

 新火种
2024-11-15
新火种
2024-11-15 


穹彻智能-上交大最新Nature子刊速递:解析深度学习驱动的视触觉动态重建方案
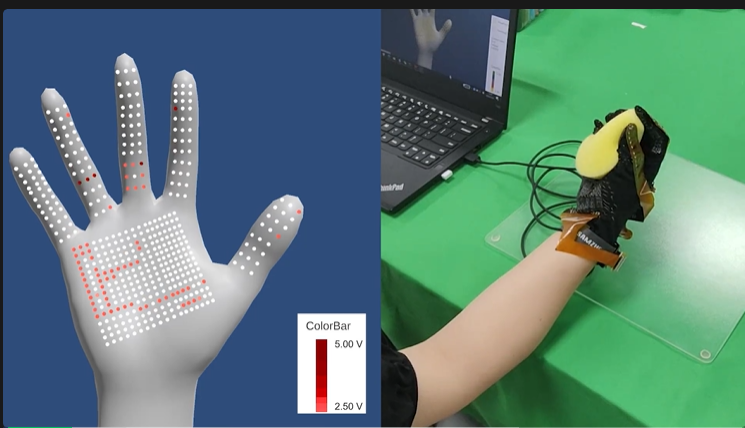
随着人形机器人技术的迅猛发展,如何有效获取高质量的操作数据成为核心挑战。鉴于人类操作行为的复杂性和多样性,如何从真实世界中精准捕捉手与物体交互的完整状态,成为推动人形机器人操作技能学习的关键所在。面对这一挑战,穹彻智能携手上海交通大学卢策吾和刘景全团队,创新性地提出了名为 ViTaM 的视觉-触觉联合记录和追踪系统。该系统包括高密度可伸缩触觉手套和基于视觉-触觉的联合学习框架,不仅在触觉手套的设计和制造上实现了技术突破,更通过视觉与触觉的深度融合,为理解手物交互过程状态提供了全新的视角和强大工具。
在人形机器人操作领域,有一个极具价值的问题:鉴于操作数据在人形操作技能学习中的重要性,如何有效地从现实世界中获取操作数据的完整状态?
如果可以,那考虑到人类庞大规模的人口和进行复杂操作的简单直观性与可扩展性,人形机器人再也不用担心没有高质量的操作数据资源了。
穹彻智能携手上海交通大学卢策吾和刘景全团队意识到,分布式触觉技术对于重建完整人类操作至关重要,当操作被遮挡时,触觉可以作为视觉的有效补充,从而一同还原出操作区域的形变状态、接触力位点和大小。因此,该团队提出了一种全新的视觉 - 触觉联合记录和追踪系统 ViTaM(为 Visual-Tactile recording and tracking system for Manipulation 的缩写),包括一个可伸缩的触觉手套,与一个基于视觉 - 触觉的联合学习框架。文章在 24 个物体样本中进行实验,涵盖了 6 个类别,包含刚性物体和可形变物体,重建误差均值仅为 1.8 厘米。
ViTaM 系统在未来发展中,有望被深度集成至机器人的电子皮肤之中,从而赋予机器人与周围环境进行无缝互动的能力。这不仅能够使机器人实时感知并精准响应多样化的环境刺激,更将极大提升其在复杂场景下的灵巧操作水平,推动智能机器人技术迈向更加先进和实用的新阶段。

- 论文名称:Capturing forceful interaction with deformable objects using a deep learning-powered stretchable tactile array
- 论文链接:https://www.nature.com/articles/s41467-024-53654-y
- 项目地址:https://github.com/jeffsonyu/ViTaM
演示视频:




