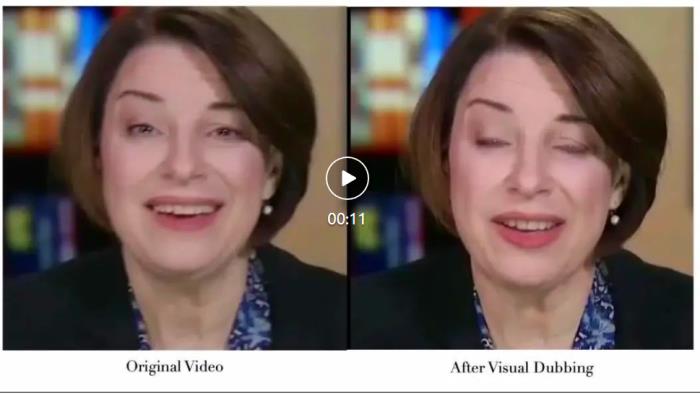
论文链接:https://arxiv.org/pdf/2409.05379项目网页:https://grisoon.github.io/PersonaTalk技术方案为了达到上述目标,技术团队首先用一个风格感知的动画生成模块(Style-Aware Geometry Construction)在 3D 几何空间生成人物的口型动画序列;然后通过一个双分支并行的注意力模块(Dual-Attention Face Rendering)进行人像渲染,生成最终的视频。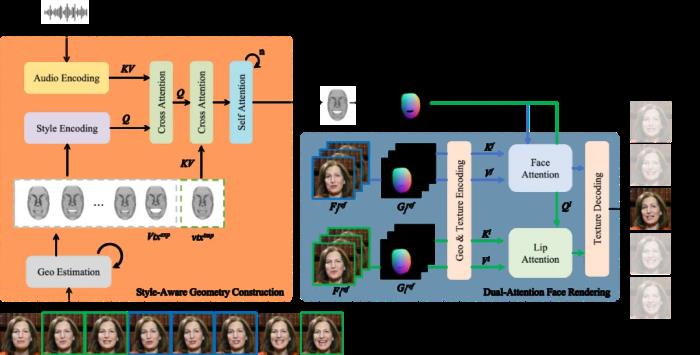 肖像来自学术数据集 HDTFStyle-Aware Geometry Construction:这一阶段的目标是在 3D 几何空间中生成具备人物风格的人脸动画。除了通过常规的语音信号来控制生成结果,这里还从参考视频中提取说话者个性化的面部特征并分析出特征的统计特性,通过 Cross Attention 注入到模型中,来引导生成的动画具备说话者本人的面部运动风格。此外,文中还提出了一种 Hybrid 3D Reconstruction 方案,通过结合深度学习和迭代式优化的方法,来提升人脸三维重建的精度和稳定性。Dual-Attention Face Rendering:在渲染过程中,作者团队创新性地设计了两个并行的注意力模块 Face-Attention 和 Lip-Attention,通过 Cross Attention 来融合 3D 动画和人物参考图特征,分别渲染脸部和嘴部的纹理。在推理过程中,文中还针对这两个模块分别设计了参考图挑选策略,其中人脸部分参考图从以当前帧为中心的一个滑动窗口中来获取,以此降低人脸纹理的采集和生成难度,确保视频画面的稳定性和保真度;口型部分则是先按照口型张幅大小对整个视频中的人脸进行排序,然后均匀挑选出不同张幅的口型图片组成一个集合,以确保口腔内的信息可以被完整性获取。实验效果对比在实验章节中,该研究从多个方面详细对比了 PersonaTalk 和其他市面上 SOTA 方案,以此来证明该方法的有效性。从视频效果和定量指标上看,PersonaTalk 在唇动同步、视觉质量与个性化特征保留方面均表现突出,明显优于其他 zero-shot 方法。
