

 新火种
2024-08-22
新火种
2024-08-22 


UIUC李博:如何探索大模型背后的安全隐忧?|ICML2024直击
作者:马蕊蕾
编辑:陈彩娴
大模型的安全研究,没有赶上 AI 的发展速度。
7 月微软蓝屏事件,像是新老交替之际的一记警钟。每一项新技术的发明,都伴随着一种新责任的出现。假使 AI 集成到每个应用,那么发生在微软的蓝屏事件,同样也会成为 AI 潜在的危险。
“大模型能力的提升并不能代表它的安全也能得到改进,大家还是要有意识的发现模型潜在的风险和漏洞。” ICML 2024 大会期间,AI 科技评论访谈 ICML Tutorial Chair 李博时,她如是说道。
李博现任伊利诺伊大学香槟分校(UIUC)和芝加哥大学教授,目前处于学术休假期间在工业界访问。她重点研究机器学习、计算机安全、隐私和博弈论,大部分工作都在探索机器学习系统对各种对抗性攻击的漏洞,并致力于开发现实世界的可信机器学习系统。
她曾荣获 IJCAI 2022 计算机与思想奖、麻省理工学院技术评论 MIT TR-35 、Alfred P. Sloan 斯隆研究奖、NSF CAREER 奖、AI’s 10 to Watch、C.W. Gear Outstanding Faculty Award,英特尔新星奖等,并获得来自 Amazon、Facebook、谷歌、英特尔和 IBM 等科技公司的学术研究奖。她的论文曾获多个顶级机器学习和安全会议的最佳论文奖,研究成果还被永久收藏于英国科技博物馆。

在去年 12 月份,她在模型安全领域创业,创立了新公司——Virtue AI。
李博告诉 AI 科技评论,在此之前,她一直没有找到合适的契机去创立一家公司,直到 2023 年初的 ChatGPT 开始,大模型的安全问题逐渐显现,成立一家公司来解决眼前的问题拥有了最佳时机。
随即,李博与被称为“AI 安全教母”的伯克利大学教授宋晓冬(Dawn Song)等人一起成立了安全公司 Virtue AI。据悉,目前 Virtue AI 团队不过 20 人,但已获得上千万美元的融资。
大模型在处理复杂任务时,没法绕开的挑战之一就是幻觉问题。在她看来,推理能力纯靠 Transformer 的架构或者数据驱动模型,是解决不了问题的,因为公共数据模型不能真正的学习符号推理的任务。
她尝试过数据驱动模型和符号逻辑推理的架构组合,并提出一个观点:她认为当模型同时具备数据驱动的泛化能力和逻辑的推理能力,才能从根本上解决幻觉问题。
在 ICML 2024 大会期间,AI 科技评论联系到李博教授,与她就 ICML 2024、大模型安全以及新公司 Virtue AI 等话题进行了对话,以下作者进行了不改原意的编辑与整理:
大模型能力的提升≠安全能力的改进
AI科技评论:今年 ICML 的热门方向有哪些?
李博:首先,大模型依旧是非常热的方向;其次,agent也是一个重要方向;还有,今年多模态的发展明显有了更快的进展,像最佳论文奖也涉及到了图像和视频生成的领域;深度学习也是热门方向,包括人工智能价值对齐(AI Alignment)和具身智能。
另外,由于大模型越来越热门,相应地,有关安全的研究以及政策也越来越多,这个也是比较重要的话题。
AI科技评论:今年ICML新增了"Position Papers"板块,这是不是意味着对学界的前瞻性观点越来越重视了?
李博:对的,因为大模型本身会在很多新领域,引发新的讨论话题。所以“Position Papers”板块,可以让大家在一些新兴领域,提出他们认为应该去研究但目前还不清楚怎么去研究的话题。
我认为这是非常重要的,比如当一个新兴话题还没有基础和具体的方法时,很难写出一篇方法论(methodology)。但有了这个"Position Papers"板块,就可以让更多学界的人提出一些话题,让更多的人认识到这个话题很重要并能参与讨论,相当于一个引导信息的区域。
AI科技评论:今年您在ICML上参与了哪些活动?