可以看到,对于刚体和可形变物体,系统都能进行高水准的重建,也同时适用于不同类型的物体,如纸杯,橡皮泥,剪刀等日常生活中常见的物体。
ViTaM 方法详解

图 1:A 人机交互中涉及人类操作的(i)无力交互和(ii)有力交互的任务及其响应结果。B ViTaM 系统概述:(i) 受人类启发的联合感知方法,在操作过程中同时处理跨模态的视觉和触觉信号,以实现状态跟踪;(ii) 可拉伸界面的应变导致的传感误差,它降低了力测量的精度和触觉传感器的应用效果;(iii) 触觉记录方案,包括具有主动应变干扰抑制功能的高密度可拉伸触觉手套,以及用于显式分布式力检测结果的 VR 界面;(iv) 由深度学习驱动的物体状态估计应用,能够重建物体的整体几何形状和接触区域的细粒度表面形变,特别是对于可形变物体。
ViTaM 系统核心挑战是要解决在与可形变物体进行带力交互时如何捕捉细粒度信息,当可形变物体能被正确捕捉时,刚性部件的交互就自然迎刃而解了。
该系统利用一个高密度、可拉伸触觉手套和一个 3D 相机记录操作过程,并利用一个视觉 - 触觉联合学习框架在几何层面上估计手 - 物体的状态。高密度触觉手套最多有 1152 个触觉传感通道分布在手掌上,当与物体交互时,会记录接触区域的手部物体状态,并以 13Hz 的帧速率准确捕捉手物交互过程中可拉伸界面上的力分布和动态(图 1B (iii))。同时,非接触区域的手与物体状态可以由高精度深度摄像头记录。
捕捉到的力测量和点云序列,经过视觉 - 触觉学习模型处理,融合跨模态数据特征,最终实现对不同形变材料的被操作物体的跟踪和几何三维重建(图 1B (iv))。
A. 硬件设计:触觉手套的设计与制造
在高精度触觉反馈系统中,如何准确地捕捉并传递手部与物体之间的交互力,一直是硬件设计中的一个核心挑战。特别是在涉及复杂手部运动和多点压力分布的情况下,传统的传感器系统往往难以满足高灵敏度和高可靠性的需求。因此,开发一款能够精确感知触觉信息并支持多通道力传感的手套式硬件设备显得尤为重要。受到现有触觉手套技术启发,团队研发了这一款创新的触觉手套系统。该手套包括多个模块(如图 2A 所示):触觉传感模块、织物手套、柔性印刷电路(FPC)、多通道扫描电路、处理电路以及一个腕带。系统设计的核心目标包括:
- 高效的数据传输与灵活的系统扩展:手套的设计采用模块化结构,便于根据不同需求调整传感器的密度或进行拆卸。其中,三种类型的 FPC 分别连接手指与掌心传感区域,支持最大 1152 个传感单元(原型系统配备 456 个传感单元)。
- 触觉传感的高精度与准确性:系统包含了力传感电路和应变干扰检测电路,以保证触觉数据的高精度采集与处理,这些传感器通过导电织物线路连接,形成行列电极阵列,以实现准确的力感应和应变测量。
- 人体工学舒适性:为了提高触觉手套的舒适性和适配性,采用了先进的织物传感技术,避免了传统方法中常见的胶层分层问题。每个触觉传感模块由正负应变传感器和力传感器阵列构成(图 2B)。这种全织法组装方式不仅提高了手套的耐用性和穿戴感,还使得手套更加适应复杂的手部运动和操作环境。
- 低成本与量产潜力:在系统的整体设计中,触觉手套经过多次测试验证,原型版的准确率达到 97.15%,证明其足以满足大多数人机交互应用的需求。成本方面,触觉手套的单价为 3.38 美元,而硬件总成本为 26.63 美元,使得该产品具备了较高的性价比,并有望广泛推广。通过加工工艺的逐步简化以及生产自动化技术的实现,该触觉手套在未来有着较大的量产潜力。
该触觉手套系统不仅能够精确捕捉力感信息,还具备高适配性和舒适性,适用于多种实际应用场景,如虚拟现实、机器人操作及医疗领域等。

图 2:触觉手套的具体设计:A. 最大传感通道为 1152 的高密度可拉伸触觉手套的放大示意图;B. (i) 带有两对应变电极、行电极阵列和列电极阵列的触觉传感块的结构;(ii) 显示应变电极位置的放大图;(iii) 显示紧密装配的触觉传感块侧视图。
B. 视觉 - 触觉联合学习在人类操作中的应用
在操作可形变物体时,手部与物体接触的力分布能够帮助揭示因形变而发生的几何变化。然而,由于形变区域几乎具备无限的自由度,完全估算物体形变的几何形状一直是一个难题。尽管触觉手套能够测量接触区域的分布力并帮助感知形变,但其覆盖范围仅限于部分物体表面,且即便是高密度、分布式的传感器网络也难以全面捕捉物体的完整几何信息。因此,团队认为,还需要视觉观测来弥补这一不足,从而恢复完整的物体几何形态。此类视觉 - 触觉交互机制与人类的认知过程高度相似。
团队提出了一种视觉 - 触觉联合学习框架,旨在手 - 物体重建和跟踪中恢复物体几何信息,尤其是在高度非刚性形变的情况下。该框架通过结合触觉数据和视觉信息,能够有效重建被手部遮挡或形变的物体细节。为了评估这一框架,团队制作了一个视觉 - 触觉数据集,包括 7680 个样本,涵盖 24 种物体、6 个类别。数据集中包括海绵、橡皮泥、瓶子和杯子等可形变物体,以及折叠架和剪刀等刚性物体。每个物体都进行了 20 次触摸,并通过 16 个不同的摄像头视角进行了记录。训练数据来自 RFUniverse,它支持基于有限元方法(FEM)的仿真,测试数据则来源于实际操作。

