

 新火种
2023-09-26
新火种
2023-09-26 


使用TensorFlow进行语音识别.js – 语音命令

当我还是个孩子的时候,几乎每个超级英雄都有一台语音控制的计算机。所以你可以想象我第一次遇到Alexa对我来说是一次深刻的经历。我心里的孩子非常高兴和兴奋。当然,然后我的工程直觉开始发挥作用,我分析了这些设备是如何工作的。
事实证明,他们有神经网络来处理这个复杂的问题。事实上,神经网络大大简化了这个问题,以至于今天使用Python在计算机上制作这些应用程序之一非常容易。但情况并非总是如此。第一次尝试是在 1952 年进行的。由三位贝尔实验室研究人员撰写。
他们建立了一个具有10个单词词汇的单扬声器数字识别系统。然而,到1980年代,这一数字急剧增长。词汇量增长到20,000个单词,第一批商业产品开始出现。Dragon Dictate是首批此类产品之一,最初售价为9,000美元。Alexa今天更实惠,对吧?
但是,今天我们可以在浏览器中使用Tensorflo.js执行语音识别。在本文中,我们将介绍:
迁移学习语音识别如何工作?演示使用Tensorflow实现.js1. 迁移学习
从历史上看,图像分类是普及深度神经网络的问题,尤其是视觉类型的神经网络——卷积神经网络(CNN)。今天,迁移学习用于其他类型的机器学习任务,如NLP和语音识别。我们不会详细介绍什么是 CNN 以及它们是如何工作的。然而,我们可以说CNN在2012年打破了ImageNet大规模视觉识别挑战赛(ILSVRC)的记录后得到了普及。
该竞赛评估大规模对象检测和图像分类的算法。他们提供的数据集包含 1000 个图像类别和超过 1 万张图像。图像分类算法的目标是正确预测对象属于哪个类。自2年以来。本次比赛的每位获胜者都使用了CNN。
训练深度神经网络可能具有计算性和耗时性。要获得真正好的结果,您需要大量的计算能力,这意味着大量的GPU,这意味着......嗯,很多钱。当然,您可以训练这些大型架构并在云环境中获得SOTA结果,但这也非常昂贵。
有一段时间,这些架构对普通开发人员不可用。然而,迁移学习的概念改变了这种情况。特别是,对于这个问题,我们今天正在解决 - 图像分类。今天,我们可以使用最先进的架构,这些架构在 ImageNet 竞赛中获胜,这要归功于迁移学习和预训练模型。
1.1 预训练模型
此时,人们可能会想知道“什么是预训练模型?从本质上讲,预训练模型是以前在大型数据集(例如 ImageNet 数据集)上训练的保存网络 。 有两种方法可以使用它们。您可以将其用作开箱即用的解决方案,也可以将其与迁移学习一起使用。 由于大型数据集通常用于某些全局解决方案,因此您可以自定义预先训练的模型并将其专门用于某些问题。
通过这种方式,您可以利用一些最著名的神经网络,而不会在训练上浪费太多时间和资源。此外,您还可以 通过修改所选图层的行为来微调这些模型。整个想法围绕着使用较低层的预训练CNN模型,并添加额外的层,这些层将为特定问题定制架构。
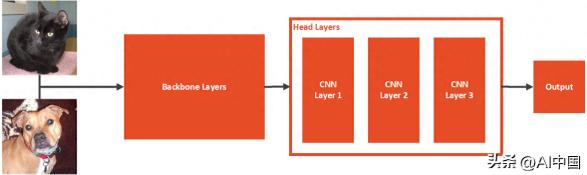
从本质上讲,严肃的迁移学习模型通常由两部分组成。我们称它们为骨干和头脑。 主干通常是在 ImageNet 数据集上预先训练的深度架构,没有顶层。Head 是图像分类模型的一部分,用于预测自定义类。
这些层将添加到预训练模型的顶部。有了这些系统,我们有两个阶段:瓶颈和培训阶段。在瓶颈阶段,特定数据集的图像通过主干架构运行,并存储结果。在训练阶段,来自主干的存储输出用于训练自定义层。

有几个领域适合使用预先训练的模型,语音识别就是其中之一。此模型称为语音命令识别器。从本质上讲,它是一个JavaScript模块,可以识别由简单英语单词组成的口语命令。
默认词汇“18w”包括以下单词:从“零”到“九”、“向上”、“向下”、“向左”、“向右”、“开始”、“停止”、“是”、“否”的数字。还提供其他类别的“未知单词”和“背景噪音”。除了已经提到的“18w”字典之外,还有更小的字典“directional4w”可用。它只包含四个方向词(“上”、“下”、“左”、“右”)。
2. 语音识别如何工作?
当涉及到神经网络和音频的组合时,有很多方法。语音通常使用某种递归神经网络或LSTM来处理。但是,语音命令识别器使用称为卷积神经网络的简单体系结构,用于小占用量关键字发现。
这种方法基于我们在上一篇文章中研究的图像识别和卷积神经网络。乍一看,这可能会令人困惑,因为音频是一个跨时间的一维连续信号,而不是 2D 空间问题。
2.1 谱图
此体系结构使用频谱图。这是信号频率频谱随时间变化的视觉表示。从本质上讲,定义了单词应该适合的时间窗口。
这是通过将音频信号样本分组到段来完成的。完成此操作后,将分析频率的强度,并定义具有可能单词的段。然后将这些片段转换为频谱图,例如用于单词识别的单通道图像:

然后,使用这种预处理制作的图像被馈送到多层卷积神经网络中。
3. 演示
您可能已经注意到,此页面要求您允许使用麦克风。这是因为我们在此页面中嵌入了实现演示。为了使此演示正常工作,您必须允许它使用麦克风。
现在,您可以使用命令“向上”,“向下”,“向左”和“右”在下面的画布上绘制。继续尝试一下:
4. 使用TensorFlow实现.js
4.1 网页文件
首先,让我们看一下我们实现的 index.html 文件。在上一篇文章中,我们介绍了几种安装TensorFlow.js的方法。其中之一是将其集成到HTML文件的脚本标记中。这也是我们在这里的做法。除此之外,我们需要为预训练的模型添加一个额外的脚本标记。以下是索引.html的外观:
TensorFlow.js Speech Recognition
Using pretrained models for speech recognition
包含此实现的 JavaScript 代码位于 script.js 中。此文件应与 index.html 文件位于同一文件夹中。为了运行整个过程,您所要做的就是在浏览器中打开索引.html并允许它使用您的麦克风。
4.2 脚本文件
现在,让我们检查整个实现所在的 script.js 文件。以下是主运行函数的外观:
async function run() { recognizer = speechCommands.create('BROWSER_FFT', 'directional4w'); await recognizer.ensureModelLoaded(); var canvas = document.getElementById("canvas"); var contex = canvas.getContext("2d"); contex.lineWidth = 10; contex.lineJoin = 'round'; var positionx = 400; var positiony = 500; predict(contex, positionx, positiony);}在这里我们可以看到应用程序的工作流程。首先,我们创建模型的实例并将其分配给全局变量识别器。我们使用“directional4w”字典,因为我们只需要“up”,“down”,“left”和“right”命令。
然后我们等待模型加载完成。如果您的互联网连接速度较慢,这可能需要一些时间。完成后,我们初始化执行绘图的画布。最后,调用预测方法。以下是该函数内部发生的情况:
function calculateNewPosition(positionx, positiony, direction){ return { 'up' : [positionx, positiony - 10], 'down': [positionx, positiony + 10], 'left' : [positionx - 10, positiony], 'right' : [positionx + 10, positiony], 'default': [positionx, positiony] }[direction];}function predict(contex, positionx, positiony) { const words = recognizer.wordLabels(); recognizer.listen(({scores}) => { scores = Array.from(scores).map((s, i) => ({score: s, word: words[i]})); scores.sort((s1, s2) => s2.score - s1.score); var direction = scores[0].word; var [x1, y1] = calculateNewPosition(positionx, positiony, direction); contex.moveTo(positionx,positiony); contex.lineTo(x1, y1); contex.closePath(); contex.stroke(); positionx = x1; positiony = y1; }, {probabilityThreshold: 0.75});}这种方法正在做繁重的工作。从本质上讲,它运行一个无限循环,其中识别器正在倾听您正在说的话。请注意,我们正在使用参数 probabilityThreshold。
此参数定义是否应调用回调函数。实质上,仅当最大概率分数大于此阈值时,才会调用回调函数。当我们得到这个词时,我们就得到了我们应该画的方向。
然后我们使用函数 calculateNewPosition 计算线尾的坐标。该步长为 10 像素,这意味着行的长度将为 10 像素。您可以同时使用概率阈值和此长度值。获得新坐标后,我们使用画布绘制线条。就是这样。很简单,对吧?
结论
在本文中,我们看到了如何轻松使用预先训练的 TensorFlow.js 模型。它们是一些简单应用程序的良好起点。我们甚至构建了一个此类应用程序的示例,您可以使用它使用语音命令进行绘制。这很酷,可能性是无穷无尽的。当然,您可以进一步训练这些模型,获得更好的结果,并将它们用于更复杂的解决方案。这意味着,您可以真正利用迁移学习。然而,这是另一个时代的故事。
原文标题:Speech Recognition with TensorFlow.js – Voice Commands
原文链接:https://rubikscode.net/2022/05/11/drawing-with-voice-speech-recognition-with-tensorflow-js/
编译:LCR
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。










