

 新火种
2023-09-28
新火种
2023-09-28 

自然语言处理(NLP)中的深度学习发展史和待解难题
王小新 编译自 sigmoidal量子位 出品 | 公众号 QbitAI自然语言处理(NLP)是指机器理解并解释人类写作与说话方式的能力。近年来,深度学习技术在自然语言处理方面的研究和应用也取得了显著的成果。技术博客Sigmoidal最近发布了一篇文章,作者是机器学习工程师Rafal。这篇文章讨论了自然语言处理方法的发展史,以及深度学习带来的影响。量子位编译如下:在深度学习时代来临前在2006年Hinton提出深度信念网络(DBN)之前,神经网络是一种极其复杂且难以训练的功能网络,所以只能作为一种数学理论来进行研究。在神经网络成为一种强大的机器学习工具之前,经典的数据挖掘算法在自然语言处理方面有着许多相当成功的应用。我们可以使用一些很简单且容易理解的模型来解决常见问题,比如垃圾邮件过滤、词性标注等。但并不是所有问题都能用这些经典模型来解决。简单的模型不能准确地捕捉到语言中的细微之处,比如讽刺、成语或语境。基于总体摘要的算法(如词袋模型)在提取文本数据的序列性质时效果不佳,而N元模型(n-grams)在模拟广义情境时严重受到了“维度灾难(curse of dimensionality)”问题的影响,隐马尔可夫(HMM)模型受马尔可夫性质所限,也难以克服上述问题。这些方法在更复杂的NLP问题中也有应用,但是并没有取得很好的效果。第一个技术突破:Word2Vec神经网络能提供语义丰富的单词表征,给NLP领域带来了根本性突破。在此之前,最常用的表征方法为one-hot编码,即每个单词会被转换成一个独特的二元向量,且只有一个非零项。这种方法严重地受到了稀疏性的影响,不能用来表示任何带有特定含义的词语。 △ Word2Vec方法中被投射到二维空间中的单词表征然而,我们可以尝试关注几个周围单词,移除中间单词,并通过在神经网络输入一个中间单词后,预测周围单词,这就是skip-gram模型;或是基于周围单词,进行预测中间单词,即连续词袋模型(CBOW)。当然,这种模型没什么用处,但是事实证明,它可在保留了单词语义结构的前提下,用来生成一个强大且有效的向量表示。进一步改进尽管Word2Vec模型的效果超过了许多经典算法,但是仍需要一种能捕获文本长短期顺序依赖关系的解决方法。对于这个问题,第一种解决方法为经典的循环神经网络(Recurrent Neural Networks),它利用数据的时间性质,使用存储在隐含状态中的先前单词信息,有序地将每个单词传输到训练网络中。
△ Word2Vec方法中被投射到二维空间中的单词表征然而,我们可以尝试关注几个周围单词,移除中间单词,并通过在神经网络输入一个中间单词后,预测周围单词,这就是skip-gram模型;或是基于周围单词,进行预测中间单词,即连续词袋模型(CBOW)。当然,这种模型没什么用处,但是事实证明,它可在保留了单词语义结构的前提下,用来生成一个强大且有效的向量表示。进一步改进尽管Word2Vec模型的效果超过了许多经典算法,但是仍需要一种能捕获文本长短期顺序依赖关系的解决方法。对于这个问题,第一种解决方法为经典的循环神经网络(Recurrent Neural Networks),它利用数据的时间性质,使用存储在隐含状态中的先前单词信息,有序地将每个单词传输到训练网络中。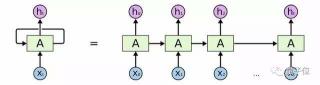 △ 循环神经网络示意图事实证明,这种网络能很好地处理局部依赖关系,但是由于“梯度消失”问题,很难训练出理想效果。为了解决这个问题,Schmidhuber等人提出了一种新型网络拓扑结构,即长短期记忆模型(Long Short Term Memory)。它通过在网络中引入一种叫做记忆单元的特殊结构来解决该问题。这种复杂机制能有效获取单元间更长期的依赖关系,且不会显著增加参数量。现有的很多常用结构也是LSTM模型的变体,例如mLSTM模型或GRU模型。这得益于提出了基于自适应简化的记忆单元更新机制,显着减少了所需的参数量。