新火种
2024-05-29
新火种
2024-05-29 


国产开源Sora上新:全面支持国产AI算力,可用ReVideo视频编辑,北大-兔展团队出品
北大-兔展联合发起的Sora开源复现计划Open-Sora-Plan,今起可以生成最长约21秒的视频了!
生成的视频水平,如下展示。先看这个长一点的,9.2s:

下面这段人形机器人种花要短一点,是2.7s:

当然了,老规矩,这一次的所有数据、代码和模型,继续开源。
目前,Open-Sora-Plan在GitHub上有10.4k颗星星,大家可以选择去抱抱脸上激情试玩。
该说不说,版本迭代速度还挺快——上个月,Open-Sora-Plan就在开源社区上新过一波。
当时能支持单镜头16秒的视频生成,分辨率最高720p,能满足的生成需求也比较多样。
这次版本更新,背后主要是两个方面有了进步:
采用了更高质量视觉数据与caption优化了CausalVideoVAE的结构
团队还表示,Open-Sora-Plan已经支持使用国产AI计算系统(华为昇腾,期待更多国产算力芯片)进行完整的训练和推理。
 Open-Sora-Plan v1.1.0展示
Open-Sora-Plan v1.1.0展示此次更新的版本是Open-Sora-Plan v1.1.0。
项目团队对Open-Sora-Plan的现阶段能力进行了三个层面的展示,并注明演示背后是用3k小时视频数据。
首先展示的是10秒版文生视频(10s×512×512)。
这张图的Prompt是,“蓝色时刻圣托里尼岛的鸟瞰图,展示了令人惊叹的建筑”。

这张图的Prompt是,“摄像机对准一大堆老式电视机,所有电视机都显示不同的画面”。

其次展示的是2秒版文生视频(2s×512×512)。
给出的效果展示,有经典的小狗子,“一只戴着贝雷帽和黑色高领毛衣的柴犬”。

还有一幅画,画面上航船前行,波涛拍打:

团队展示的第三类,是用Open-Sora-Plan v1.1.0进行视频编辑(2s×512×512)。
据了解,这部分内容采用的是联合团队刚提出来的ReVideo模型。
不论是小猫戴墨镜:

还是天空飘气球:

在画面连续性和角色一致性方面都表现得还算不错。
当然,团队承认“但我们仍然离Sora有一段距离”,同时给出了失败案例展示。
例如,团队对比了4倍时间和2倍时间下采样的重建视频,发现视频在重建细粒度特征时,画面都会发生抖动。
这表明减少时间下采样并不能完全解决抖动问题。
并且用v1.1.0生成的雪地里的小狗,视频中的小狗头出现了Semantic distortion的问题,似乎模型不能很好的判断哪个头是哪个狗的。
这个问题其实在OpenAI的Sora的早期基座模型也会出现……
因此Open-Sora-Plan的团队成员认为,也许可以通过扩大模型和数据量来解决问题,达到更好的效果。
团队还提到,视频生成与图片生成最大的不同,在于其动态性,即物体在连续的镜头中发生一系列动态变化。
然而v1.1.0生成的视频仍然存在许多有限动态的视频。
团队通过翻看大量的训练视频发现,这些素材网爬取的视频虽然画面质量很好,然而充斥着一些无意义的特写镜头;而这些特写镜头往往变化幅度很小,甚至处于静止状态。
同时,团队还发现negative prompt可以显著提高视频质量——这意味着也许需要在训练数据中加入更多先验知识。
 △without negative prompt生成的小狗视频
△without negative prompt生成的小狗视频除了对方给出的展示,目前大家都可以在Hugging Face上试玩。
需要注意啦,由于视频生成可能需要150个左右的步骤才能产生良好的结果,试玩时生成每个视频大约需要4-5mins。
背后技术
整体框架上,Open-Sora-Plan由三部分组成:
Video VAEDenoising Diffusion Transformer(去噪扩散型Transformer)Condition Encoder(条件编码器)
这和Sora技术报告的内容基本差不多。
此次更新的Open-Sora-Plan v1.1.0是一个基于Transformer的文本到视频模型,经过T5文本嵌入的训练。