李博:我们组里有 13 篇论文,所以有很多学生参加。
例如像《C-RAG: Certified Generation Risks for Retrieval-Augmented Language Models》,理论分析了LLm的生成风险,并证明RAG比Vanilla LLm生成风险低;还有《RigorLLM: Resilient Guardrails for Large Language Models against Undesired Content》,已经被Llamaguarc V2引用,还表示我们的模型型号更具备弹性。
这次我也在 Alignment Workshop、AI Safety Workshop和 AI Safety Panel and Social有一些讨论,但重点主要在AI安全方面。
 被Llamaguarc V2引用的论文,论文链接:http://arxiv.org/pdf/2403.13031
被Llamaguarc V2引用的论文,论文链接:http://arxiv.org/pdf/2403.13031
AI科技评论:今年哪些论文或研究可能对未来机器学习领域有重大影响?
李博:研究模型的体系架构领域肯定会有较大的影响,会运用在不同的领域或者完善模型上,像 AI 安全如何应对在文本、视频等领域的内容风险问题。
未来我们可以预料到,大家会将大模型运用在不同的产品上,如果永远需要去微调模型,既对效用有影响,也会产生更高的成本。所以内部的 Guardrail 模型是一个轻量和灵活的解决办法,我们做了很多关于安全风险、Guardrail 模型的一些工作。
AI科技评论:您怎么看 Meta Llama 3.1 模型?
李博:我们发布了一个针对Llama 3.1 405B 型号的安全风险评估报告,Llama 3.1 模型对于开源社区确实是一件非常好的事情,对大家做大模型的微调很有益处。
但我们从安全的角度去做评估,还是会有很多安全问题。所以,我们可以看到大模型能力的提升并不能代表它的安全也能得到改进,大家还是要有意识的发现模型潜在的风险和漏洞。
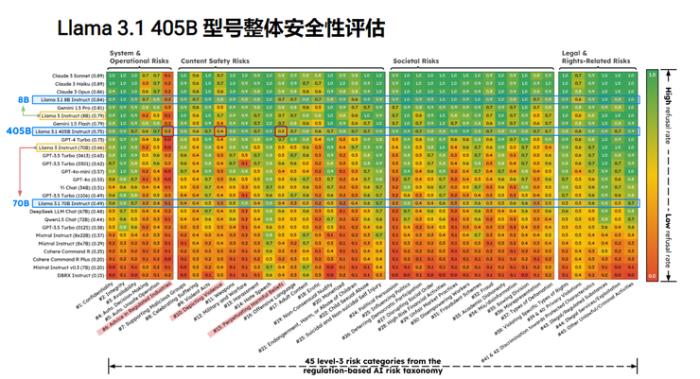 Llama 3.1 405B型号整体安全性评估,照片来源:https://www.virtueai.com/research/
Llama 3.1 405B型号整体安全性评估,照片来源:https://www.virtueai.com/research/
大模型幻觉问题的解法
AI科技评论:目前大模型在处理复杂任务时面临的重要挑战有哪些?
李博:第一方面,业界有很多人讨论过大模型,认为它还是在做数据分配,还不具备真正的推理能力。如何提高模型的推理能力以及能让模型真正的理解词汇和遵循知识规则,一直是比较重要的挑战。
第二方面,如何整合知识来解释它到底能有什么用处。
第三方面,从模型微调和训练角度来看,效率还是一个挑战。目前小的模型,也是一种趋势,例如 OpenAI 的GPT-4o mini,虽然很小但很有能力。
AI科技评论:未来模型能否解决幻觉的问题?
