

 新火种
2024-06-03
新火种
2024-06-03 

AI读论文新神器:多栏密集文字、中英图文混排文档都能读|旷视
虽然多模态大模型都能挑西瓜了,但理解复杂文档方面还是差点意思。
面对文字密集、多栏混排等文档时往往力不从心,区域级别的细粒度理解,就更是无从谈起了。
最近,旷视团队打造了一支多模态大模型的“点读笔”——Fox,轻松实现对8页文档(中英混合,单栏多栏格式混合的极端场景)的交互式感知理解。
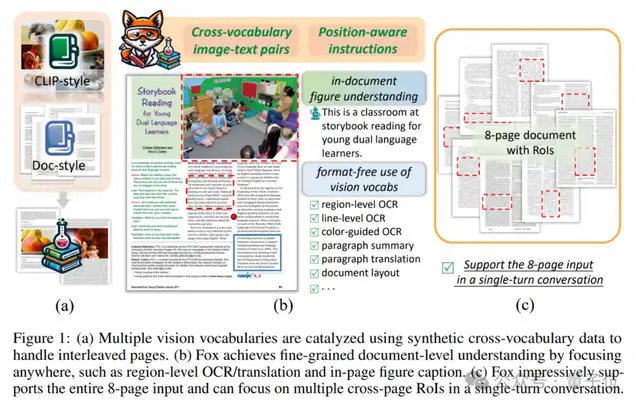
对于信息密集的PDF文档,Fox支持高可控性的细粒度理解,比如在用户感兴趣区域内进行文字识别、段落翻译以及页面内部的图片内容描述等。
论文中,团队进一步突破了对于文档的视觉感知理解的上限,高密度的信息被真正压缩,LVLM真正地“看”懂图,才能真正做好、做出能用的文档多模大模型。
正所谓“一图胜千言”—— one image token >> one text token。

接下来,看看Fox在实战中表现如何?
中英混排,单栏多栏组合都不怕
对于中英混合、单栏多栏混合的8页PDF文档,可实现任意区域的OCR:

下图左侧展示了8页文档内跨页的VQA,右侧展示了双栏中文页面的前景OCR。

双栏密集英文页面的前景OCR:

在页面内图片描述方面,Fox能给出文档内内容关联的回答(young Dual Language Learners)。
当然Fox还支持line-level OCR,以及对RoI区域的翻译、总结等。

Fox可以结合页面内文字,认识到这是一张关于global seismic hazards的图。此外,Fox还支持RoI内的latex格式转换,例如下面的table转latex。Fox还支持更加灵活的颜色引导的RoI区域OCR。

