

 新火种
2023-09-28
新火种
2023-09-28 


PyTorch 2.0现已发布:编译器性能大幅提升,100% 向后兼容
3 月 19 日消息,PyTorch 2.0 稳定版现已发布。跟先前 1.0 版本相比,2.0 有了颠覆式的变化。在 PyTorch 2.0 中,最大的改进主要是 API 的 torch.compile,新编译器比先前「eager mode」所提供的即时生成代码的速度快得多,性能得以进一步提升。
附官网地址:https://pytorch.org/
GitHub 地址:https://github.com/pytorch/pytorch/releases

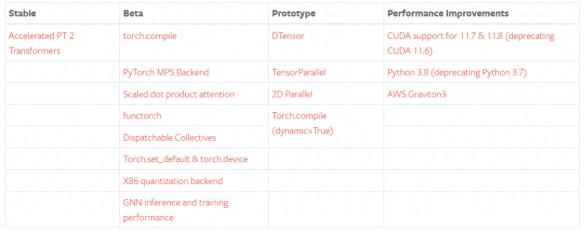
新版本更新之处包括稳定版的 Accelerated Transformers(以前称为 Better Transformers);Beta 版包括作为 PyTorch 2.0 主要 API 的 torch.compile、作为 torch.nn.functional 一部分的 scaled_dot_product_attention 函数、MPS 后端、torch.func 模块中的 functorch API;以及其他跨越各种推理、性能和训练优化功能的 GPU 和 CPU 的 Beta / Prototype 改进。
关于 torch.compile 的全面介绍和技术概况请见 2.0 入门页面。
除了 PyTorch 2.0,研发团队还发布了 PyTorch 域库的一系列 Beta 更新,包括 in-tree 的库和 TorchAudio、TorchVision、TorchText 等独立库。此外,TorchX 转向社区支持模式。
概括:
torch.compile 是 PyTorch 2.0 的主要 API,它能包装并返回编译后的模型。这个是一个完全附加(和可选)的功能,因此 PyTorch 2.0 根据定义是 100% 向后兼容的。
作为 torch.compile 的基础技术,TorchInductor 与 Nvidia / AMD GPU 将依赖于 OpenAI Triton 深度学习编译器来生成性能代码并隐藏低级硬件细节。OpenAI triton 生成的内核则实现了与手写内核和专用 cuda 库 (如 cublas) 相当的性能。
Accelerated Transformers 引入了对训练和推理的高性能支持,使用自定义内核架构实现缩放点积注意力 (SPDA)。API 与 torch.compile () 集成,模型开发人员也可以通过调用新的 scaled_dot_product_attention () 运算符直接使用缩放点积注意力内核。
Metal Performance Shaders (MPS) 后端能在 Mac 平台上提供 GPU 加速的 PyTorch 训练,并增加了对前 60 个最常用运算符的支持,覆盖 300 多个运算符。
Amazon AWS 优化了 AWS Graviton3 上的 PyTorch CPU 推理。与之前的版本相比,PyTorch 2.0 提高了 Graviton 的推理性能,包括针对 ResNet-50 和 BERT 的改进。
其他一些跨 TensorParallel、DTensor、2D parallel、TorchDynamo、AOTAutograd、PrimTorch 和 TorchInductor 的新 prototype 功能和方法。
要查看公开的 2.0、1.13 和 1.12 功能完整列表,请点击此处。
稳定功能
PyTorch 2.0 版本包括 PyTorch Transformer API 新的高性能实现,以前称为「Better Transformer API」,现在更名为 「Accelerated PyTorch 2 Transformers」。
研发团队表示他们希望整个行业都能负担得起训练和部署 SOTA Transformer 模型的成本。新版本引入了对训练和推理的高性能支持,使用自定义内核架构实现缩放点积注意力 (SPDA)。
与「快速路径(fastpath)」架构类似,自定义内核完全集成到 PyTorch Transformer API 中 —— 因此,使用 Transformer 和 MultiHeadAttention API 将使用户能够:
明显地看到显著的速度提升;
支持更多用例,包括使用交叉注意力模型、Transformer 解码器,并且可以用于训练模型;
继续对固定和可变的序列长度 Transformer 编码器和自注意力用例使用 fastpath 推理。
为了充分利用不同的硬件模型和 Transformer 用例,PyTorch 2.0 支持多个 SDPA 自定义内核,自定义内核选择逻辑是为给定模型和硬件类型选择最高性能的内核。除了现有的 Transformer API 之外,模型开发人员还可以通过调用新的 scaled_dot_product_attention () 运算来直接使用缩放点积注意力内核。
要使用您的模型,同时受益于 pt2 编译的额外加速 (用于推断或训练),请使用 model = torch.compile (model) 对模型进行预处理。
我们通过使用自定义内核和 torch.compile () 的组合,使用 Accelerated PyTorch 2 transformer 实现了训练 transformer 模型的大幅加速,特别是大语言模型。
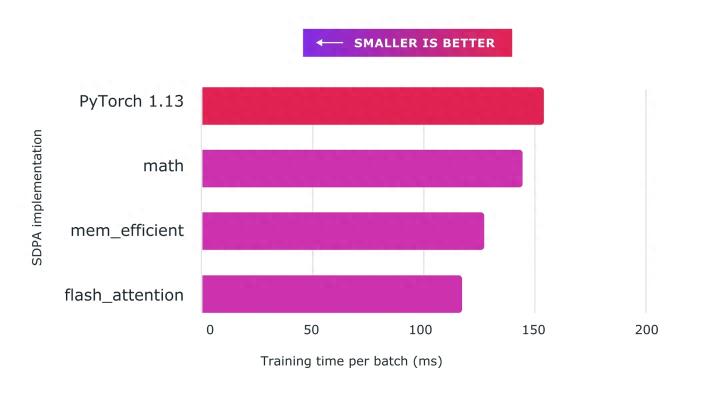
从官方数据可以看到,PyTorch 2.0 的编译效率比 1.0 实现了大幅提高。
这个数据来自 PyTorch 基金会在 Nvidia A100 GPU 上使用 PyTorch 2.0 对 163 个开源模型进行的基准测试,其中包括图像分类、目标检测、图像生成等任务,以及各种 NLP 任务。
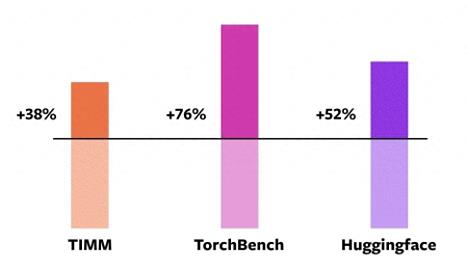
这些 Benchmark 分为三类:TIMM、TorchBench、HuggingFace Tranformers。
据 PyTorch 基金会称,新编译器在使用 Float32 精度模式时运行速度提高了 21%,在使用自动混合精度(AMP)模式时运行速度提高了 51%。在这 163 个模型中,torch.compile 可以在 93% 模型上正常运行。
值得一提的是,官方在桌面级 GPU(如 NVIDIA 3090)上测量到的加速能力低于服务器级 GPU(如 A100)。到目前为止,PyTorch 2.0 默认后端 TorchInductor 已经支持 CPU 和 NVIDIA Volta 和 Ampere GP,暂不支持其他 GPU、XPU 或旧的 NVIDIA GPU。
相关推荐



- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。










