

 新火种
2024-03-08
新火种
2024-03-08 


如何缩小中美通用大模型差距?我在两会看到了答案
又是一年两会进行时,AI大模型受到前所未有的关注。
彼时在大洋彼岸的另一边,GPT-4正被最新大模型全面超越,Sora新视频持续惊艳网友。

一时间,关于国产通用大模型未来发展、中美之间差距还有多少的话题再次引人注目。
既如此且先来看看,两会都聊了啥?或许能从中找到答案。
人工智能火爆两会
与开展“人工智能+”行动相呼应的是,20多位全国人大代表或政协委员都谈到了大模型相关,覆盖到从底层数据算力、模型层以及应用层的方方面面,为当前正面临的挑战建言献策。
通用大模型又成为这其中的关键词。这样的盛况,以往并不多见。

在具体建议中,可以看到大概有三个方面:技术瓶颈、未来发展以及应用落地。
技术瓶颈:数据、算力和产业生态
当前国产大模型技术瓶颈还有哪些?包括科大讯飞董事长刘庆峰、知乎创始人周源、京东集团技术委员会主席曹鹏、中科院计算机所研究员张云泉等在内都发表了自己的看法。
知乎创始人周源谈到了数据方面的挑战,他认为对大模型数据采集进行监督和审查。
京东集团技术委员会主席曹鹏、中科院计算机所研究员张云泉等在内都谈到了突破算力瓶颈,曹鹏鼓励国产算力软硬协同,张云泉提出了集中AI芯片研制、设立智能算力发展专项组等几个方向的建议。
而科大讯飞董事长刘庆峰则从算力、底座平台、源头技术研发等维度介绍了我国发展大模型存在的短板,并建议制定国家《通用人工智能发展规划》,来缩小中美通用人工智能产业的差距,打造我国的比较优势。
未来发展:教育人才和政策法规也成关注焦点
技术之外,教育、人才建设、政策法规等方面也成为了代表们的关注焦点。
小米创始人雷军提出了三项人才相关的建议:从义务教育阶段普及人工智能素养教育;大力推进高校人工智能相关专业的建设;支持大型科技企业和教培机构培育人工智能应用型人才。
还有一些法律界人士,比如金杜律师事务所高级合伙人张毅,提出推进《人工智能法》的出台。
应用落地:如何赋能千行百业?
值得一提的是,此次还有来自影视、体育、农村、养老、制造、文旅等各行业代表也都参与到对于人工智能发展的讨论之中。
比如Sora对影视行业的影响,演员靳东在接受采访时谈到一些服务型的岗位可能会被替代,但短时间内,人工智能很难替代影视等创作行业。
还有像美的副总裁钟铮、拈花湾文旅董事长吴国平、天能控股集团董事长张天任提到了人工智能在制造业、文旅、养老等行业的应用。
……
可以看到的是,大模型毫无疑问地成为此次两会的焦点。在二十多位人大代表或政协委员的提案中,其实也能总结出当前国产大模型的发展缩影:技术挑战仍在,人才政策得跟上,应用发展要加速。
中美差距还有多大?
ChatGPT的出现,国内掀起千模大战,部分玩家的大模型在一年时间实现了对标GPT-3.5的实力,部分能力超过了GPT-4。
而Sora横空出世,仅需通过文本即可自动生成1分钟视频,给视频生成领域带来了颠覆,其展现的性能对同类产品实现了碾压……
于是乎,关于中美之间的差距是否进一步加大再次引发热议。数据、算力、人才培养和投入成为这当中讨论的焦点。
但中美差距具体还有多大?始终没有什么定论。
此次两会上,科大讯飞董事长刘庆峰首次给出了定量描述——
1-2年,追平。