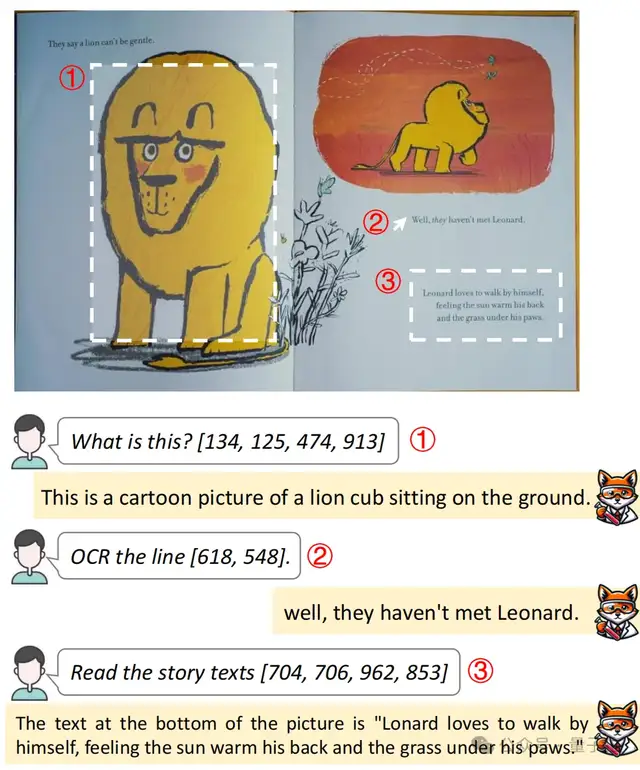
对于卡通绘本,也可以哪里不会点哪里:
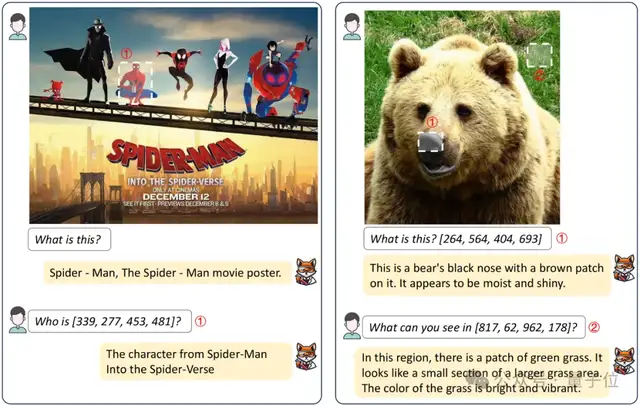
电影海报和自然场景的对话问答,Fox给出了非常有趣的答案(根据电影海报下面的文字给出了角色来源):
那么Fox是如何做到这些的呢?
多词表协同,多页面文档统一打包
在细粒度文档理解上,Fox有着三大创新:
精准定位
Fox引入了一系列基于位置的文本提示,如点击位置、拖动框、涂色框等。这使得模型可以直接定位到感兴趣的任意区域,而不受文档格式的限制。同时,Fox还把全页OCR重新定义为”前景聚焦”任务,进一步增强了对密集文字的感知。
多视觉词表协同
为了更好地理解图文混排页面,Fox采用了两个不同特长的视觉词表——CLIP主攻自然图像,Vary专攻人工文档。但单纯叠加两种数据,往往会造成视觉偏置。为此,Fox合成了大量含混合视觉元素的数据,迫使两个视觉分支充分协作。
页面打包
得益于高压缩率(每页1024×1024图像对应256个图像token),Fox将多页面文档统一打包输入。这不仅让跨页面的上下文理解成为可能,也大幅降低了计算开销。值得一提的是,这种打包微调模式并不需要重新训练视觉词汇。
在这些创新基础上,Fox模型结构如图所示。
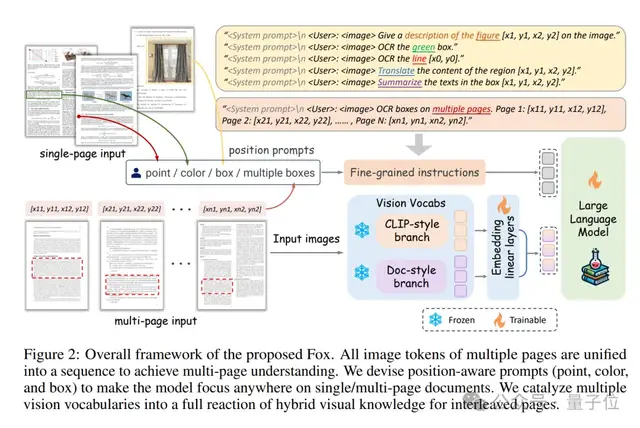
Fox支持单页/多页文档图像输入,所有图像的image token被统一到一个sequence中进行多页文档理解。团队设计了基于point、color、box的prompt,来实现在文档页面上聚焦任意位置。团队合成了图文交织的文档数据,来充分催化两个视觉词表,以更好地适用于实际文档应用场景。
此外,为了促进对文档细粒度理解的研究,作者还打造了一个中英双语的benchmark,已经开源了数据和评测代码,共包含以下9种任务:
Page-level OCRRegion-level OCRLine-level OCRColor-guided OCRRegion-level translationRegion-level summaryIn-document figure captionMulti-page multi-region OCRCross-page VQA
最后,团队呼吁更多的研究人员能关注到细粒度的单页/多页文档理解,单页的稀疏的问答任务远远不够。
真正做好多模态大模型,视觉编码器的信息压缩率(token转化率)是非常重要的,Fox仅探究了文档这一类应用方向,希望对大家的研究有所帮助。
想了解更多细节,请查看原论文。
相关推荐



- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。