肖像来自学术数据集 HDTFStyle-Aware Geometry Construction:这一阶段的目标是在 3D 几何空间中生成具备人物风格的人脸动画。除了通过常规的语音信号来控制生成结果,这里还从参考视频中提取说话者个性化的面部特征并分析出特征的统计特性,通过 Cross Attention 注入到模型中,来引导生成的动画具备说话者本人的面部运动风格。此外,文中还提出了一种 Hybrid 3D Reconstruction 方案,通过结合深度学习和迭代式优化的方法,来提升人脸三维重建的精度和稳定性。Dual-Attention Face Rendering:在渲染过程中,作者团队创新性地设计了两个并行的注意力模块 Face-Attention 和 Lip-Attention,通过 Cross Attention 来融合 3D 动画和人物参考图特征,分别渲染脸部和嘴部的纹理。在推理过程中,文中还针对这两个模块分别设计了参考图挑选策略,其中人脸部分参考图从以当前帧为中心的一个滑动窗口中来获取,以此降低人脸纹理的采集和生成难度,确保视频画面的稳定性和保真度;口型部分则是先按照口型张幅大小对整个视频中的人脸进行排序,然后均匀挑选出不同张幅的口型图片组成一个集合,以确保口腔内的信息可以被完整性获取。实验效果对比在实验章节中,该研究从多个方面详细对比了 PersonaTalk 和其他市面上 SOTA 方案,以此来证明该方法的有效性。从视频效果和定量指标上看,PersonaTalk 在唇动同步、视觉质量与个性化特征保留方面均表现突出,明显优于其他 zero-shot 方法。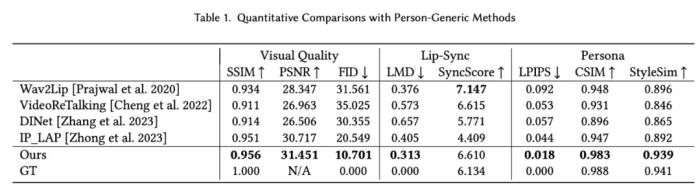
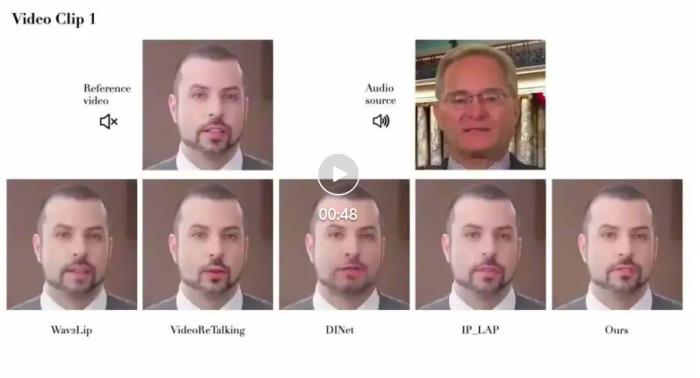 肖像来自学术数据集 HDTF 以及自有版权数据同时,PersonaTalk 作为一个不需要额外训练和微调的方案,在视频结果的表现上甚至优于学术界最新的定制化训练方案。
肖像来自学术数据集 HDTF 以及自有版权数据同时,PersonaTalk 作为一个不需要额外训练和微调的方案,在视频结果的表现上甚至优于学术界最新的定制化训练方案。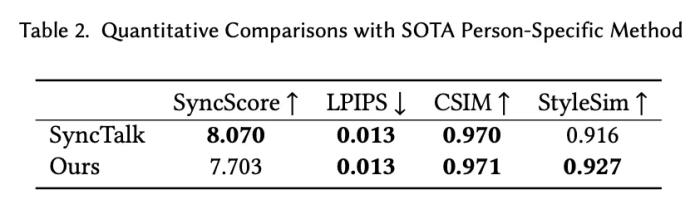