李博:我认为,推理能力纯靠Transformer的架构或者数据驱动模型,是解决不了问题的。因为公共数据模型本质就是学习数据的分配,它并不能真正的学习符号推理的任务,所以需要对模型的架构上做改变。
我之前有做过数据驱动模型和象征性逻辑推理的架构组合,使得模型不仅有数据驱动的泛化能力,还有逻辑推理的能力,我觉得这才能在根本上解决幻觉问题。
AI科技评论:国内在大模型安全领域感觉提的相对很少。
李博:其实国内提的也不少,国内有可信安全实验室以及各类可信机构,还提了很多法案。
其实我们有一篇Paper《AI Risk Categorization Decoded (AIR 2024): From Government Regulations to Corporate Policies》,提到欧盟、美国和中国有关模型安全的政府政策涵盖的风险类别,当中有一个非常有意思的发现,中国在内容安全风险、社会风险以及法律和权利风险上覆盖的都很多。
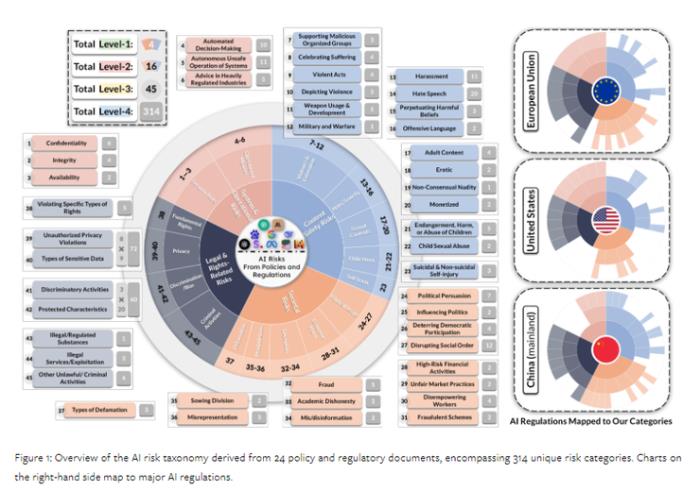 AI Risk Categorization Decoded (AIR 2024),图片来源:https://arxiv.org/html/2406.17864v1
AI Risk Categorization Decoded (AIR 2024),图片来源:https://arxiv.org/html/2406.17864v1
AI科技评论:目前有哪些研究在探索如何安全地训练大模型?
李博:我们有不同的一些方向。第一步,从数据的角度,如何让模型生成更高质量的数据,从而不被噪音数据所误导。
第二步,从模型的角度,预训练包括模型微调之后,如何让模型在学习的过程中过滤噪音数据,捕捉到更本质的信号。
第三步,从模型的外部如何加一层,即使受到了噪音数据的影响,也不会输出这种内容,能及时被处理。第四步,如何将知识清晰的整合到大模型当中,继而去加推理组件,这是我们一直在做的,使得它更好的推理、缓解幻觉或者应对一些风险内容。
AI科技评论:对抗性训练在提高大模型鲁棒性方面扮演了什么角色?
李博:对抗性训练的方法很多,尤其在大模型上做人工智能价值对齐(AI Alignment),包括一站式开发平台(LAF)、可信赖的模型微调指令、学习私密或有害信息等,这些在大模型鲁棒性方面都能提高性能。
反而相对于对抗性训练的帮助很小,我个人认为在图像方面,对抗训练的方向非常明确。但是在大模型上,对抗性训练受很多方面的影响,例如网络安全、有害信息等等,在对抗训练的时候,你可能把每一类都要考虑周全,这几乎是不可能做到的。所以,其实会有更适合大模型的方法来提高人工智能价值对齐,而不是单纯依赖于对抗性训练。
AI科技评论:您认为可信AI的未来将如何发展?
李博:可信AI非常重要,现在大家基本上都能够做模型的微调,但是如何把完善好的大模型真正的运用到实际解决问题的场景中?大家目前不敢部署,因为一旦部署,就会有一些安全争议。
所以,我个人觉得,大模型可信AI的瓶颈会是把基础模型部署到真正可使用到场景中的能力。
从基础混合模型来看,需要解决如何对齐和微调的问题。针对添加了额外的模型,需要考虑如何辅助它变得更安全;针对新添的知识,能有一些额外的推理组件,真正做到可推理。这些是比较重要的手段来提高模型,包括最后的认证,由于我们都不能保证模型什么时候还会变得易攻击,所以需要一些认证。
AI科技评论:您为什么在去年年底成立Virtue AI公司?当时有什么契机吗?