与之前的工作类似,整个训练过程采用多阶段的级联的训练方法,分三个阶段。
其中,第二阶段采用了华为昇腾算力进行训练,该阶段的训练、推理完全由国产芯片支持。
目前,仍然在训练和不断观察第三阶段的模型——增加帧数到513帧,大约是24FPS的21秒的视频。

相比上个月发布的前作Open-Sora-Plan v1.0.0,最新版本主要2个方面的优化。
一是优化了CausalVideoVAE的结构,二是采用了更高质量的视觉数据与captions。
– 优化CausalVideoVAE的结构
优化CausalVideoVAE的结构,让Open-Sora-Plan v1.1.0拥有比前作更强的性能、更高的推理效率。
来看过程:
模型结构
随着生成视频帧数不断增加,CausalVideoVAE的encoder开销逐渐增加;当训练257帧时,80G的显存不足以让VAE encode视频。
因此,团队减少CausalConv3D的数量,只保留encoder的最后两个stage的CausalConv3D。
它能够几乎保持原有的性能的情况下大幅度降低开销。
注意,这里只修改encoder,decoder的仍然保留所有的CausalConv3D,因为训练Diffusion Model不需要decoder。
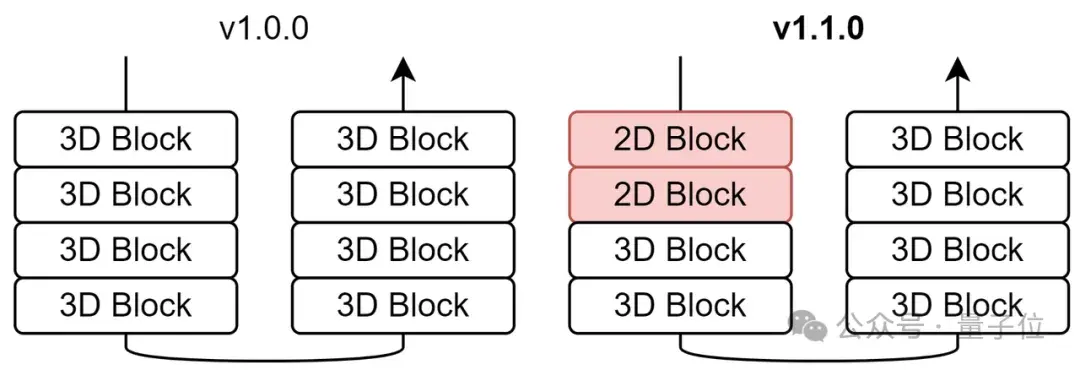 Temoral Module
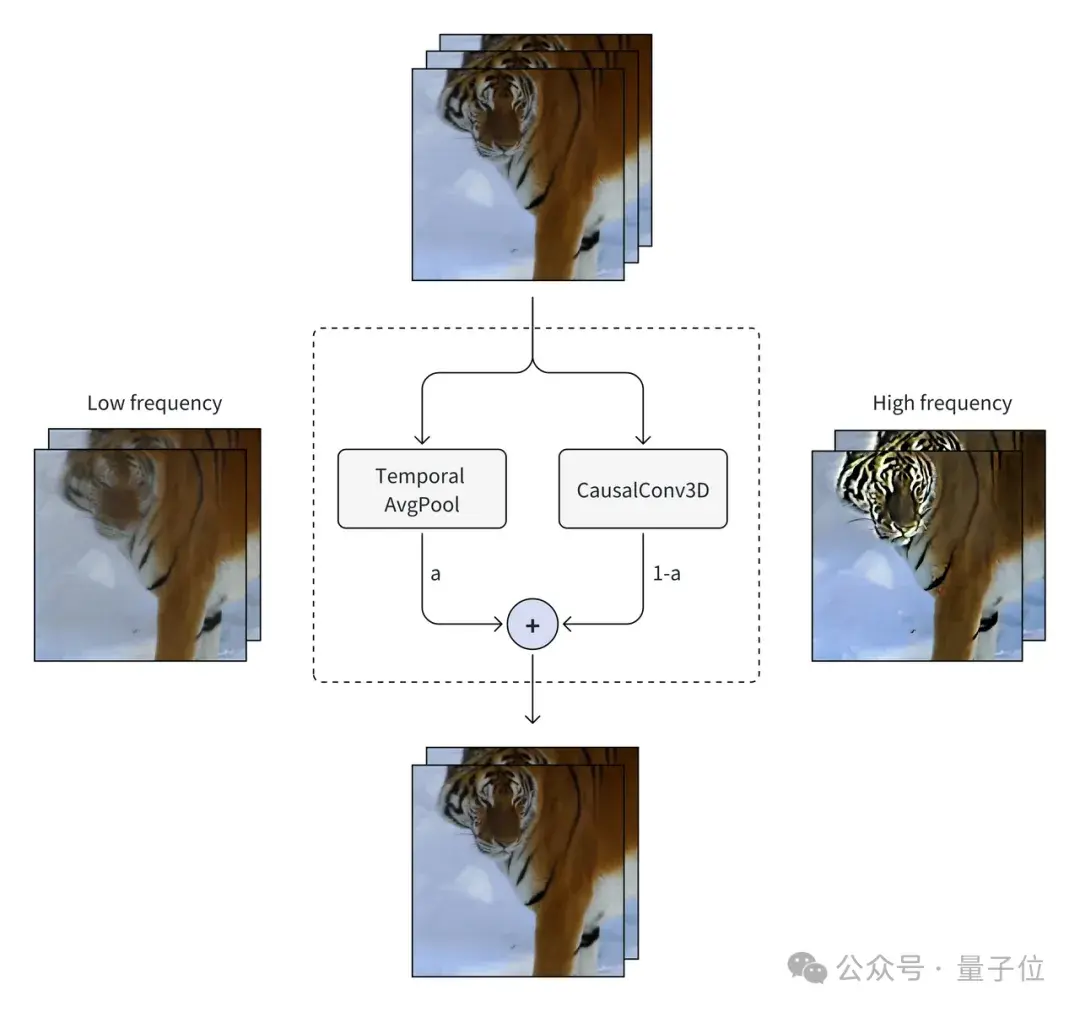
Temoral Module而在v1.0.0,Open-Sora-Plan的temporal module只有一个TimeAvgPool,AvgPool会导致视频中的高频信息(如细节和边缘)丢失。
为了解决这个问题,团队在v1.1.0中改进该模块,引入了卷积并增加了可学习的权重,以期望不同分支能够解耦不同特征。
当忽略CasualConv3D时,视频将会被重建得非常模糊;同样的,当忽略TemporalAvgPool,视频会变得非常锐利。