在计算机视觉领域中,卷积神经网络已经取得了很好的应用,迟早会延伸到自然语言处理研究中。目前,作为一种常用的网络单元,一维卷积已成功应用到多种序列模型问题的处理中,包括语义分割、快速机器翻译和某些序列转换网络中。由于更容易进行并行计算,与循环神经网络相比,一维卷积在训练速度上已提高了一个数量级。了解常见的NLP问题有许多任务,涉及到计算机与人类语言之间的交互,这可能对人类来说是一件简单的小事,但是给计算机带来了很大的麻烦。这主要是由语言中细微差异引起的,如讽刺、成语等。按照复杂程度,下面列出了当前还处于探索阶段的多个NLP领域:最常见的领域是情绪分析(Sentiment Analysis),这方面也许最为简单。它通常可归结为确定说话者/作者对某个特定主题的态度或情感反应。这种情绪可能是积极的、中性的和消极的。文末的链接1给出了一篇关于使用深度卷积神经网络学习Twitter情绪的经典文章。链接2的一个有趣实验偶然发现,深度循环网络也可用来辨识情绪。
△ 循环神经网络示意图事实证明,这种网络能很好地处理局部依赖关系,但是由于“梯度消失”问题,很难训练出理想效果。为了解决这个问题,Schmidhuber等人提出了一种新型网络拓扑结构,即长短期记忆模型(Long Short Term Memory)。它通过在网络中引入一种叫做记忆单元的特殊结构来解决该问题。这种复杂机制能有效获取单元间更长期的依赖关系,且不会显著增加参数量。现有的很多常用结构也是LSTM模型的变体,例如mLSTM模型或GRU模型。这得益于提出了基于自适应简化的记忆单元更新机制,显着减少了所需的参数量。在计算机视觉领域中,卷积神经网络已经取得了很好的应用,迟早会延伸到自然语言处理研究中。目前,作为一种常用的网络单元,一维卷积已成功应用到多种序列模型问题的处理中,包括语义分割、快速机器翻译和某些序列转换网络中。由于更容易进行并行计算,与循环神经网络相比,一维卷积在训练速度上已提高了一个数量级。了解常见的NLP问题有许多任务,涉及到计算机与人类语言之间的交互,这可能对人类来说是一件简单的小事,但是给计算机带来了很大的麻烦。这主要是由语言中细微差异引起的,如讽刺、成语等。按照复杂程度,下面列出了当前还处于探索阶段的多个NLP领域:最常见的领域是情绪分析(Sentiment Analysis),这方面也许最为简单。它通常可归结为确定说话者/作者对某个特定主题的态度或情感反应。这种情绪可能是积极的、中性的和消极的。文末的链接1给出了一篇关于使用深度卷积神经网络学习Twitter情绪的经典文章。链接2的一个有趣实验偶然发现,深度循环网络也可用来辨识情绪。 △ 生成对话网络中的多个激活神经元。明显看出,即使进行无监督训练,网络也能分辨出不同情绪类别。我们可以将这种方法应用到文件分类(Document Classification)中,这是一个普通的分类问题,而不是为每篇文章打几个标签。链接3的论文通过仔细比较算法间差异,得出深度学习也可作为一种文本分类方法的结论。接下来将要介绍一个真正有挑战的领域——机器翻译(Machine Translation)。这是一个与先前两个任务完全不同的研究领域。我们需要一个预测模型,来输出一个单词序列,而不是一个标签。在序列数据研究中,深度学习理论的加入给这个领域带来了巨大的突破。通过链接4的博文中,你可以了解更多关于循环神经网络在机器翻译中的应用。我们可能还想要构建一个自动文本摘要(Text Summarization)模型,它需要在保留所有含义的前提下,提取出文本中最重要的部分。这需要一种算法来了解全文,同时能够锁定文章中能代表大部分含义的特定内容。在端到端方法中,可以引入注意力机制(Attention Mechanisms)模块来很好地解决这个问题。关于注意力机制的详细内容可参考量子位先前编译过的文章《自然语言处理中的注意力机制是干什么的?》最后一个领域为自动问答(Question Answering),这是一个与人工智能极其相关的研究方向。相关模型不仅需要了解所提出的问题,而且需充分了解文本中的关注点,并准确地知道在何处寻找答案。关于深度学习在自动问答中的详细说明,请查看链接5的相关博文。