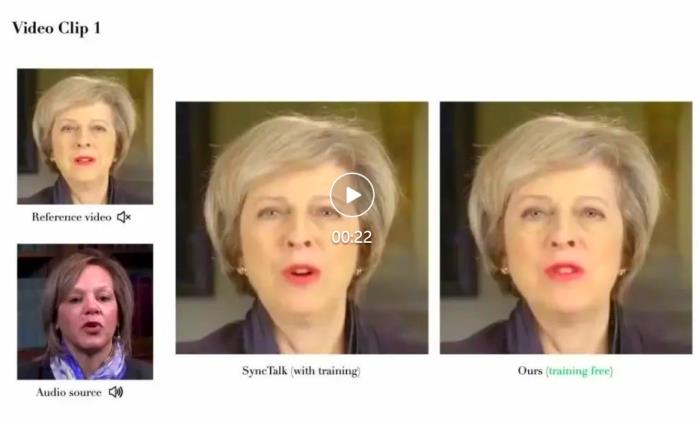 肖像来自学术数据集 HDTF 及网络公开数据此外,作者团队通过对目标用户进行问卷调查和访谈,收集了对 PersonaTalk 生成内容的反馈,结果显示大多数用户对视频质量感到满意,认为其足够逼真且高度还原了人物特征。
肖像来自学术数据集 HDTF 及网络公开数据此外,作者团队通过对目标用户进行问卷调查和访谈,收集了对 PersonaTalk 生成内容的反馈,结果显示大多数用户对视频质量感到满意,认为其足够逼真且高度还原了人物特征。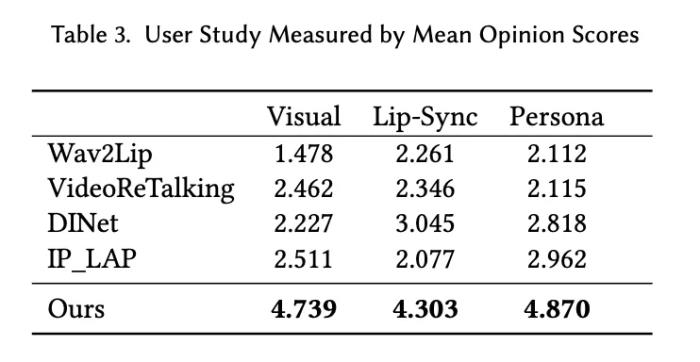 更多应用该项研究可以应用在视频翻译、虚拟教师、AIGC 创作等多个场景。以下数据均来自于网络公开数据或 AIGC 生成。虚拟教师
更多应用该项研究可以应用在视频翻译、虚拟教师、AIGC 创作等多个场景。以下数据均来自于网络公开数据或 AIGC 生成。虚拟教师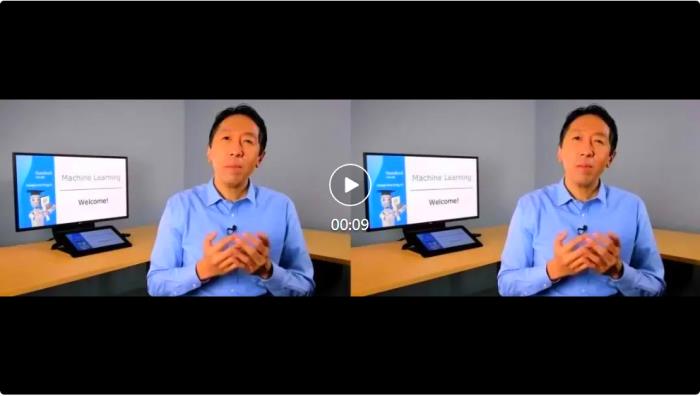
 原视频 介绍 Deep Learning 课程AIGC 创作
原视频 介绍 Deep Learning 课程AIGC 创作


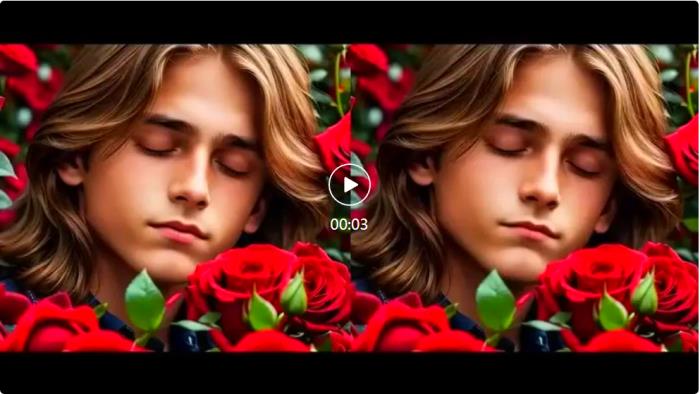 结论PersonaTalk 通过注意力机制的双阶段框架,有效突破了已有视频口型编辑技术的瓶颈,可以用很低的成本来生成高质量的人物口播视频,实现了效果和效率的兼顾。PersonaTalk 不仅具有广泛的应用前景,还为多领域的创新提供了新思路。无论是在娱乐、教育、广告等行业,都能实现更加个性化和互动式的用户体验。随着技术的不断发展,相信 PersonaTalk 将使视频内容以及数字人创作变得更加生动、真实,从而拉近虚拟世界与现实生活之间的距离。通过整合先进的音频技术和深度学习算法,PersonaTalk 也正在开启一种全新的视听交互方式,让交流变得更加丰富与多元化。安全说明此工作仅以学术研究为目的,会严格限制模型的对外开放和使用权限,防止未经授权的恶意利用。文中使用的图片 / 视频均已注明来源,如有侵权,请联系作者及时删除。