 训练细节
训练细节同时,和v1.0.0一样,团队从Latent Diffusion的VAE初始化,采用tail initialization。
对于CasualVideoVAE,研究人员在第一阶段训练100k steps with the video shape of 9×256×256。
进一步,研究人员将9帧提高到25帧,发现增加视频帧数还能显著提高模型性能。
需要特别澄清的是,第一阶段和第二阶段团队开启mixed factor,在训练结束时a(sigmoid(mixed factor))的值为0.88,这意味着模型倾向于保留低频信息。
研究人员在第三阶段将mixed factor初始化为0.5(sigmoid(0.5)=0.6225),最终模型能力得到进一步提升。
损失函数
研究人员发现GAN Loss能够保留高频信息和缓解网格效应。
同时还发现将2D GAN改成3D GAN能有进一步提升。
Inference Tricks
在v1.0.0中,团队采用spatial tiled convolution,它能够以几乎恒定的内存推理任意分辨率的视频。
然而随着帧数变多,VAE encoder的开销不断增加。
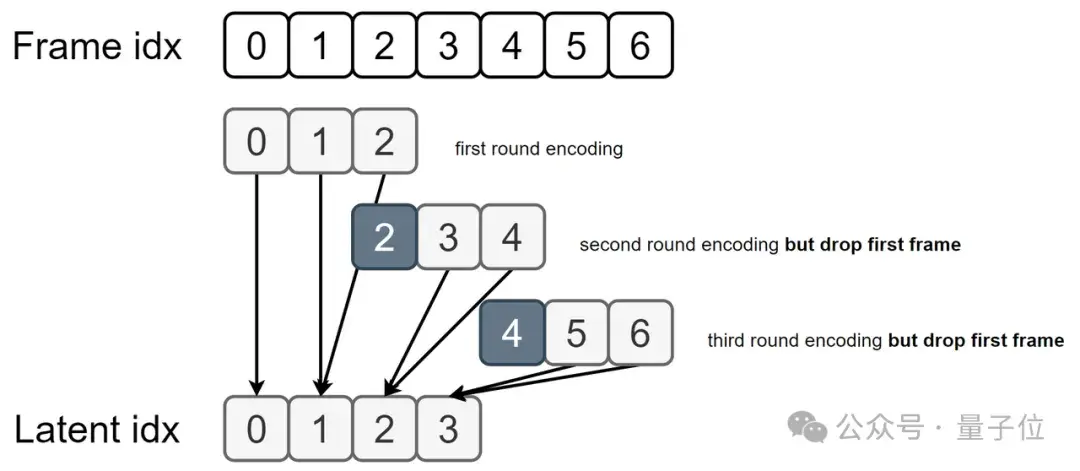
因此新版本引入一个方法叫做temporal rollback tiled convolution,它是专门为了CausalVideoVAE而设计的一种tiled方法。
具体来说,除了第一个窗口以外的窗口都将抛弃第一帧,因为窗口内的第一帧被看作图片,然而其余帧都应该被当作视频帧。
 – 采用更高质量的视觉数据与caption
– 采用更高质量的视觉数据与caption接下来介绍第二个优化部分,即Open-Sora-Plan v1.1.0采用了更高质量的视觉数据与caption,这使得模型对世界运行规律有了更好的理解。
