

 新火种
2024-04-19
新火种
2024-04-19 


终端侧生成式AI时代已经到来,高通以领先AI软硬件技术赋能AIGC应用创新
4月17日,中国AIGC产业峰会在北京召开。本次峰会以“你好,新应用”为主题,邀请到生成式AI应用、AI基础设施和模型层的代表企业,一同分享对最新生成式AI现状与趋势的见解。在本次峰会上,高通公司的AI产品技术中国区负责人万卫星发表了关于“推动终端侧生成式AI时代到来”的主题演讲。他强调了终端侧生成式AI时代的到来,并提到高通发布的第三代骁龙8和骁龙X Elite平台已经或即将赋能众多AI手机和AI PC产品。万卫星详细介绍了高通AI引擎及其组成部分,还展示了高通异构计算能力的端到端用例。此外,万卫星也介绍了高通AI软件栈和AI Hub,这些将极大地提升开发者在模型开发、优化和部署方面的效率,进而有助于创造出更多创新的AI应用。

演讲全文如下:
早上好,非常高兴能够参加本次中国AIGC产业峰会,与各位嘉宾朋友一起迎接生成式AI时代的到来,为大家分享高通作为芯片厂商提供的产品和解决方案,能够如何推动AIGC相关产业的规模化扩展。
我们认为终端侧生成式AI时代已经到来,高通在2023年10月发布的第三代骁龙8和骁龙X Elite这两款产品上,已经实现了将大语言模型完整的搬到了端侧运行,且已经或即将赋能众多的AI手机和AI PC。在手机方面,去年年底和今年年初众多OEM厂商发布的Android旗舰产品,包括三星、小米、荣耀、OPPO和vivo等,都已经具备了在端侧运行生成式AI的能力。
基于图像语义理解的多模态大模型发展是当下的重要趋势,在今年2月的MWC巴塞罗那期间,高通也展示了全球首个在Android手机上运行的多模态大模型(LMM)。具体来说,我们在搭载第三代骁龙8的参考设计上运行了基于图像和文本输入、超过70亿参数的大语言和视觉助理大模型(LLaVa),可基于图像输入生成多轮对话。具有语言理解和视觉理解能力的多模态大模型能够赋能诸多用例,例如识别和讨论复杂的视觉图案、物体和场景。设想一下,有视觉障碍的用户就可以在终端侧利用这一技术,实现在城市内的导航。同时,高通在骁龙X Elite上也演示了全球首个在Windows PC上运行的音频推理多模态大模型。
接下来看看高通作为芯片厂商,如何满足生成式AI多样化的要求。不同领域的生成式AI用例具有多样化的要求,包括按需型、持续型和泛在型用例,其背后所需的AI模型也是千差万别,很难有一种可以完美适用所有生成式AI用例或非生成式AI用例。比如,有些用例需要进行顺序控制,对时延比较敏感;有些用例是持续型的,对算力和功耗比较敏感;有些用例需要始终在线,对功耗尤其敏感。
高通公司推出的高通AI引擎就是领先的异构计算系统,它包含多个处理器组件,包括通用硬件加速单元CPU和GPU、专门面向高算力需求的NPU,以及高通传感器中枢,它们在AI推理过程中扮演不同角色。前面提到的顺序执行的按需型任务,可以运行在CPU或GPU上;对AI算力要求比较高的持续型任务,例如影像处理、生成式AI等,都可以运行在NPU上;对于需要始终在线、对功耗尤其敏感的任务,可以运行在高通传感器中枢上。
我来为大家简单介绍一下高通NPU的演进路线,这是非常典型的由上层用例驱动底层硬件设计的案例。2015年及更早之前,AI主要用于一些比较简单的图像识别、图像分类用例,所以我们给NPU配置了标量和向量加速器。到2016—2022年间,计算摄影概念开始流行,我们把研究方向从图像分类转移到了AI计算、AI视频等等,包括对自然语言理解和处理的支持,以及对Transformer模型的支持,我们给NPU硬件在标量和向量加速器的基础之上,增加了张量加速器。2023年,大模型热度很高,我们在业内率先完成了端侧的大模型支持,给NPU配置了专门的Transformer加速模块。2024年,我们会重点支持多模态模型的端侧化,以及支持更高参数量的大语言模型在端侧的部署。
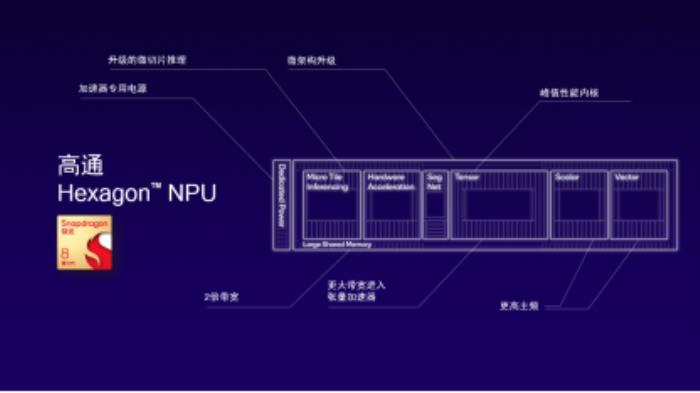
接下来为大家更深入的介绍高通HexagonNPU。第三代骁龙8上的HexagonNPU不仅进行了微架构升级,还专门配置了独立的供电轨道,以实现最佳的能效。我们还通过微切片推理技术支持网络深度融合,获取更极致的性能。此外HexagonNPU还集成了专门为生成式AI打造的Transformer加速模块,更高的DDR传输带宽,更高的IP主频等先进技术。所有这些技术相结合,使得HexagonNPU成为面向终端侧生成式AI的行业领先NPU。
接下来看一个具体案例,虚拟化身AI助手——这是非常典型的充分利用高通异构计算能力的端到端用例。它包括众多复杂AI工作负载,首先需要自动语音识别(ASR)模型负责将语音信号转成文本,这部分工作负载可以跑在高通传感器中枢上;接下来会由大语言模型负责处理文本输入,生成回复和对话,这部分工作负载可以跑在NPU上;再通过文本生成语音(TTS)模型把文本输出转变成语音信号,这部分负载可以跑在CPU;最后由GPU模块负责基于语音输出同步完成虚拟化身渲染,这样就能得到一个端到端的用语音来交互的虚拟化身助手用例。
前面介绍了硬件技术,接下来分享一下高通平台的AI性能。在智能手机领域,第三代骁龙8不管是在鲁大师AIMarkV4.3、安兔兔AITuTu这些AI基准测试的总分方面,还是在MLCommon MLPerf推理:MobileV3.1的具体模型推理性能测试方面,表现都远超于竞品。在PC方面,骁龙X Elite在面向Windows的ULProcyonAI推理基准测试中,表现也超过了基于X86架构的竞品。
高通除了提供领先的硬件平台设计之外,也推出了一个跨平台、跨终端、跨操作系统的统一软件栈,叫做高通AI软件栈(QualcommAIStack)。高通AI软件栈支持所有目前主流的训练框架和执行环境,我们还为开发者提供不同级别、不同层次的优化接口,以及完整的编译工具链,让开发者可以在骁龙平台上更加高效的完成模型的开发、优化和部署。值得强调的是,高通AI软件栈是一个跨平台、跨终端的统一解决方案,所以开发者只要在高通和骁龙的一个平台上完成模型的优化部署工作,便可以非常方便的将这部分工作迁移到高通和骁龙的其他所有产品上。

