

 新火种
2024-10-06
新火种
2024-10-06 


Llama系列上新多模态!3.2版本开源超闭源,还和Arm联手搞了手机优化版
在多模态领域,开源模型也超闭源了!
就在刚刚结束的Meta开发者大会上,Llama 3.2闪亮登场:
这回不仅具备了多模态能力,还和Arm等联手,推出了专门为高通和联发科硬件优化的“移动”版本。

具体来说,此次Meta一共发布了Llama 3.2的4个型号:
110亿和900亿参数的多模态版本10亿参数和30亿参数的轻量级纯文本模型官方数据显示,与同等规模的“中小型”大模型相比,Llama 3.2 11B和90B表现出了超越闭源模型的性能。
尤其是在图像理解任务方面,Llama 3.2 11B超过了Claude 3 Haiku,而90B版本更是能跟GPT-4o-mini掰掰手腕了。
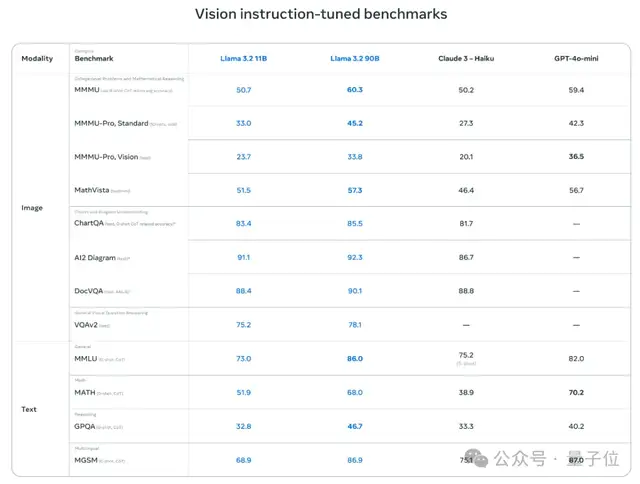
而专为端侧打造的3B版本,在性能测试中表现也优于谷歌的Gemma 2 2.6B和微软的Phi 3.5-mini。
如此表现,着实吸引了不少网友的关注。
有人兴奋地认为,Llama 3.2的推出可能再次“改变游戏规则”:

Meta AI官方对此回复道:
 首个视觉
首个视觉有关Llama 3.2具体能做什么,这次官方也释出了不少demo。
先看个汇总:Llama 3.2 11B和90B支持一系列多模态视觉任务,包括为图像添加字幕、根据自然语言指令完成数据可视化等等。

举个,丢给Llama 3.2一张图片,它能把图片中的元素一一拆解,告诉你详细的图片信息:

同样,也可以反过来根据文字指令找出符合用户需求的图片。
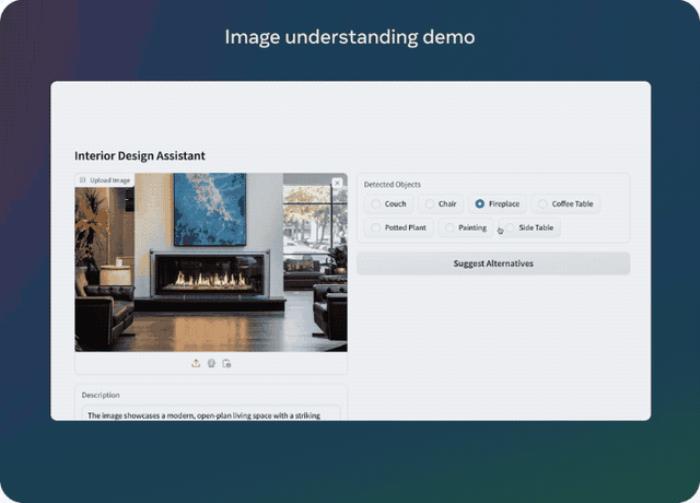
Llama 3.2 11B和90B也是首批支持多模态任务的Llama系列模型,为此,Meta的研究人员打造了一个新的模型架构。
在Llama 3.1的基础之上,研究人员在不更新语言模型参数的情况下训练了一组适配器权重,将预训练的图像编码器集成到了预训练的语言模型中。
这样,Llama 3.2既能保持纯文本功能的完整性,也能get视觉能力。
训练过程中,Llama 3.2采用图像-文本对数据进行训练。训练分为多个阶段,包括在大规模有噪声数据上的预训练,和更进一步在中等规模高质量领域内和知识增强数据上的训练。
在后训练(post-training)中,研究人员通过监督微调(SFT)、拒绝采样(RS)和直接偏好优化(DPO)进行了几轮对齐。
专为端侧打造的“小”模型至于1B和3B这两个轻量级模型,目的更加清晰:
随着苹果Apple Intelligence的推出,对于电子消费市场而言,手机等终端上的生成式AI已经成为标配。
而脱离云端独立运行在终端上的模型,无论是从功能还是从安全的角度,都是终端AIGC落地的关键。
△端侧写作助手Llama 3.2 1B和3B模型由Llama 3.1的8B和70B模型剪枝、蒸馏得到。
可以简单理解为,这俩“小”模型是Llama 3.1教出来的“学生”。
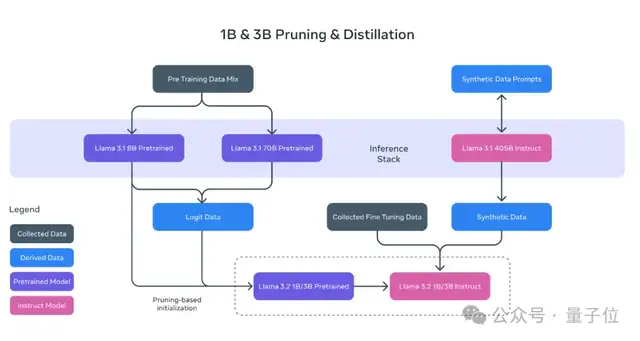
Llama 3.2 1B和3B仅支持文本任务,上下文长度为128K。来自Meta合作方Arm的客户业务线总经理Chris Bergey认为:
不少网友也为此点赞:
还有网友已经第一时间实践上了:
这位网友用Llama 3.2 1B运行了一个完整的代码库,并要求它总结代码,结果是酱婶的:

“不完美,但远超预期。”
前有OpenAI「Her」全量开放、谷歌Gemini 1.5迎来重大升级,Llama这边也紧锣密鼓跟上新动作,AI圈的这一周,依旧是开源闭源激情碰撞,充满话题度的一周。
那么,你怎么看Llama这波新发布?
对了,如果你对Llama 3.2感兴趣,大模型竞技场已经可以试玩了。

Ollama、Groq等也已第一时间更新支持。
参考链接:[1]https://ai.meta.com/blog/llama-3-2-connect-2024-vision-edge-mobile-devices/[2]https://www.cnet.com/tech/mobile/meta-and-arm-want-to-bring-more-ai-to-phones-and-beyond/#google_vignette[3]https://news.ycombinator.com/item?id=41649763
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。