△ 生成对话网络中的多个激活神经元。明显看出,即使进行无监督训练,网络也能分辨出不同情绪类别。我们可以将这种方法应用到文件分类(Document Classification)中,这是一个普通的分类问题,而不是为每篇文章打几个标签。链接3的论文通过仔细比较算法间差异,得出深度学习也可作为一种文本分类方法的结论。接下来将要介绍一个真正有挑战的领域——机器翻译(Machine Translation)。这是一个与先前两个任务完全不同的研究领域。我们需要一个预测模型,来输出一个单词序列,而不是一个标签。在序列数据研究中,深度学习理论的加入给这个领域带来了巨大的突破。通过链接4的博文中,你可以了解更多关于循环神经网络在机器翻译中的应用。我们可能还想要构建一个自动文本摘要(Text Summarization)模型,它需要在保留所有含义的前提下,提取出文本中最重要的部分。这需要一种算法来了解全文,同时能够锁定文章中能代表大部分含义的特定内容。在端到端方法中,可以引入注意力机制(Attention Mechanisms)模块来很好地解决这个问题。关于注意力机制的详细内容可参考量子位先前编译过的文章《自然语言处理中的注意力机制是干什么的?》最后一个领域为自动问答(Question Answering),这是一个与人工智能极其相关的研究方向。相关模型不仅需要了解所提出的问题,而且需充分了解文本中的关注点,并准确地知道在何处寻找答案。关于深度学习在自动问答中的详细说明,请查看链接5的相关博文。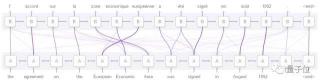 △ GNMT英译法的注意力机制示意图。由于深度学习为各种数据(如文本和图像)提供相应的向量表征,你可以利用不同的数据特性构建出不同模型。于是,就有了图片问答(Visual Question Answering)研究。这种方式比较简单,你只需要根据给出图像,回答相应问题。这项工作简单到听起来好像一个七岁小孩就能完成,但是深层模型在无监督情况下不能输出任何合理的结果。链接6的文章给出了相关模型的结果和说明。总结我们可以发现,深度学习在自然语言处理中也取得了很好的效果。但是由于计算和应用等问题,我们仍需要进一步了解深度神经网络,一旦可以掌控深度学习,这将永远改变游戏规则。相关链接1.Twitter情绪分类:/uploads/pic/20230928/
△ GNMT英译法的注意力机制示意图。由于深度学习为各种数据(如文本和图像)提供相应的向量表征,你可以利用不同的数据特性构建出不同模型。于是,就有了图片问答(Visual Question Answering)研究。这种方式比较简单,你只需要根据给出图像,回答相应问题。这项工作简单到听起来好像一个七岁小孩就能完成,但是深层模型在无监督情况下不能输出任何合理的结果。链接6的文章给出了相关模型的结果和说明。总结我们可以发现,深度学习在自然语言处理中也取得了很好的效果。但是由于计算和应用等问题,我们仍需要进一步了解深度神经网络,一旦可以掌控深度学习,这将永远改变游戏规则。相关链接1.Twitter情绪分类:/uploads/pic/20230928/
△ Word2Vec方法中被投射到二维空间中的单词表征然而,我们可以尝试关注几个周围单词,移除中间单词,并通过在神经网络输入一个中间单词后,预测周围单词,这就是skip-gram模型;或是基于周围单词,进行预测中间单词,即连续词袋模型(CBOW)。当然,这种模型没什么用处,但是事实证明,它可在保留了单词语义结构的前提下,用来生成一个强大且有效的向量表示。进一步改进尽管Word2Vec模型的效果超过了许多经典算法,但是仍需要一种能捕获文本长短期顺序依赖关系的解决方法。对于这个问题,第一种解决方法为经典的循环神经网络(Recurrent Neural Networks),它利用数据的时间性质,使用存储在隐含状态中的先前单词信息,有序地将每个单词传输到训练网络中。