新火种
2024-04-18
新火种
2024-04-18 



北大字节开辟图像生成新范式!超越Sora核心组件DiT,不再预测下一个token
北大和字节联手搞了个大的:
提出图像生成新范式,从预测下一个token变成预测下一级分辨率,效果超越Sora核心组件Diffusion Transformer(DiT)。
并且代码开源,短短几天已经揽下1.3k标星,登上GitHub趋势榜。

具体是个什么效果?
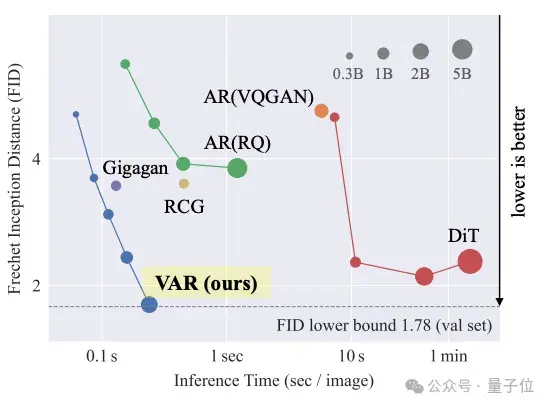
实验数据上,这个名为VAR(Visual Autoregressive Modeling)的新方法不仅图像生成质量超过DiT等传统SOTA,推理速度也提高了20+倍。
这也是自回归模型首次在图像生成领域击败DiT。
直观感受上,话不多说,直接看图:

值得一提的是,研究人员还在VAR上,观察到了大语言模型同款的Scaling Laws和零样本任务泛化。
论文代码上线,已经引发不少专业讨论。
有网友表示有被惊到,顿时觉得其他扩散架构的论文有点索然无味。

还有人认为,这是一种通向Sora的更便宜的潜在途径,计算成本可降低一个乃至多个数量级。
 预测下一级分辨率
预测下一级分辨率
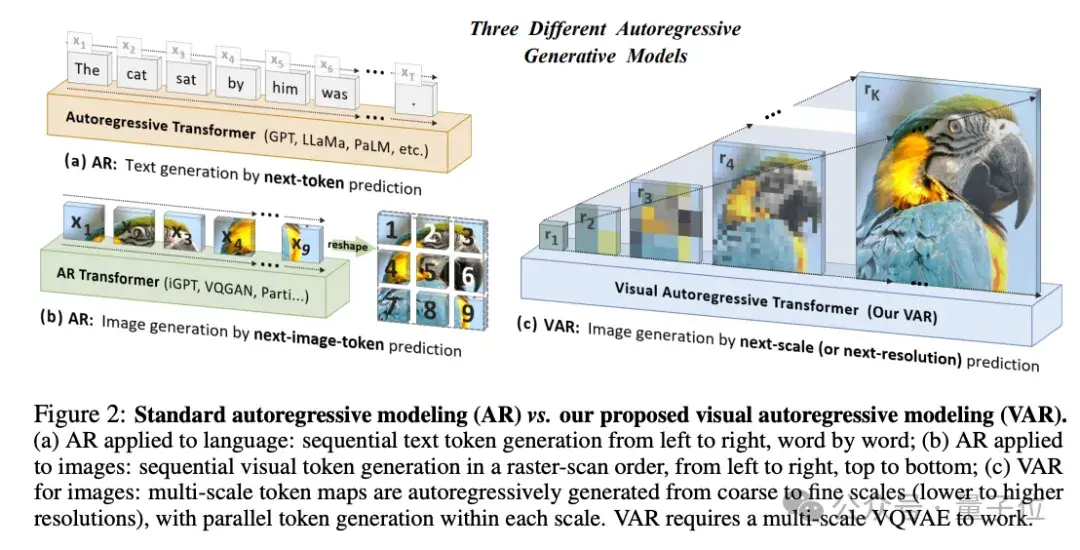
简单来说,VAR的核心创新,就是用预测下一级分辨率,替代了预测下一个token的传统自回归方法。
VAR的训练分为两个阶段。
第一阶段,VAR引入了多尺度离散表示,使用VQ-VAE将连续图像编码为一系列离散的token map,每个token map有不同的分辨率。
第二阶段,主要是对VAR Transformer的训练,通过预测更高分辨率的图像,来进一步优化模型。具体过程是这样的:
从最低分辨率(比如1×1)的token map开始,预测下一级分辨率(比如4×4)的完整token map,并以此类推,直到生成最高分辨率的token map(比如256×256)。在预测每个尺度的token map时,基于Transformer,模型会考虑之前所有步骤生成的映射信息。
在第二阶段中,之前训练好的VQ-VAE模型发挥了重要作用:为VAR提供了“参考答案”。这能帮助VAR更准确地学习和预测图像。