为什么会是这个数字?刘庆峰做了进一步解答。
他认为中美博弈的“主战场”就是在通用底座能力上持续进行对标。而Sora正是基于GPT-4/4V的通用大模型底座能力所延伸出来的特定领域的成功实践。
同样延伸的还有像DALL-E3、Whisper。
他还以讯飞星火大模型为例,预计6个月内可达到GPT4/4V当前最好水平。但随着GPT-5的发布,“这个差距可能会被拉到一年以上”。
因此他也强调称,这也会是一个你追我赶的动态过程。
在刘庆峰这一推论中,在人工智能领域,将通用大模型推至到一个高点,成为中美之间差距的核心竞争点。
也有代表此次在两会上也表达了类似的观点:通用大模型的发展,已不是单纯的科技之争,更是国运之争,影响深远。
过去一年可以看到,通用大模型已然成为业内玩家的发展共识。
在模型层,关于长文本处理、多模态、逻辑推理、数学编码等技术突破,以全方位提升通用大模型的理解能力。基础设施层,自主可控算力生态也构建开来,国产算力软硬协同来支撑大模型创新和应用。
当然最明显感知的发展变化,还是应用层的全面开花。
来自医疗、教育、广告营销、制造等各个行业领域的传统玩家,基于通用大模型底座平台以及行业数据,得以让大模型在自身领域加速应用。
千模大战之中,绝大多数也都是行业和垂直领域大模型。而如果没有通用底座大模型的支撑,行业大模型的成效将无法持续进步。
因此,中国必须要有自主可控、对标国际一流水准的通用底座大模型。
这当中最具代表的践行者就是科大讯飞。
过去一年,他们有两个进展值得关注——
一个是中国首个支持万亿浮点参数的国产化算力平台“飞星一号”,联合华为实现国产算力的自主可控。
另一个基于该平台发布讯飞星火V3.5,整体效果逼近GPT-4 Turbo,并初步形成大模型产业生态。
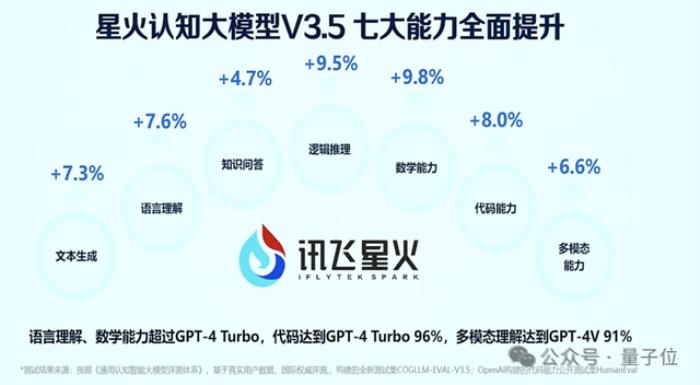
基于算力和持续升级迭代的通用大模型,他们在医疗、教育、工业等场景中有了深度应用,已率先构建出行业领先的大模型产业生态——
截至今年1月,讯飞星火纯用户2400万,基于讯飞听见、讯飞星火APP、讯飞输入法等应用,星火已累计赋能亿万用户。大模型开发者生态积累37万开发者数量,其中企业开发者数量为24万……并从中以此形数据闭环,自驱动大模型的迭代和落地。
过去的发展成绩表明:以科大讯飞为代表的通用人工智能国家队在推动大模型的落地,我们有基础,也有自身的场景和数据优势。但同样也要客观看到差距、正视差距,缩小中美底座大模型的差距。
全球竞争更加激烈,通用底座呼之欲出
2024年刚开年,以天为单位的AI新进展再次让全球无眠。
颠覆视频生成的Sora、全面超越GPT-4的Claude 3、还有Stable Diffusion 3的发布,而在产业链上,英伟达正式突破2万亿美元震惊股市……
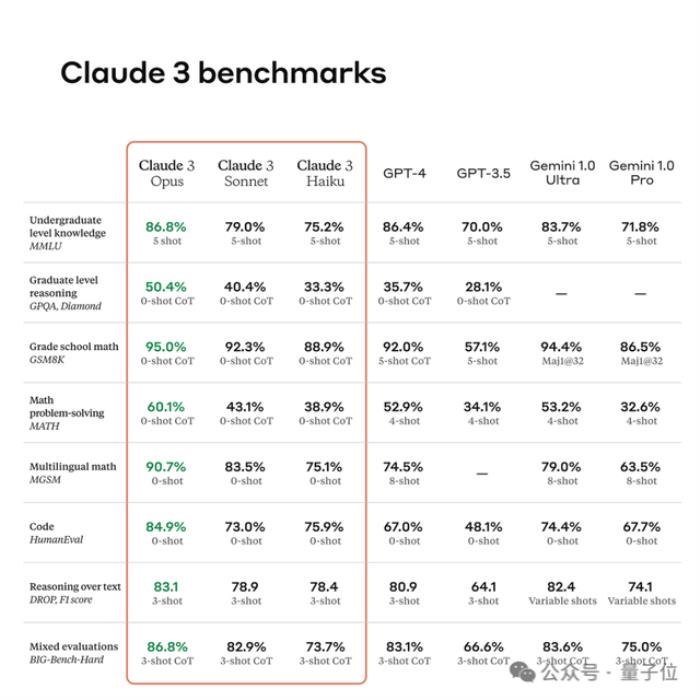
显然,全球竞速没有放缓,反而更紧迫了。