图 3: 该模型包含手部重建器、特征提取器、时间特征融合器和绕数场(WNF)预测器。全局和局部特征均从视觉和触觉输入中提取,并基于手部的区块位置。团队将这些特征融合在一起,利用时间交叉注意模块计算每点特征,预测采样位置的 WNF,并通过行进立方体算法重建物体几何形状。
实验验证
团队从两方面验证了系统的有效性:触觉手套与可形变物体交互分析,以及视觉 - 触觉联合学习的物体重建效果评估。
A. 触觉手套与可形变物体交互分析
为了验证触觉手套的性能,团队设计了一个动态的饺子制作任务,使用软橡皮泥作为高度可形变的物体进行实验。该任务包括将橡皮泥揉成球状,然后将其压成扁平形状(作为饺子皮),最后用手指捏合皮边。首先,当手掌将橡皮泥揉成球状时,图 4A 展示了手掌传感区域(称为手掌块)的归一化压力变化。其次,在手掌按压橡皮泥球时(图 4B),经过应变干扰校正后的归一化压力高于未经校正的结果。第三,将饺子皮对折并用拇指和食指捏合边缘(图 4C)。归一化的捏合压力显示,经过校正的压力曲线在三个子阶段明显增加,这可能是由于形变带来的显著应变和未校正的压缩力减少所致。
此外,团队还研究了在需要手指与手掌协作的操作中,应变干扰校正前后的触觉传感块表现。例如,在反复捏合并释放海绵时(图 4D)。未校正的操作只涉及六个活跃的手指块和九个活跃的手掌块,这些块的相关系数大于 85%(图 4E (i))。经过校正后,团队发现了两个额外活跃的手指块和五个手掌块(图 4E (ii))。图 4F (i) 展示了校正前活跃块的归一化压力变化,图 4F (ii) 则展示了校正后压力变化较小的块。Spearman 相关性结果分别展示了未校正和校正后的数据(图 4G (i) 与图 4G (ii))。位于中指远端指骨上的块 3-1 与其他块的相关性最高。校正后,出现了更多的相关性,表明所有手指块在捏合海绵时都发挥了作用,尤其是块 2-2、块 5-1、块 5-2 和块 5-3。像块 3-1 和块 2-1 这样的块,在校正后相关系数增加超过 85%,这表明相关块之间的协同效应得到了增强。图 4H 展示了校正后强相关数量的增加,进一步说明了即使在应变干扰的情况下,校正也有助于深入挖掘不同手指与手掌之间的依赖关系。
触觉手套还能够在操作过程中帮助估计物体形状,尤其是在抓取各种物体时 —— 无论是软物体(如塑料滴管、毛巾、塑料瓶)还是硬物体(如画笔、勺子、小针)。在虚拟现实界面中,可以明显看到沿物体边缘的力反应。
团队还考虑了手部姿态的干扰。图 5-1 与 5-2 分别比较了两种典型动作 —— 揉捏面团和抓取海绵 —— 在空手姿态和与真实物体交互时的归一化压力曲线。与空手姿态相比,实际交互时的归一化压力曲线分别增加了 12 倍、16 倍和 6 倍。较低幅度的噪声可以通过视觉 - 触觉联合学习框架轻松滤除。在监督学习设置下,相关信号(例如接触重建)得到增强,不相关信号则被抑制。

图 4:包饺子任务以及三个动作的触觉反应和归一化压力结果:(A) 揉、(B) 压和 (C) 捏。D 反复捏放可形变海绵的抓取任务照片。E 海绵抓取任务中主动触觉传感块的分布(i)不含应变干扰抑制,(ii)含应变干扰抑制。F (i) 未进行应变干扰抑制的主动块和 (ii) 抑制后进一步显示的块的归一化压力曲线。G 海绵抓取任务中(i)无应变干扰抑制时和(ii)有应变干扰抑制时斯皮尔曼相关分析的弦图像。H 校正前后所有手指区块和手掌区块的强相关数量。

