

 新火种
2024-03-01
新火种
2024-03-01 


打入AI底层!NUS尤洋团队用扩散模型构建神经网络参数,LeCun点赞
扩散模型,迎来了一项重大新应用——
像Sora生成视频一样,给神经网络生成参数,直接打入了AI的底层!
这就是新加坡国立大学尤洋教授团队联合UCB、Meta AI实验室等机构最新开源的研究成果。

具体来说,研究团队提出了一种用于生成神经网络参数的扩散模型p(arameter)-diff。
用它来生成网络参数,速度比直接训练最多提高44倍,而且表现毫不逊色。
这一模型一经发布,就迅速在AI社区引发强烈讨论,圈内人士对此的惊叹,毫不亚于普通人看到Sora时的反应。
甚至有人直接惊呼,这基本上相当于AI在创造新的AI了。

就连AI巨头LeCun看了之后,也点赞了这一成果,表示这真的是个cute idea。
而实质上,p-diff也确实具有和Sora一样重大的意义,对此同实验室的Fuzhao Xue(薛复昭)博士进行了详细解释:

言归正传,p-diff到底是如何生成神经网络参数的呢?
将自编码器与扩散模型结合
要弄清这个问题,首先要了解一下扩散模型和神经网络各自的工作特点。
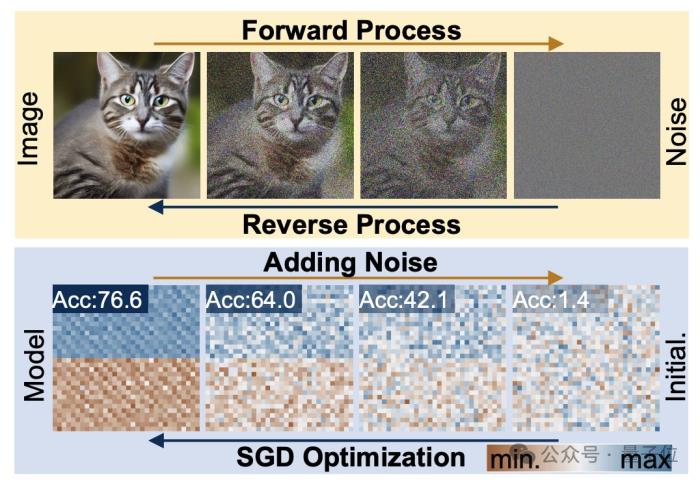
扩散生成过程,是从随机分布到高度特定分布的转变,通过复合噪声添加,将视觉信息降级为简单噪声分布。
而神经网络训练,同样遵循这样的转变过程,也同样可以通过添加噪声的方式来降级,研究人员正是在这一特点的启发之下提出p-diff方法的。
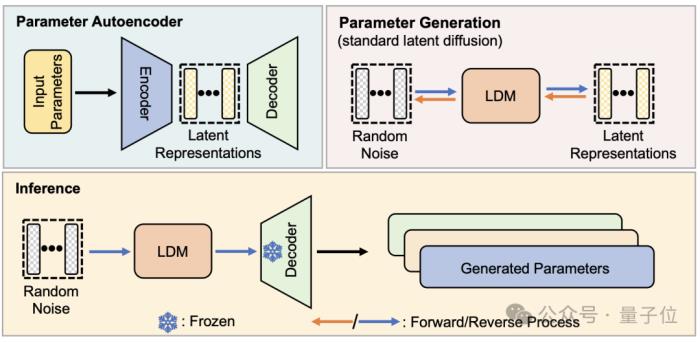
从结构上看,p-diff是研究团队在标准潜扩散模型的基础之上,结合自编码器设计的。
研究者首先从训练完成、表现较好的网络参数中选取一部分,并展开为一维向量形式。
然后用自编码器从一维向量中提取潜在表示,作为扩散模型的训练数据,这样做可以捕捉到原有参数的关键特征。
训练过程中,研究人员让p-diff通过正向和反向过程来学习参数的分布,完成后,扩散模型像生成视觉信息的过程一样,从随机噪声中合成这些潜在表示。
最后,新生成的潜在表示再被与编码器对应的解码器还原成网络参数,并用于构建新模型。
下图是通过p-diff、使用3个随机种子从头开始训练的ResNet-18模型的参数分布,展示了不同层之间以及同一层不同参数之间的分布模式。

