

 新火种
2024-09-07
新火种
2024-09-07 


李飞飞团队再造黑科技!机器人自学家务样样精通,开源代码了解一下?
倒茶、叠衣服、整理书籍、丢垃圾,现在的家务机器人干活真是越来越熟练了。

不过,也不是每个家务机器人都能做到像动图里那么流畅的。
熟练家务的背后,是李飞飞团队琢磨出来的一种新办法。
他们把任务动作拆解后标记出几个关键点,再给到具体规则让机器人知道这些点之间有什么联系,要怎么操作比较好。除此之外,机器人还能自主学习,越练习越厉害。
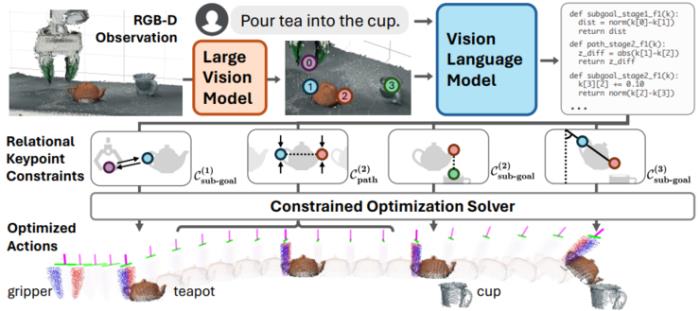
以倒茶这个动作为例,机器人会先用摄像头确定茶杯茶壶等的位置、形状等要素,再识别出关键点,比如茶杯的中心点和把手的中心点,ReKep 会给机器人编写出一系列规则,告诉它要用什么角度、怎么拿怎么倾倒、用多大力气等,机器人只要按照规则行动就能成功倒茶了。