另外,在每个尺度内,VAR是并行地预测所有位置的token,而不是线性逐个预测,这大大提高了生成效率。
研究人员指出,采用这样的方法,VAR更符合人类视觉感知从整体到局部的特点,并能保留图像的空间局部性。
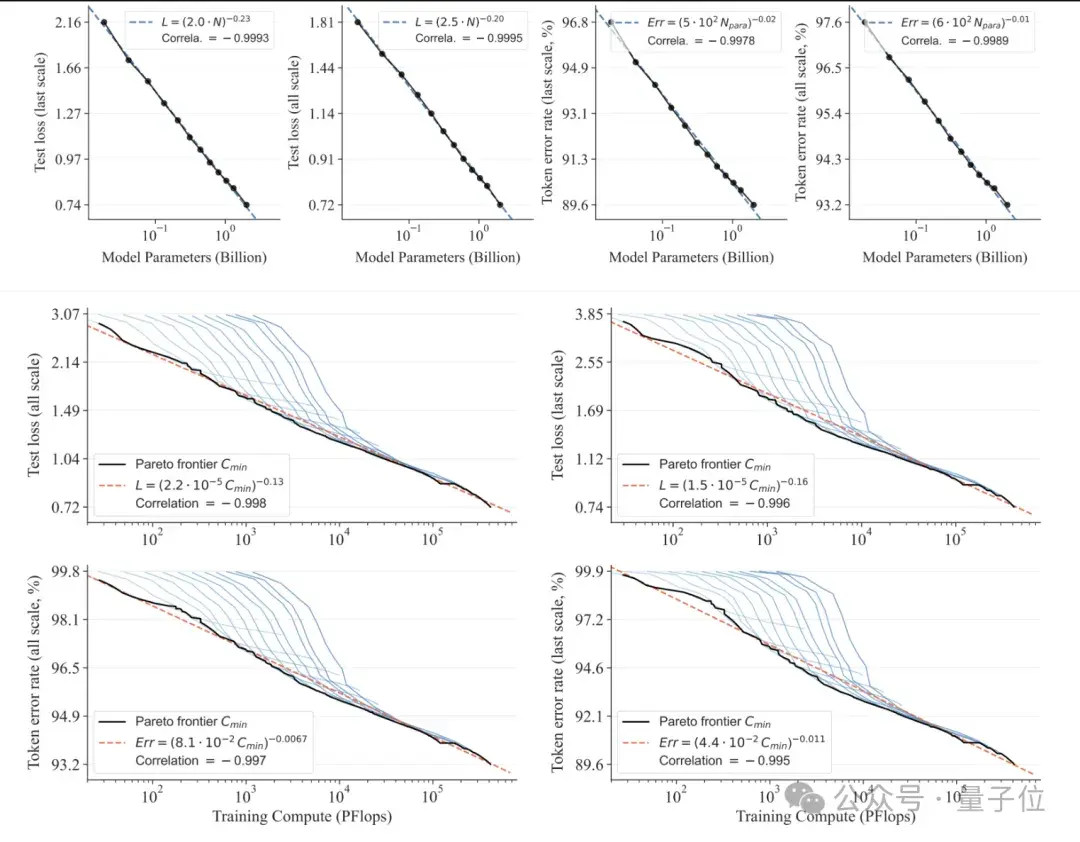
符合Scaling Laws
从实验结果来看,在图像生成质量、推理速度、数据效率和可扩展性等方面,VAR都超过了DiT。
在ImageNet 256×256上,VAR将FID从18.65降到了1.8,IS从80.4提高到356.4,显著改善了自回归模型基线。
注:FID越低,说明生成图像的质量和多样性越接近真实图像。
推理速度方面,相较于传统自回归模型,VAR实现了约20倍的效率提升。而DiT消耗的时间是VAR的45倍。
数据效率方面,VAR只需要350个训练周期(epoch),远少于DiT-XL/2的1400个。

可扩展性方面,研究人员观察到VAR有类似于大语言模型的Scaling Laws:随着模型尺寸和计算资源的增加,模型性能持续提升。
另外,在图像修补、扩展和编辑等下游任务的零样本评估中,VAR表现出了出色的泛化能力。
目前,在GitHub仓库中,推理示例、demo、模型权重和训练代码均已上线。
不过,在更多讨论之中,也有网友提出了一些问题:

VAR的作者们,来自字节跳动AI Lab和北大王立威团队。
一作田柯宇,本科毕业自北航,目前是北大CS研究生,师从北京大学信息科学技术学院教授王立威。2021年开始在字节AI Lab实习。
论文通讯作者,是字节跳动AI Lab研究员袁泽寰和王立威。
袁泽寰2017年博士毕业于南京大学,目前专注于计算机视觉和机器学习研究。王立威从事机器学习研究20余年,是首届“优青”获得者。
该项目的项目主管,是字节跳动广告生成AI研究主管Yi jiang。他硕士毕业于浙江大学,目前的研究重点是视觉基础模型、深度生成模型和大语言模型。
— 完 —
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
热门文章