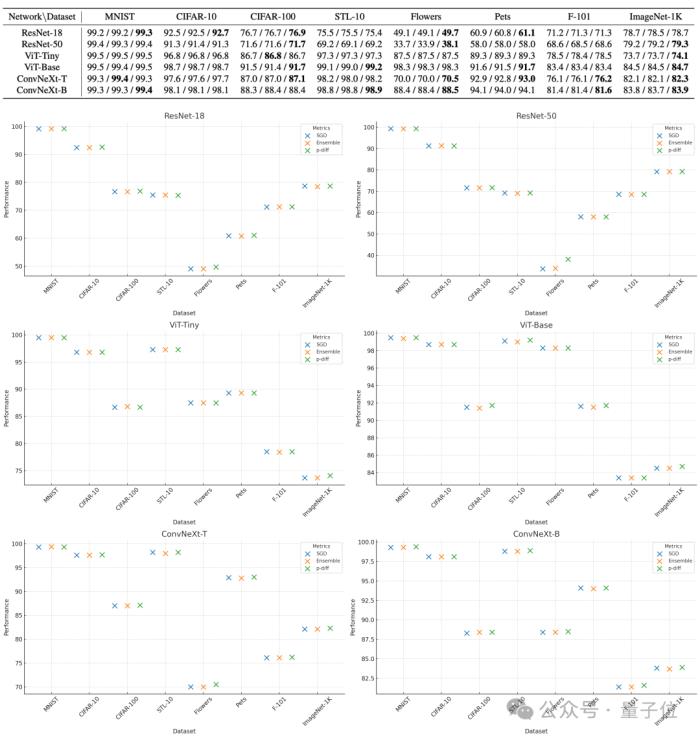
为了评估p-diff所生成参数的质量,研究人员利用3种类型、每种两个规模的神经网络,在8个数据集上对其进行了测试。
下表中,每组的三个数字依次表示原始模型、集成模型和用p-diff生成的模型的测评成绩。
结果可以看到,用p-diff生成的模型表现基本都接近甚至超过了人工训练的原始模型。
效率上,在不损失准确度的情况下,p-diff生成ResNet-18网络的速度是传统训练的15倍,生成Vit-Base的速度更是达到了44倍。
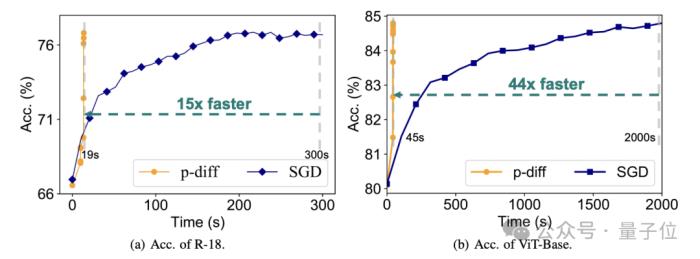
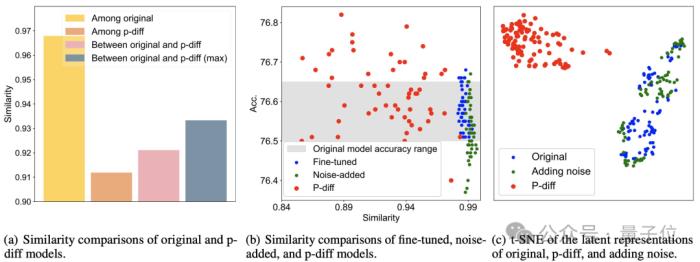
额外的测试结果证明,p-diff生成的模型与训练数据有显著差异。
从下图(a)可以看到,p-diff生成的模型之间的相似度低于各原始模型之间的相似度,以及p-diff与原始模型的相似度。
而从(b)和(c)中可知,与微调、噪声添加方式相比,p-diff的相似度同样更低。
这些结果说明,p-diff是真正生成了新的模型,而非仅仅记忆训练样本,同时也表明其具有良好的泛化能力,能够生成与训练数据不同的新模型。
目前,p-diff的代码已经开源,感兴趣的话可以到GitHub中查看。
相关推荐



- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。