不得不说,这么一个简单的动作想让机器人做好是真的是太难了。要是没有 ReKep 技术,想看到机器人熟练地干各种家务活还不知道要等到猴年马月。
毕竟今年三月份的时候,李飞飞团队的家务机器人还是这样的,只会擦擦桌子切个水果:
而半年后的今天,就已经进化成全能选手了:
目前,李飞飞团队关于 ReKep 技术的论文已在 arXiv 公开,代码也已开源。
论文标题:ReKep: Spatio-Temporal Reasoning of Relational Keypoint Constraints for Robotic Manipulation
论文地址:https://arxiv.org/pdf/2409.01652
项目网站:https://rekep-robot.github.io/
项目代码:github.com/huangwl18/ReKep
论文概述研究问题和动机李飞飞团队旨在解决与机器人操作任务相关的挑战,这些任务涉及多个空间关系和时间依赖阶段,需要对复杂的空间和时间关系进行编码。
他们希望开发一个广泛适用的框架,能够适应需要多阶段、野外环境、双手操作和反应行为的任务,通过基础模型的进展在获取约束方面具有可扩展性,并能够实时优化以产生复杂的操作行为。
难点与挑战现有的使用刚体变换表示操作任务约束的方法缺乏几何细节,要求预定义的物体模型,并且无法处理可变形物体。
在视觉空间中直接学习约束的数据驱动方法也在收集训练数据时面临挑战,因为约束的数量在物体和任务方面呈组合增长。
技术创新李飞飞团队提出了一种名为关系关键点约束(ReKep)的方法,用于机器人操作。
ReKep 将操作任务编码为约束,连接机器人与其环境,而无需手动标注。该方法利用Python函数将一组语义上有意义的三维关键点映射为数值成本,从而能够表示复杂的空间和时间关系。
该框架旨在通过大型视觉模型和视觉-语言模型自动生成约束,实现从自然语言指令和RGB-D观测中高效地指定任务。
他们还提出了一种算法实例,可以实时高效地解决优化问题。
真实实验实验涉及多个任务,包括倒茶、回收罐、整理书籍、打包盒子、折叠衣物、装鞋盒和协作折叠等。这些任务被设计来测试系统在不同方面的性能,如空间和时间依赖性、对环境的适应性、双手协调和与人类的互动。
轮式单臂平台和固定式双臂平台的成功率
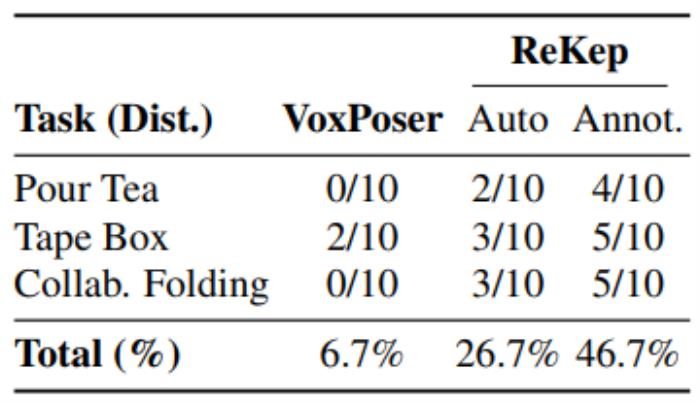
两个机器人平台在外部干扰下的成功率
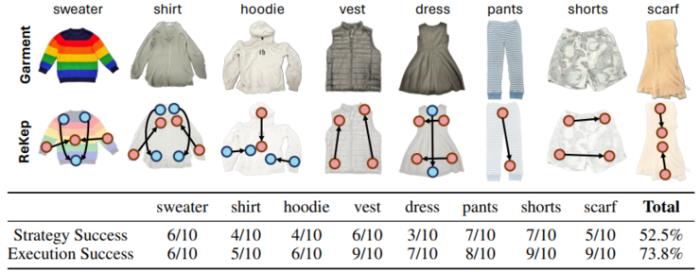
ReKep 用于折叠不同类别服装的新型双臂策略及其成功率
实验结果显示,ReKep在多种任务上的成功率较高,证明了其在自动化操控任务中的潜力。成功率根据任务的不同而有所差异,但总体上表现良好。
技术解读关系关键点约束(ReKep)首先,他们定义了单个ReKep实例,并且假设已经指定了一组 ? 个关键点。每个关键点 ∈ℝ3 指的是场景表面上的一个 3D 点,其坐标依赖于任务语义和环境(例如,手柄上的抓取点,壶嘴)。
本质上来说,一个 ReKep 实例编码了关键点之间的一个期望的空间关系,这些关系可能属于机器人手臂、物体部分或其他代理。
然而,一个操作任务通常涉及多个空间关系,并且可能具有多个时间上依赖的阶段,每个阶段都涉及不同的空间关系。为此,他们将任务分解为 ? 个阶段,并为每个阶段 ?∈{1,…,?} 使用 ReKep 来指定两类约束:
子目标约束
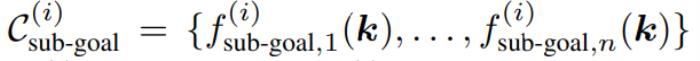
路径约束
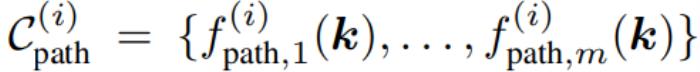
其中 ?sub-goal (?) 编码阶段 ? 结束时需要达到的关键点关系,而 ?path (?) 编码阶段 ? 内部需要满足的关键点关系。
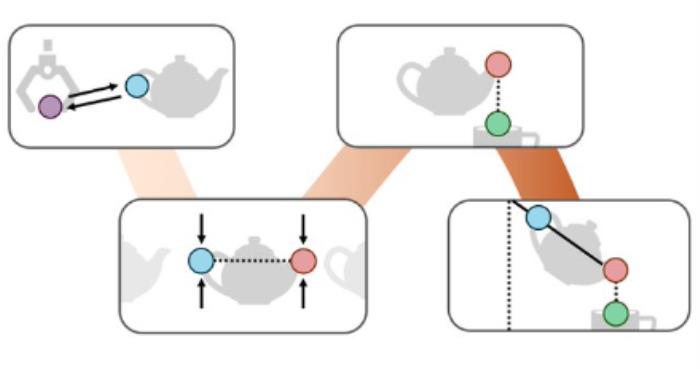
如下图所示的倾倒任务由三个阶段组成:抓取、对齐和倾倒。
阶段 1 的子目标约束拉动末端执行器向茶壶手柄靠近。阶段 2 的子目标约束指定壶嘴需要位于杯口上方,阶段 2 的路径约束确保茶壶直立,以避免倾倒时溢出。最后,阶段 3 的子目标约束指定倾倒角度。
他们将末端执行器姿态表示为 e∈ SE(3),将操控任务表述为一个优化问题,目标是找到一系列满足ReKep约束的末端执行器(end-effector)姿态,并将控制问题表述如下:
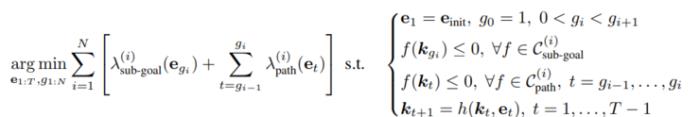
对于每个阶段,优化算法需要找到满足子目标约束的末端执行器姿态,以及实现这些子目标的路径。
分解与算法即时实例化为了实时求解优化问题,他们采用了分解方法,仅优化下一个子目标及其对应的路径。
子目标问题:首先解决子目标问题,确定当前阶段的末端执行器目标姿态。
路径问题:在获得子目标姿态后,解决路径问题,规划从当前姿态到子目标姿态的轨迹。
回溯:如果发现任何子目标约束不再满足,系统可以回溯到之前的阶段进行重新规划。
关键点提议和ReKep生成为了使系统能够在给定自由形式任务指令的情况下执行野外任务,他们设计了一个使用大型视觉模型和视觉语言模型进行关键点提议和ReKep生成的管道,并分成了两个部分:
关键点提议使用大型视觉模型(LVM),如DINOv2,来提取场景中的特征,并利用这些特征来识别潜在的关键点。这些关键点通常是场景中具有语义意义的3D点,例如物体的边缘、角落或特定物体部分的中心。
结合关键点和任务指令,使用视觉-语言模型(VLM)来生成ReKep,这些约束将用于指导机器人的动作规划和执行。这一步骤利用了视觉模型对场景的理解以及语言模型对指令的解释能力。


