

 新火种
2023-09-23
新火种
2023-09-23 


数学能力超过ChatGPT!上海交大计算大模型登开源榜首
克雷西 发自 凹非寺量子位 | 公众号 QbitAI国产数学大模型,能力已经超过了ChatGPT!最新榜单中,上海交大GAIR实验室出品的Abel专有大模型:准确率高达83.6%,在开源模型中位列第一。 据团队介绍,该模型是用挪威数学家尼尔斯·阿贝尔(Niels Abel)的名字命名的,以此向阿贝尔在代数和分析方面的开创性工作致敬。
据团队介绍,该模型是用挪威数学家尼尔斯·阿贝尔(Niels Abel)的名字命名的,以此向阿贝尔在代数和分析方面的开创性工作致敬。 在GSM8k数据集上,70B参数量的Abel碾压所有开源模型,还超过了ChatGPT。甚至在新数据集TALSCQ-EN上,Abel的表现比GPT-4还要强。
在GSM8k数据集上,70B参数量的Abel碾压所有开源模型,还超过了ChatGPT。甚至在新数据集TALSCQ-EN上,Abel的表现比GPT-4还要强。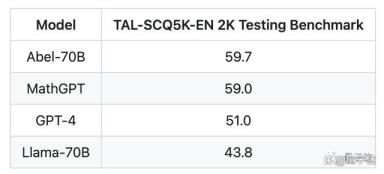 而实现这样效果的Abel,成分可以说是十分“单纯”:没有使用工具没有使用数学领域的大规模预训练数据没有使用奖励模型没有使用RLHF仅使用有监督精调(Supervised Fine-tuning,SFT)那么Abel的效果究竟怎么样呢?成绩超越开源模型SOTA这里我们选择同样是开源的Llama-2来和Abel对比。首先来看下这个鸡兔同笼问题的变体:Brown由牛和鸡一共60只,鸡的数量是牛的两倍,一共有多少条腿?
而实现这样效果的Abel,成分可以说是十分“单纯”:没有使用工具没有使用数学领域的大规模预训练数据没有使用奖励模型没有使用RLHF仅使用有监督精调(Supervised Fine-tuning,SFT)那么Abel的效果究竟怎么样呢?成绩超越开源模型SOTA这里我们选择同样是开源的Llama-2来和Abel对比。首先来看下这个鸡兔同笼问题的变体:Brown由牛和鸡一共60只,鸡的数量是牛的两倍,一共有多少条腿? 这道题Llama-2出师不利,而且不是计算错误,是逻辑上就有问题:
这道题Llama-2出师不利,而且不是计算错误,是逻辑上就有问题: Abel则成功地解决了这个问题。
Abel则成功地解决了这个问题。 再来看下一个问题:12,21,6,11和30的中位数与平均数的和是多少?
再来看下一个问题:12,21,6,11和30的中位数与平均数的和是多少? 两个模型都正确理解了所涉及的概念,但Llama还是在计算和排序上出了错。
两个模型都正确理解了所涉及的概念,但Llama还是在计算和排序上出了错。 而Abel依旧是正确地做出了这道题:
而Abel依旧是正确地做出了这道题: 再从测试数据上看看Abel的表现。首先是OpenAI提出的GSM8k数据集(大概是美国高中难度),这份榜单的前十名,Abel占了三个(不同参数规模)。开源模型当中,70B规模的Abel打败了曾经的SOTA——WizardMath。如果把商业闭源模型算进来,Abel也仅次于GPT-4、Claude-2和PaLM-2-Flan这些最著名的模型。甚至ChatGPT也不是Abel的对手。
再从测试数据上看看Abel的表现。首先是OpenAI提出的GSM8k数据集(大概是美国高中难度),这份榜单的前十名,Abel占了三个(不同参数规模)。开源模型当中,70B规模的Abel打败了曾经的SOTA——WizardMath。如果把商业闭源模型算进来,Abel也仅次于GPT-4、Claude-2和PaLM-2-Flan这些最著名的模型。甚至ChatGPT也不是Abel的对手。 △地球代表开源模型,锁代表闭源模型在难度更高的MATH(竞赛题目)数据集中,开源模型的前三名被三个规模的Abel包揽,加上闭源也仅次于Google和OpenAI的产品。
△地球代表开源模型,锁代表闭源模型在难度更高的MATH(竞赛题目)数据集中,开源模型的前三名被三个规模的Abel包揽,加上闭源也仅次于Google和OpenAI的产品。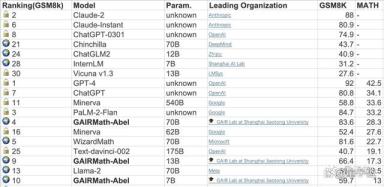 研究团队还使用了新数据集TALSCQ-EN对Abel进行测试,结果超过了GPT-4。那么,研究团队是怎么调教出这样一款高性能模型的呢?“保姆级”微调训练策略核心奥义就是高质量的训练数据。Abel使用数据是经过精心策划的,不仅包含问题的答案,还要能告诉模型找到正确答案是的方法。为此,研究团队提出了一种叫做家长监督(Parental Oversight)的“保姆级”微调训练策略。在家长监督的原则之下,团队仅通过SFT方式就完成了Abel的训练。为了评价Abel的鲁棒性,研究团队还用GPT4对GSM8k中的数字进行了修改,测试Abel是否依然能解出正确的答案。结果显示,在调整版GSM8k数据集下,70B参数的Abel鲁棒性超过了同等规模的WizardMath。