△ 循环神经网络示意图事实证明,这种网络能很好地处理局部依赖关系,但是由于“梯度消失”问题,很难训练出理想效果。为了解决这个问题,Schmidhuber等人提出了一种新型网络拓扑结构,即长短期记忆模型(Long Short Term Memory)。它通过在网络中引入一种叫做记忆单元的特殊结构来解决该问题。这种复杂机制能有效获取单元间更长期的依赖关系,且不会显著增加参数量。现有的很多常用结构也是LSTM模型的变体,例如mLSTM模型或GRU模型。这得益于提出了基于自适应简化的记忆单元更新机制,显着减少了所需的参数量。在计算机视觉领域中,卷积神经网络已经取得了很好的应用,迟早会延伸到自然语言处理研究中。目前,作为一种常用的网络单元,一维卷积已成功应用到多种序列模型问题的处理中,包括语义分割、快速机器翻译和某些序列转换网络中。由于更容易进行并行计算,与循环神经网络相比,一维卷积在训练速度上已提高了一个数量级。了解常见的NLP问题有许多任务,涉及到计算机与人类语言之间的交互,这可能对人类来说是一件简单的小事,但是给计算机带来了很大的麻烦。这主要是由语言中细微差异引起的,如讽刺、成语等。按照复杂程度,下面列出了当前还处于探索阶段的多个NLP领域:最常见的领域是情绪分析(Sentiment Analysis),这方面也许最为简单。它通常可归结为确定说话者/作者对某个特定主题的态度或情感反应。这种情绪可能是积极的、中性的和消极的。文末的链接1给出了一篇关于使用深度卷积神经网络学习Twitter情绪的经典文章。链接2的一个有趣实验偶然发现,深度循环网络也可用来辨识情绪。△ 生成对话网络中的多个激活神经元。明显看出,即使进行无监督训练,网络也能分辨出不同情绪类别。我们可以将这种方法应用到文件分类(Document Classification)中,这是一个普通的分类问题,而不是为每篇文章打几个标签。链接3的论文通过仔细比较算法间差异,得出深度学习也可作为一种文本分类方法的结论。接下来将要介绍一个真正有挑战的领域——机器翻译(Machine Translation)。这是一个与先前两个任务完全不同的研究领域。我们需要一个预测模型,来输出一个单词序列,而不是一个标签。在序列数据研究中,深度学习理论的加入给这个领域带来了巨大的突破。通过链接4的博文中,你可以了解更多关于循环神经网络在机器翻译中的应用。我们可能还想要构建一个自动文本摘要(Text Summarization)模型,它需要在保留所有含义的前提下,提取出文本中最重要的部分。这需要一种算法来了解全文,同时能够锁定文章中能代表大部分含义的特定内容。在端到端方法中,可以引入注意力机制(Attention Mechanisms)模块来很好地解决这个问题。关于注意力机制的详细内容可参考量子位先前编译过的文章《自然语言处理中的注意力机制是干什么的?》最后一个领域为自动问答(Question Answering),这是一个与人工智能极其相关的研究方向。相关模型不仅需要了解所提出的问题,而且需充分了解文本中的关注点,并准确地知道在何处寻找答案。关于深度学习在自动问答中的详细说明,请查看链接5的相关博文。△ GNMT英译法的注意力机制示意图。由于深度学习为各种数据(如文本和图像)提供相应的向量表征,你可以利用不同的数据特性构建出不同模型。于是,就有了图片问答(Visual Question Answering)研究。这种方式比较简单,你只需要根据给出图像,回答相应问题。这项工作简单到听起来好像一个七岁小孩就能完成,但是深层模型在无监督情况下不能输出任何合理的结果。链接6的文章给出了相关模型的结果和说明。总结我们可以发现,深度学习在自然语言处理中也取得了很好的效果。但是由于计算和应用等问题,我们仍需要进一步了解深度神经网络,一旦可以掌控深度学习,这将永远改变游戏规则。相关链接1.Twitter情绪分类:/uploads/pic/20230928/ 相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。