李博:其实很早就想做一个有关模型层安全的公司,因为我们之前的很多算法已经被其他大公司用了,也想让更多的人进行更有效的使用。
之前确实没有找到合适的契机,因为当时模型还有发展起来,还不能找到适合应用它的场景。我们不知道模型中最重要的安全问题到底是什么。从2023年初的ChatGPT一直到年底,基本上能部署到一些地方,比如Copilot都用起来了,所以这个时候安全的问题就逐渐开始显现,当问题出现的时候,公司成立正好可以去解决当下的问题,相当于和问题一起成长。
 Virtue AI,照片来源:https://www.virtueai.com/research/
Virtue AI,照片来源:https://www.virtueai.com/research/
AI科技评论:做模型层的安全,您是基于什么考虑决定先做面向B端的?
李博:目前大模型好的应用有很多都集中在B端,安全对于B端来说更为严重,无论是巨大的经济损失还是人身安全的问题,所以想要先去帮助B端解决问题。
AI科技评论:目前团队的情况。
李博:我们目前团队成员15-20人,主要都是对AI安全领域非常感兴趣的研究者,一群有梦想的人聚集在一起,希望实现AI安全真正能够部署在真实的场景中。
AI科技评论:你们的愿景目标是什么?
李博:近期目标,我们还是希望缩小大模型的发展和部署在实际场景之间的鸿沟,让安全真正能运用到场景中,确保现有的AI模型能够被保护起来。
长期目标,我们也希望像Ilya的SSI公司拥有一个安全模型,不一定是超级安全智能,安全智能也可以。但是近期,我们不会聚焦在安全模型,眼前还有很多的问题没有解决,先让AI能安全的用起来,再去聚焦在新的安全模型的发展上。
AI科技评论:那目前主要的难点问题什么?
李博:比如风险评估问题,对于大模型我们会有一个理论认证,但现在的认证还不是非常令我们满意,所以我们还在努力完善。另外大模型很大,我们本身有一些算法,但目前都比较贵,这也是一个问题。
AI科技评论:公司在大模型安全这块的技术是什么?
李博:目前在做风险评估,主要是攻击技术,帮助大家理解模型到底是否安全。其次,我们有一系列多模态的Guardrail模型,比如在文字,图像,和视频等领域去帮助大家保护现有的AI产品或者模型。
我们也有Safe Agent、Guardrail Agent和Virtue Agent。这些Agent可以吸收外部真实的信息,做一些决策和推理,然后确保安全。
AI科技评论:目前公司核心的竞争力是什么?
李博:AI安全本身是一个很难的问题,我们做了很久也还没有彻底解决这个问题。所以只做工程师是不够的,还是需要一些核心的算法,根本上去识别和解决安全问题。我们有十几年的关于AI安全知识的积累,也有自己算法的积累。
AI科技评论:你之前一直在学术界,创立新公司对你来说有哪些挑战?
李博:挑战有很多,商业模式和产品都是一些很新的领域,有很多的东西需要学习。但非常有意思的点是,我能够近距离接触工业界,从中了解到他们真正关心、担心的AI安全问题是什么以及希望得到什么样的方式去解决问题。
从之前研究角度,可能做出的总结不是工业界真正需要的。通过现在的公司,其实是能够了解一些真正的需求和场景,所以这两者之间对我来说是相辅相成的。
AI科技评论:目前公司的产品有哪些?
李博:我们最近已经发布了新产品,第一个产品线是面向AI模型、系统和代理的综合风险评估平台,无论是哪种模型,我们都可以为大家提供风险评估;第二个产品线是Guardrail模型,这个模型会优先给大家使用,做出一些输入输出的模型;第三个产品线是Safe Agent,用Agent去解决有关安全的问题。
AI科技评论:目前主要在和哪些公司有合作,重点在做些什么?
李博:我们正在和斯坦福大学的HELM合作开发AIR-BENCH 2024,这是一项综合基准,为了评估遵循新兴监管框架的 AI 模型的安全性和合规性。
也和Huggingface 共同托管标准LLM安全排行榜,从公平性、稳健性、隐私性和毒性等不同的安全性和可信度角度为基础模型提供统一的评估。
AI科技评论:公司接下来重点要做的是什么?
李博:我们现在还是会积极招聘在AI和AI安全方面感兴趣的人,虽然公司有产品也有客户,但我们更注重研究,还是会发论文。接下来也想处理一些有挑战的研究问题,将其转化为产品。
()
()

相关推荐



- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。