研究团队还使用了新数据集TALSCQ-EN对Abel进行测试,结果超过了GPT-4。那么,研究团队是怎么调教出这样一款高性能模型的呢?“保姆级”微调训练策略核心奥义就是高质量的训练数据。Abel使用数据是经过精心策划的,不仅包含问题的答案,还要能告诉模型找到正确答案是的方法。为此,研究团队提出了一种叫做家长监督(Parental Oversight)的“保姆级”微调训练策略。在家长监督的原则之下,团队仅通过SFT方式就完成了Abel的训练。为了评价Abel的鲁棒性,研究团队还用GPT4对GSM8k中的数字进行了修改,测试Abel是否依然能解出正确的答案。结果显示,在调整版GSM8k数据集下,70B参数的Abel鲁棒性超过了同等规模的WizardMath。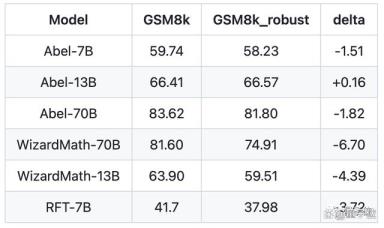 在Abel的介绍的最后,研究团队还留下了一个彩蛋:Abel的下一代,将进化成为Bernoulli(伯努利)
在Abel的介绍的最后,研究团队还留下了一个彩蛋:Abel的下一代,将进化成为Bernoulli(伯努利) 不过团队并没有对其中的含义进行说明,我们不妨期待一番。团队简介Abel由上海交通大学GAIR(生成式人工智能研究组)团队打造。该团队还曾推出过大模型高考Benchmark、AIGC事实核查工具Factool等成果。该小组负责人、清源研究院刘鹏飞副教授同时也是Abel项目的负责人。对这个数学模型感兴趣的读者,可以到GitHub页面详细了解。GitHub页面:/uploads/pic/20230923/abel
不过团队并没有对其中的含义进行说明,我们不妨期待一番。团队简介Abel由上海交通大学GAIR(生成式人工智能研究组)团队打造。该团队还曾推出过大模型高考Benchmark、AIGC事实核查工具Factool等成果。该小组负责人、清源研究院刘鹏飞副教授同时也是Abel项目的负责人。对这个数学模型感兴趣的读者,可以到GitHub页面详细了解。GitHub页面:/uploads/pic/20230923/abel
据团队介绍,该模型是用挪威数学家尼尔斯·阿贝尔(Niels Abel)的名字命名的,以此向阿贝尔在代数和分析方面的开创性工作致敬。在GSM8k数据集上,70B参数量的Abel碾压所有开源模型,还超过了ChatGPT。甚至在新数据集TALSCQ-EN上,Abel的表现比GPT-4还要强。而实现这样效果的Abel,成分可以说是十分“单纯”:没有使用工具没有使用数学领域的大规模预训练数据没有使用奖励模型没有使用RLHF仅使用有监督精调(Supervised Fine-tuning,SFT)那么Abel的效果究竟怎么样呢?成绩超越开源模型SOTA这里我们选择同样是开源的Llama-2来和Abel对比。首先来看下这个鸡兔同笼问题的变体:Brown由牛和鸡一共60只,鸡的数量是牛的两倍,一共有多少条腿?这道题Llama-2出师不利,而且不是计算错误,是逻辑上就有问题:Abel则成功地解决了这个问题。再来看下一个问题:12,21,6,11和30的中位数与平均数的和是多少?两个模型都正确理解了所涉及的概念,但Llama还是在计算和排序上出了错。而Abel依旧是正确地做出了这道题:再从测试数据上看看Abel的表现。首先是OpenAI提出的GSM8k数据集(大概是美国高中难度),这份榜单的前十名,Abel占了三个(不同参数规模)。开源模型当中,70B规模的Abel打败了曾经的SOTA——WizardMath。如果把商业闭源模型算进来,Abel也仅次于GPT-4、Claude-2和PaLM-2-Flan这些最著名的模型。甚至ChatGPT也不是Abel的对手。△地球代表开源模型,锁代表闭源模型在难度更高的MATH(竞赛题目)数据集中,开源模型的前三名被三个规模的Abel包揽,加上闭源也仅次于Google和OpenAI的产品。研究团队还使用了新数据集TALSCQ-EN对Abel进行测试,结果超过了GPT-4。那么,研究团队是怎么调教出这样一款高性能模型的呢?“保姆级”微调训练策略核心奥义就是高质量的训练数据。Abel使用数据是经过精心策划的,不仅包含问题的答案,还要能告诉模型找到正确答案是的方法。为此,研究团队提出了一种叫做家长监督(Parental Oversight)的“保姆级”微调训练策略。在家长监督的原则之下,团队仅通过SFT方式就完成了Abel的训练。为了评价Abel的鲁棒性,研究团队还用GPT4对GSM8k中的数字进行了修改,测试Abel是否依然能解出正确的答案。结果显示,在调整版GSM8k数据集下,70B参数的Abel鲁棒性超过了同等规模的WizardMath。在Abel的介绍的最后,研究团队还留下了一个彩蛋:Abel的下一代,将进化成为Bernoulli(伯努利)不过团队并没有对其中的含义进行说明,我们不妨期待一番。团队简介Abel由上海交通大学GAIR(生成式人工智能研究组)团队打造。该团队还曾推出过大模型高考Benchmark、AIGC事实核查工具Factool等成果。该小组负责人、清源研究院刘鹏飞副教授同时也是Abel项目的负责人。对这个数学模型感兴趣的读者,可以到GitHub页面详细了解。GitHub页面:/uploads/pic/20230923/abel 相关推荐



- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。