今年MWC巴塞罗那期间,高通发布了非常重量级的产品,高通AI Hub(QualcommAIHub)。该产品面向第三方开发者和合作伙伴,可以帮助开发者更加充分的利用高通和骁龙底层芯片的硬件算力,开发出自己的创新AI应用。利用高通AIHub进行应用开发的过程就像“把大象塞进冰箱”一样简单。第一步,根据用例选择所需模型;第二步,选择需要部署的高通或骁龙平台;第三步,只需要写几行脚本代码,就可以完成整个模型部署,在终端侧看到应用或算法的运行效果。
目前,高通AI Hub已经支持超过100个模型,其中有大家比较关心的生成式AI模型,包括语言、文本和图像生成,也包括传统AI模型,例如图像识别、图像分割,自然语言理解、自然语言处理等等。具体的模型信息,欢迎大家访问高通AI Hub网站(AIHUB.QUALCOMM.COM)进行查询。
最后总结一下高通的AI领先优势。第一,高通具备无与伦比的终端侧AI性能;第二,高通具备顶尖的异构计算能力,使AI能力能够贯穿整个SoC,将CPU、GPU、NPU和高通传感器中枢的能力都充分释放给应用开发者;第三,我们提供可扩展的AI软件工具,即前面提到的高通AI软件栈等;最后,我们可以支持广泛的生态系统和AI模型。
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。