但同去年ChatGPT刚出现时百模大战千模大战的各家探索不同,今年国内却显得冷静许多。因为有关技术趋势的共识已经再明显不过:
多模态融合,包括语音、图像、视频等多个模态融合已成为国内外科技大厂大模型升级和迭代重点;Scaling Law反复被验证,大模型的不同流派走向统一;软硬件一体,产业链上下游共建的通用底座,更加呼之欲出。也只有通用底座,才是综合实力、长治久安、基业长青、支撑千行百业“AI+”的基石。
有意思的是,这样的洞察,也在两会上也被提及出来了。
刘庆峰给出了全面系统的建议。
他建议在2017年《新一代人工智能发展规划》的基础上,系统性制定国家《通用人工智能发展规划》,以顶层设计来推动通用人工智能的发展。
与此同时,相关工作也要同步展开,为此刘庆峰给出了九点建议。
首先第一点,聚焦通用大模型“主战场”,整合各方资源,持续加大投入。
比如包括以专项的形式在未来5年持续支持研发攻关、支持算力基础设施建设、推动工业和民生等领域的大模型应用等。
随后,就是加强源头技术布局,围绕通用人工智能相关领域,布局战略性、前瞻性基础研究,坚持以源头核心技术突破来推动颠覆式创新的探索。
除了大模型技术外,还要加快脑科学与类脑智能、量子计算以及推动AI for Science的发展。
更为具体的建议还有:
建议加快形成以国产大模型为核心的自主可控产业生态。
建议推动国家级高质量训练数据开放和共享,支持国家战略科技力量以揭榜挂帅形式优先、低成本使用。
建议出台更加客观、公正、可信的评测方法,推动大模型在行业领域应用的健康发展。
除此之外,他还强调了人才培养、法律法规以及伦理人文研究方面的重要性。
尤其是人才培养,他不仅强调了顶尖的创新人才、应用型人才的培养,而且建议加快推广人工智能通识教育,赋能基础教育、职业教育和高等教育全学段,并且建议设立国家人工智能学院。
对于未来可能会被人工智能大量替代的行业和岗位,他认为应该研究新型人才能力素质模型和培养方案。
这样的洞察和建议,之所以系统和全面,一方面是讯飞本身是人工智能国家队,懂行。另一方面,常年的人工智能产业深耕,也让它对产业需求有更深的洞察。

透过此次两会上各位行业代表们的观点,可以看到社会的共识是:
通用大模型是必经之路。
从全球发展来看,实现算力、产业生态的自主可控,才能保证大模型的持续迭代和应用,在全球竞争态势下才能占据一席之地,拥有话语权。
民生社会层面,以大模型为代表的新质生产力,正成为支撑社会发展的新型基础设施。从技术研发到商业落地,这条发展路线上一以贯之的最终目标,都是为各行各业提质提效。
所以即便现在差距仍不可忽视,但包括国产大模型的核心玩家,已经初步探索出了一条自主可控之路,赋能到各行业,这也是大模型的真正价值所在。
从“互联网+”到“人工智能+”,新质生产力机遇,未来可期,中国可期。
相关推荐



- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。