图 5-1:(A) 揉捏操作中的手部姿势任务和 (B) 实际揉面动作与归一化压力曲线。

图 5-2:(A) 在抓取操作中的手部姿势任务和 (B) 实际抓取海绵时的压力曲线。
B. 视觉 - 触觉联合学习的物体重建效果评估
为了验证 ViTaM 系统的有效性,研究者们进行了定性和定量对比测试,以回答以下问题:(1) 特定于触觉阵列的数据格式是否能有效地向学习算法传递几何信息?(2) 与其他形式的传感器(如 RGB-D 相机或光学触觉传感器)相比,它是否更有效?
a) 定性结果
为了展示提出的联合学习框架的有效性,团队展示了两个弹性物体(海绵)和一个刚性物体(剪刀)的接触物体重建。从图 6A 中可以看到,真实数据中的手和物体都得到了很好的重建,而且在触觉信息的帮助下,还可以重建手部遮挡的细节形状。更重要的是,在应变干扰抑制后,基于触觉反馈重建的可形变海绵可以在应变明显的区域显示出更多微小细节,而且由于应变干扰抑制方法有助于恢复施加在刚性边缘上的真实微小力,刚性物体的完整性也得到了改善。图 6B 展示了逐渐形变的塑性体,它代表了捏饺子皮的包饺子任务。塑性体在每个步骤中的形变都得到了很好的展示。在图 6C 中,团队重建了一个刚性折叠架,该折叠架采用了手与物体上不同位置的多次接触。折叠架的细节是通过多次接触与迭代触觉信息嵌入(tactile embedding)来逐步完成的。此外,为了证明视觉 - 触觉联合学习的必要性,在图 6D 中展示了剪刀、折叠架和瓶子的纯视觉结果和视觉 - 触觉结果。得益于视觉和触觉特征的结合,刚性和可形变物体都得到了很好的重构。在图 6E 中,重建的序列证明研究者所提出的方法能够处理多帧的连续数据。因此,该视觉 - 触觉模型性能的提高证明,引入应变干扰抑制的触觉信息对于获得手部遮挡的特征和获取可拉伸界面上物体的动态形变都是至关重要的。

图 6:A. 在没有应变干扰抑制和有应变干扰抑制的情况下,两块弹性海绵和一把刚性剪刀的接触物体重建。B. 在没有应变干扰抑制和有应变干扰抑制的情况下,用手操作逐渐形变的饺子形塑性体的三个重建阶段。C. 手在物体不同位置多次接触后重建的刚性折叠架。D. 剪刀、架子和瓶子的纯视觉和视觉 - 触觉重建结果,显示了视觉 - 触觉关节学习的优越性。E 根据在现实世界中收集到的视觉 - 触觉数据对可形变的杯子和可形变的海绵进行重建的序列结果。
b) 定量结果
团队同样使用了定量指标对方法进行了评估。从表 1 中可以看到,ViTaM 在真机数据下的表现很理想, 大部分的物体都能做到重建误差的倒角距离在 1~2 厘米之内。在实验中,首先,团队将现有的纯视觉解决方案的性能与 ViTaM 系统的算法(不包括触觉编码器)进行了比较;其次,将该算法与之前的一项工作 VTacO 进行了比较,后者采用了基于硅胶的光学触觉传感器 DIGIT 来记录接触形变。在表 2 中可以看到 ViTaM 与前人方法的结果的倒角距离比较。可以发现,ViTaM 系统在重建弹性、塑性、铰链式和刚性四种类型的物体时,表现出优于纯视觉方法的性能。例如,使用 ViTaM 系统重建海绵的倒角距离仅为 0.467 厘米,与 VTacO 相比提高了 36%。基于硅胶的光学触觉传感器可以获得更高分辨率的局部几何信息,如尖锐边缘或严重形变,而分布式触觉手套设计则可以在遮挡过于严重而无法获得视觉信息时获得更全面的特征。

表 1:ViTaM 方法在真机物体上的重建效果指标

表 2:ViTaM 方法与前人的基线方法的定量指标的比较
结论与未来展望
在复杂的操作任务中,捕捉手与可形变物体之间的触觉数据并进一步估计手物状态一直是一个巨大挑战。特别是,缺乏准确、分布式且具有可伸缩性的触觉阵列,阻碍了视觉 - 触觉学习的融合,限制了对一般人类操作的理解。尤其是在可伸缩界面上的应变干扰,会严重影响力的测量准确性和应用效果。
本文提出了一种用于操作的视觉 - 触觉联合记录与跟踪系统,其中触觉输入通过一款具有 1152 个传感通道和 13Hz 帧率的高密度可伸缩触觉手套捕获。该触觉手套集成了一种主动的应变干扰抑制方法,其力测量的准确率达到 97.6%。与未经校正的测量数据相比,ViTaM 的传感器准确度提升了 45.3%。这一主动方法在材料 - 电路层面工作,更符合人类在接触刚性或可形变物体时的自适应触觉感知。与传统的应变干扰抑制策略相比,从结构设计和材料选择角度来看,本文提出的主动方法具有易于集成、成本效益高、大面积适配、耐用性强及广泛的应变抑制范围等优点。ViTaM 系统实现了跨模态数据特征的融合,揭示了手物交互过程中的被遮挡状态,推动了智能体在人形体与机器交互(HMI)中理解能力的发展,尤其是在力学交互方面,向人类触觉感知的水平迈进了一步。
展望未来,ViTaM 系统将被集成到机器人表面覆盖的电子皮肤中,实现与周围环境的无缝互动,能够感知并响应多种环境刺激。此外,捕捉和恢复人类操作过程中的动态状态将有助于更好地理解人类行为,并提升机器人灵巧操作的能力,推动从物体特定操作到通用操作场景的技术进步。
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。