由于Open-Sora-Plan支持图片视频联合训练,因此数据收集分为图片和视频2个部分,且图片数据集和视频数据集是两个独立的数据集。
团队注明,大概花费了32×240个H100 hours生成image and video captions——这些也全部开源。
 图片收集管道
图片收集管道研究人员从Pixart-Alpha获取了11M个图像文本对,他们的caption由LLaVA生成。
团队还注意到了高质量的OCR数据集Anytext-3M,这个数据集每一个图片都配对了相对应的OCR字符。但这些caption不足以描述整个图片。因此,团队采用InternVL-1.5进行补充描述。
由于T5只支持英文,所以研究人员筛选了英文数据参与训练,这约有完整数据的一半。
另外还从Laion-5B中筛选高质量图片以提高生成人类的质量,筛选规则主要包括:高分辨率、高美学分数、无水印的包含人的图片。
视频收集管道
在v1.0.0中,团队对视频采样1帧来生成caption。
然而随着视频时长增加,一帧图片无法描述整个视频的内容,也无法描述时序上的镜头移动。
因此现在采用video captioner对整个video clip生成caption——具体地,采用ShareGPT4Video,它能够很好的覆盖时间信息并且描述整个视频内容。
值得注意的是,v1.1.0的视频数据集大约有3k小时,而v1.0.0版本仅有0.3k小时。
与之前一样,团队开源所有的文本注释和视频(均为CC0协议)。
One More Thing
最后,Open-Sora-Plan表示,接下来的工作主要围绕两个方面进行。
一是数据缩放,重点关注数据来源和数据体量。
二是模型设计,主要会对CasualVideoVAE和扩散模型下手。
不变的是,无论如何更迭,所有数据、代码和模型都会继续开源。

有上抱抱脸手动体验了的朋友们,欢迎在评论区分享试玩感受呀~
相关推荐



- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。