团队介绍字节跳动智能创作数字人团队,智能创作是字节跳动 AI & 多媒体技术团队,覆盖了计算机视觉、音视频编辑、特效处理等技术领域,借助公司丰富的业务场景、基础设施资源和技术协作氛围,实现了前沿算法 - 工程系统 - 产品全链路的闭环,旨在以多种形式为公司内部各业务提供业界前沿的内容理解、内容创作、互动体验与消费的能力和行业解决方案。其中数字人方向专注于建设行业领先的数字人生成和驱动技术,丰富智能创作内容生态。目前,智能创作团队已通过字节跳动旗下的云服务平台火山引擎向企业开放技术能力和服务。更多大模型算法相关岗位开放中。
结论PersonaTalk 通过注意力机制的双阶段框架,有效突破了已有视频口型编辑技术的瓶颈,可以用很低的成本来生成高质量的人物口播视频,实现了效果和效率的兼顾。PersonaTalk 不仅具有广泛的应用前景,还为多领域的创新提供了新思路。无论是在娱乐、教育、广告等行业,都能实现更加个性化和互动式的用户体验。随着技术的不断发展,相信 PersonaTalk 将使视频内容以及数字人创作变得更加生动、真实,从而拉近虚拟世界与现实生活之间的距离。通过整合先进的音频技术和深度学习算法,PersonaTalk 也正在开启一种全新的视听交互方式,让交流变得更加丰富与多元化。安全说明此工作仅以学术研究为目的,会严格限制模型的对外开放和使用权限,防止未经授权的恶意利用。文中使用的图片 / 视频均已注明来源,如有侵权,请联系作者及时删除。团队介绍字节跳动智能创作数字人团队,智能创作是字节跳动 AI & 多媒体技术团队,覆盖了计算机视觉、音视频编辑、特效处理等技术领域,借助公司丰富的业务场景、基础设施资源和技术协作氛围,实现了前沿算法 - 工程系统 - 产品全链路的闭环,旨在以多种形式为公司内部各业务提供业界前沿的内容理解、内容创作、互动体验与消费的能力和行业解决方案。其中数字人方向专注于建设行业领先的数字人生成和驱动技术,丰富智能创作内容生态。目前,智能创作团队已通过字节跳动旗下的云服务平台火山引擎向企业开放技术能力和服务。更多大模型算法相关岗位开放中。 相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。