李飞飞博士是斯坦福大学计算机科学系首任红杉教授,也是斯坦福以人为本的人工智能研究所的联席主任,曾担任担任谷歌副总裁和首席科学家,在多家上市公司或私营公司担任董事会成员或顾问。
李飞飞主导的斯坦福AI实验室、斯坦福视觉与学习实验室(SVL)和斯坦福以人为本人工智能研究院涌现出大量优秀人才,包括 OpenAI 联合创始人 Andrej Karpathy、国内内第一个坚探索具身智能的卢策吾、前Google AI中国中心总裁李佳、前阿里自动驾驶掌舵人王刚等。
她目前的研究兴趣包括认知启发式人工智能、机器学习、深度学习、计算机视觉、机器人学习和人工智能+医疗,尤其是用于医疗保健的环境智能系统。
Wenlong Huang
Wenlong Huang 是斯坦福大学计算机科学专业的博士生,由李飞飞指导,也是斯坦福视觉与学习实验室 (SVL)的成员。他于 2018 年获得加州大学伯克利分校计算机科学学士学位,指导老师是 Deepak Pathak、Igor Mordatch 和 Pieter Abbeel。
他的研究目标是赋予机器人广泛的泛化能力,使其能够执行开放世界操控任务,尤其是在家庭环境中。研究兴趣包括:
开发能够充分利用互联网规模数据或基于这些数据进行训练的模型的抽象概念
开发能够表现出广泛泛化行为的运动技能
Chen Wang(王辰)
Chen Wang是斯坦福计算机科学学院的博士生,导师是李飞飞和 C. Karen Liu。他本科就读于上海交通大学计算机科学专业,是第一批加入卢策吾团队研究机器人具身智能的学生之一。
他的研究目标是制造出具有与人类一样的灵活性和处理日常任务能力的机器人,因此专注于机器人学习,以实现灵巧操作、模仿人类动作以及长期规划和控制。
Yunzhu Li
Yunzhu Li现在是哥伦比亚大学计算机科学助理教授,曾是斯坦福视觉与学习实验室 (SVL)的博士后,与李飞飞、Jiajun Wu 一起工作。北京大学本科毕业后,他在麻省理工学院计算机科学与人工智能实验室(CSAIL)获得博士学位,导师是 Antonio Torralba 和 Russ Tedrake。
目前他在机器人感知、交互和学习实验室(RoboPIL)进行机器人技术、计算机视觉和机器学习的交叉研究,专注于机器人学习,特别是直观物理学、具身智能、多模式感知三个方向,旨在显著扩展机器人的感知和物理交互能力。
Ruohan Zhang
Ruohan Zhang是斯坦福视觉与学习实验室 (SVL)的研究员,和李飞飞、Jiajun Wu、Silvio Savarese 一起工作。他曾在在德克萨斯大学奥斯汀分校获得博士学位,指导教授是 Dana Ballard 和 Mary Hayhoe。
他的长期研究兴趣是以人为本的人工智能:理解人类智能以开发受生物启发的人工智能算法,以及使人工智能与人类更加兼容。最近专注于以人为本的机器人技术:通过数据驱动的方法开发可增强人类福祉的机器人解决方案(系统和算法)。

相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。










