

 新火种
2024-10-06
新火种
2024-10-06 


我用豆包,生成了AI版《红楼梦》MV
要论最近最火的AI视频生成模型,无疑就属字节豆包了。
也就是字节一口气亮出的PixelDance模型和Seaweed模型。
而且大家都说效果好,那这不就得亲自测试一波喽,而且是直接上难度的那种——
最近抖音里很多人都在模仿林黛玉哭泣,我们不妨用“全字节系的AI”来制作一支《红楼梦》的MV。
然后啊,效果简直就是一个大写的万万没想到!话不多说,直接展示成果:
不论是生成的多人物、画面的质量,甚至是故事情节,豆包的视频可以说是相当有《红楼梦》那味儿了。
而也正如刚才提到的,打造这支MV背后的AI,统统都是字节系。
现在我们就来一一拆解细节步骤。
第一步,用豆包查询《红楼梦》中的经典片段原文,作为生成图片的Prompt。
例如王熙凤出场的名场面,豆包给出了这样的答案:

第二步,我们直接用《红楼梦》中的原文片段,“喂”给字节的即梦,让它先生成一幅画。
例如我们采用的Prompt是:
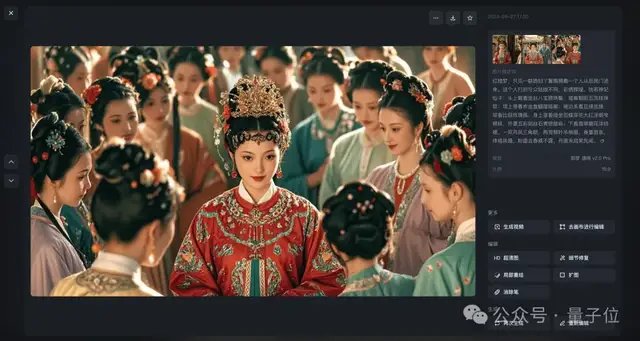
所有生成的图片如下所示:






第三步,将生成的图片丢给豆包PixelDance模型,再附上一句Prompt,让它生成视频片段:
(当然,也可以继续写出更多的动作。)
采用相同的方法,逐个生成其它视频的片段。
再例如下面这个片段,Prompt是这样的:
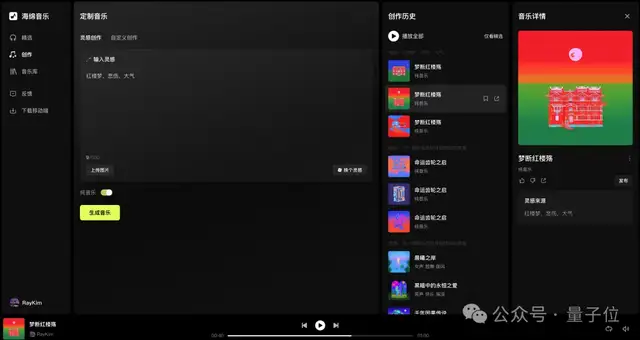
第四步,用基于豆包音乐模型的海绵音乐,生成1分钟的视频BGM,而且Prompt极其简单:
一曲《梦断红楼殇》就诞生了:
第五步,将最终的6个视频和BGM统统导入字节的剪映,对视频做一个剪辑,就大功告成了!
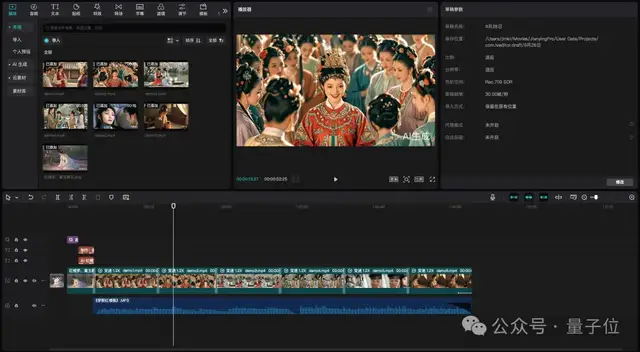
不难看出,现在已经是人人都可以打造MV了,并且步骤和方法也相当简单,只需联动一下字节系的AI们:
豆包(豆包语言模型)、即梦(豆包文生图模型)、豆包视频生成模型PixelDance、海绵音乐(豆包音乐模型)、剪映。
而在整个过程中,视频生成,无疑是最为关键的步骤。
但有一说一,AI版《红楼梦》中的视频片段,还并没有完全展现豆包PixelDance模型的全部真实实力。
视频生成,已经步入影视级这次豆包在发布视频模型之际,把它的能力归结为了四个点:
精准的语义理解,多动作多主体交互强大动态和炫酷运镜并存一致性多镜头生成多风格多比例兼容或许光看文字不能很直观地感受,接下来我们就一一对这四个特点做深入解读。
精准的语义理解,多动作多主体交互
若是纵览目前市面上的视频模型,其实大多数产品只能完成简单指令单一动作,而豆包PixelDance模型可以说是把AI对于Prompt的理解能力拉上一个高度。
不仅如此,豆包PixelDance模型还能把故事延展开来(时序性多拍动作指令),以及哪怕参考图片中没有的人物,也可以通过语言的方式生成。
例如下面这段Prompt:
最初的图像仅有小朋友的脸,但生成的视频很好的满足了Prompt中的所有要求。
再如:
由此可见,不论Prompt多复杂,豆包PixelDance模型是可以hold住的。
强大动态和炫酷运镜并存
复杂的动态和运镜,也一直是视频生成的难点之一。
这是因为真实的动态往往涉及到对物理规律的准确模拟,在复杂动态场景中,多个物体的相互作用会使物理模拟变得极为复杂。
对于人物的动作,还需要模拟人体的关节运动和肌肉变形。
复杂的动态和运镜通常会带来光影的变化,而准确地计算光影效果是一项艰巨的任务。光线的传播、反射、折射等现象都需要进行精确的模拟。
动态场景中的光源也可能是变化的,如太阳的位置随时间变化、灯光的闪烁等。这就需要实时计算光线的强度、颜色和方向,以确保画面的光影效果真实自然。
而这些种种的挑战到了豆包PixelDance模型这里,似乎就不再是难事。
例如在下面这个视频中,男子在冲浪的过程被生成的可谓是相当逼真,就连浪花、光影、人的动作、发丝等等,都与现实非常贴近:
再如下面这个快速穿越自然的场景,光影的交错、物理的规律都拿捏的非常精准,宛如科幻大片的片段:
一致性多镜头生成
一致性和多镜头,同样也是此前AI视频生成被人们诟病的一点,甚至人类都开始模仿起了AI们的鬼畜。
例如本来上一个画面还是人物A,下一个画面就变成了人物B,甚至连性别和物种都有可能被篡改……
那么豆包PixelDance模型的表现又是如何呢?我们直接来看效果:
第一个画面是小女孩面对死神,镜头一转给到女孩的时候,豆包PixelDance模型生成的内容不论是发型还是着装等细节,都保持了一致。
即使面对更加复杂的场景、镜头切换,也是没有问题:
多风格多比例兼容
当然,风格的多变,是每个视频生成模型的“必修课”,豆包PixelDance模型也是如此。
例如黑白大片风:

再如日漫风格:
而且从这两个例子中,我们也不难发现豆包PixelDance模型对于生成视频的比例也是可控的。
更具体而言,豆包PixelDance模型支持包括黑白,3D动画、2D动画、国画、水彩、水粉等多种风格;包含1:1,3:4,4:3,16:9,9:16,21:9 六个比例。
嗯,是一个多变且较为全能的选手了。
那么接下来的一个问题是:如何做到的?
对于豆包视频模型的能力,在发布会上,针对刚才我们所展示的前三项能力,分别对应的技术是这样的:

高效的DiT融合计算单元、全新设计的扩散模型训练方法,以及深度优化的Transforemer架构,便是“炼”出豆包PixelDanca模型背后的三大技术杀手锏了。
不过对于各个视频生成产品的效果,“什么样的才算好?是否有什么标准?”这一问题,在新火种与火山引擎总裁谭待交流过程中,他表示:
不只有视频模型除了豆包视频模型之外,这次字节还发布了2个重磅产品。
首先就是豆包音乐模型。
正如我们给AI《红楼梦》做BGM时所演示的那般,生成歌曲,Prompt只需简单的几个字就可以,只要关键字到位,那么歌曲的情感也能精准拿捏。
除此之外,豆包音乐模型还提供了10余种不同的音乐风格和情绪的表达,人声也几乎与人类无异。
其次就是豆包同声传译模型。
这个模型的效果可以说是媲美人类的同传了,可以边说边翻译,实时沟通完全没有障碍;而且在翻译的准确性和人声自然度方面也是更上一层楼,可以很好的应用在各种需要同传的场景。
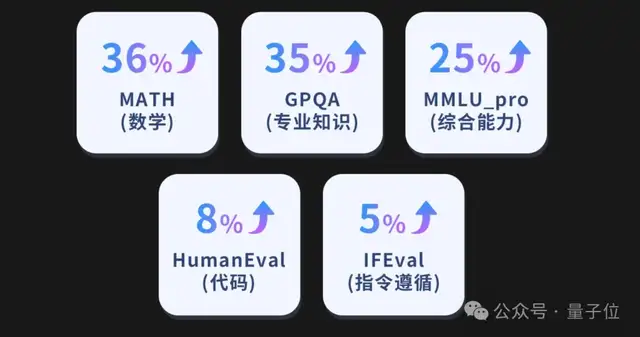
最后,豆包通用模型的能力,这次也得到了大幅的提升:
至此,字节的豆包大模型家族就变得更加壮大了起来,可以一起来看下现在的全景图:

然而,阵容的庞大还是只是一面,更重要的是,豆包家族的模型们是已经被广泛地使用了。
据了解,截至到9月,豆包大模型的日均tokens使用量已经超过1.3万亿,4个月的时间里tokens整体增长超过了10倍。在多模态方面,豆包·文生图模型日均生成图片5000万张,此外,豆包目前日均处理语音85万小时。
这组数据也从侧面反映出了模型的效果,毕竟只有好用才能会被大众所接受;这也再次印证了豆包模型最初发布时所提出的那句“只有最大的使用量,才能打磨出最好的大模型”。
也可以视为豆包“左手使用量,右手多场景”的方式反复打磨后的一次正确的验证;而在验证过后,字节此次也亮出了他们在大模型上的发展之路,即先To C,再To B。
正如谭待所说:
不仅如此,随着大模型价格战的拉响,豆包模型的价格也是一降再降,由此也可以预见大模型发展的一种趋势——
成本已不会阻碍创新之路。
那么对于豆包模型接下来的发展,是值得期待一波了。
One More Thing:说到“全字节系AI”,除了做AI版《红楼梦》MV的工具全是字节产品之外,这篇文章还是在飞书里写的。

最后,一句土味“情话”ending本文:
字节大舞台,有AI你就来~
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。










