

 新火种
2023-12-21
新火种
2023-12-21 


论文遭首届ICLR拒稿、代码被过度优化,word2vec作者TomasMikolov分享背后的故事
除了表达自己获得 NeurIPS 2023 时间检验奖的感想之外,Tomas Mikolo 还对 NLP 和 ChatGPT 的现状给出了自己的一些思考。
几天前,NeurIPS 2023 公布了获奖论文,其中时间检验奖颁给了十年前的 NeurIPS 论文「Distributed Representations of Words and Phrases and their Compositionality」。这项工作引入了开创性的词嵌入技术 word2vec,展示了从大量非结构化文本中学习的能力,推动了自然语言处理新时代的到来。这篇论文由当时都还在谷歌的 Tomas Mikolov、Ilya Sutskever、Kai Chen、Greg Corrado、Jeffrey Dean 等人撰写,被引量超过 4 万次。

 图源:facebook
图源:facebook
以下为原贴内容,我们做了不改变原意的整理。我非常高兴 word2vec 论文获得了 NeurIPS 2023 时间检验奖,这是我获得的第一个最佳论文类型的奖项。实际上,word2vec 原始论文在 2013 年首届 ICLR 会议被拒绝接收了(尽管接收率很高),这让我想到审稿人预测论文的未来影响是多么困难。这些年,我听到了很多关于 word2vec 的评论,正面的还有负面的,但至今没有在网络上认真地发表过评论。我觉得研究界正在不断地被一些研究人员的 PR 式宣传淹没,他们通过这样的方式获得他人的论文引用和注意力。我不想成为其中的一部分,但 10 年后,分享一些关于论文背后的故事可能会很有趣。我经常听到的一个评论是,代码很难理解,以至于有些人认为是我故意地让代码不可读。但我没有那么邪恶,代码最终被过度优化了,因为我等了好几个月才被批准发布它。我也试图让代码更快更短。回想起来,如果当时团队中没有 Greg Corrado 和 Jeff Dean,我怀疑自己是否会获得批准。我认为 word2vec 可能是谷歌开源的第一个广为人知的 AI 项目。
在 word2vec 发布一年多后,斯坦福 NLP 小组的 GloVe 项目也引发了很大争议。虽然该项目从我们的项目中复刻了很多技巧,但总感觉 GloVe 倒倒退了一步:速度较慢,还需要更多内存,生成的向量质量比 word2vec 低。然而,GloVe 是基于在更多数据上预训练的词向量发布的,因而很受欢迎。之后,我们在 fastText 项目中修复了相关问题,在使用相同数据进行训练时,word2vec 比 GloVe 好得多。尽管 word2vec 是我被引用最多的论文,但我从未认为它是我最有影响力的项目。实际上,word2vec 代码最初只是我之前项目 RNNLM 的一个子集,我感觉 RNNLM 很快就被人们遗忘了。
但在我看来,它应该和 AlexNet 一样具有革命性意义。在这里,我列举一些在 2010 年 RNNLM 中首次展示的想法:递归神经网络的可扩展训练、首次通过神经语言模型生成文本、动态评估、字符和子词级别的神经语言建模、神经语言模型自适应(现在称为微调)、首个公开可用的 LM 基准。我发布了第一项研究,显示当一切正确完成时,训练数据越多,神经网络就能比 n-gram 语言模型更胜一筹。这在今天听起来是显而易见的,但在当时这被广泛认为是不可能的,甚至大多数谷歌员工都认为,数据越多,除了 n-gram 和平滑技术外,其他任何工作都是徒劳的。我很幸运能在 2012 年加入谷歌 Brain 团队,那里有很多大规模神经网络的「信徒」,他们允许我参与 word2vec 项目,展示了它的潜力。但我不想给人留下到这里就足够完美的印象。
在 word2vec 之后,作为后续项目,我希望通过改进谷歌翻译来普及神经语言模型。我确实与 Franz Och 和他的团队开始了合作,在此期间我提出了几种模型,这些模型可以补充基于短语的机器翻译,甚至可以取代它。其实在加入谷歌之前,我就提出了一个非常简单的想法,通过在句子对(比如法语 - 英语)上训练神经语言模型来实现端到端的翻译,然后在看到第一句话后使用生成模式生成翻译。这对短句子效果很好,但在长句子上就不那么奏效了。我在谷歌 Brain 内部多次讨论过这个项目,主要是与 Quoc 和 Ilya,在我转到 Facebook AI 后他们接手了这个项目。我感到非常意外的是,他们最终以「从序列到序列(sequence to sequence)」为名发表了我的想法,不仅没有提到我是共同作者,而且在长长的致谢部分提及了谷歌 Brain 中几乎所有的人,唯独没有我。那时是资金大量涌入人工智能领域的时期,每一个想法都价值连城。看到深度学习社区迅速变成某种权力的游戏,我感到很悲哀。
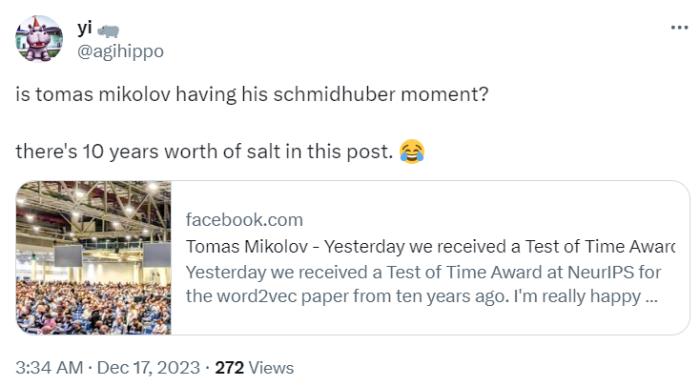
总之,多年来人们对语言模型的兴趣增长缓慢,但自从 ChatGPT 发布以来,人们对它的兴趣呈爆炸式增长,看到这么多人终于将人工智能和语言联系在一起,真的很酷。我们还没有到达那个阶段,我个人认为我们需要有新的发现来突破神经模型的泛化极限。我们无疑生活在一个激动人心的时代。但是,让我们不要过分信任那些想要垄断基于数十位甚至数百位科学家辛勤工作的技术,同时声称这一切都是为了人类的利益的人。不过,Tomas Mikolov 的发言也让人感叹,他也要步 LSTM 之父 Jürgen Schmidhuber 的后尘吗?
 图源:twitter
图源:twitter
相关推荐



- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。










