

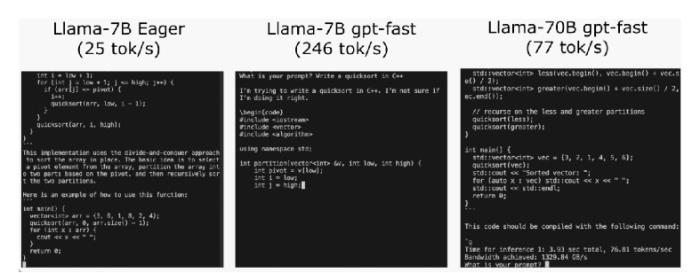
通过这些代码,PyTorch团队让Llama7B提速10倍
要点:PyTorch团队通过优化技术,在不到1000行的纯原生PyTorch代码中将Llama7B的推理速度提升了10倍,达到了244.7tok/s。优化方法包括使用PyTorch2.0的torch.compile函数、GPU量化、Speculative Decoding(猜测解码)、张量并行等手段
要点:PyTorch团队通过优化技术,在不到1000行的纯原生PyTorch代码中将Llama7B的推理速度提升了10倍,达到了244.7tok/s。优化方法包括使用PyTorch2.0的torch.compile函数、GPU量化、Speculative Decoding(猜测解码)、张量并行等手段

PyTorch 2.0正式发布。PyTorch 2.0正式版终于来了!去年12月,PyTorch基金会在PyTorch Conference 2022上发布了PyTorch 2.0的第一个预览版本。跟先前1.0版本相比,2.0有了颠覆式的变化。
作者|Eric,编辑|伊凡谁在喂养“AI巨兽”?3月19日,OpenAI在其开发人员API上推出了o1-pro——o1推理AI模型更强大的版本。所向披靡的Open AI,正在“创飞”一部分创业公司,只要Open AI想做某个业务,就会有一批初创公司宣告倒闭。
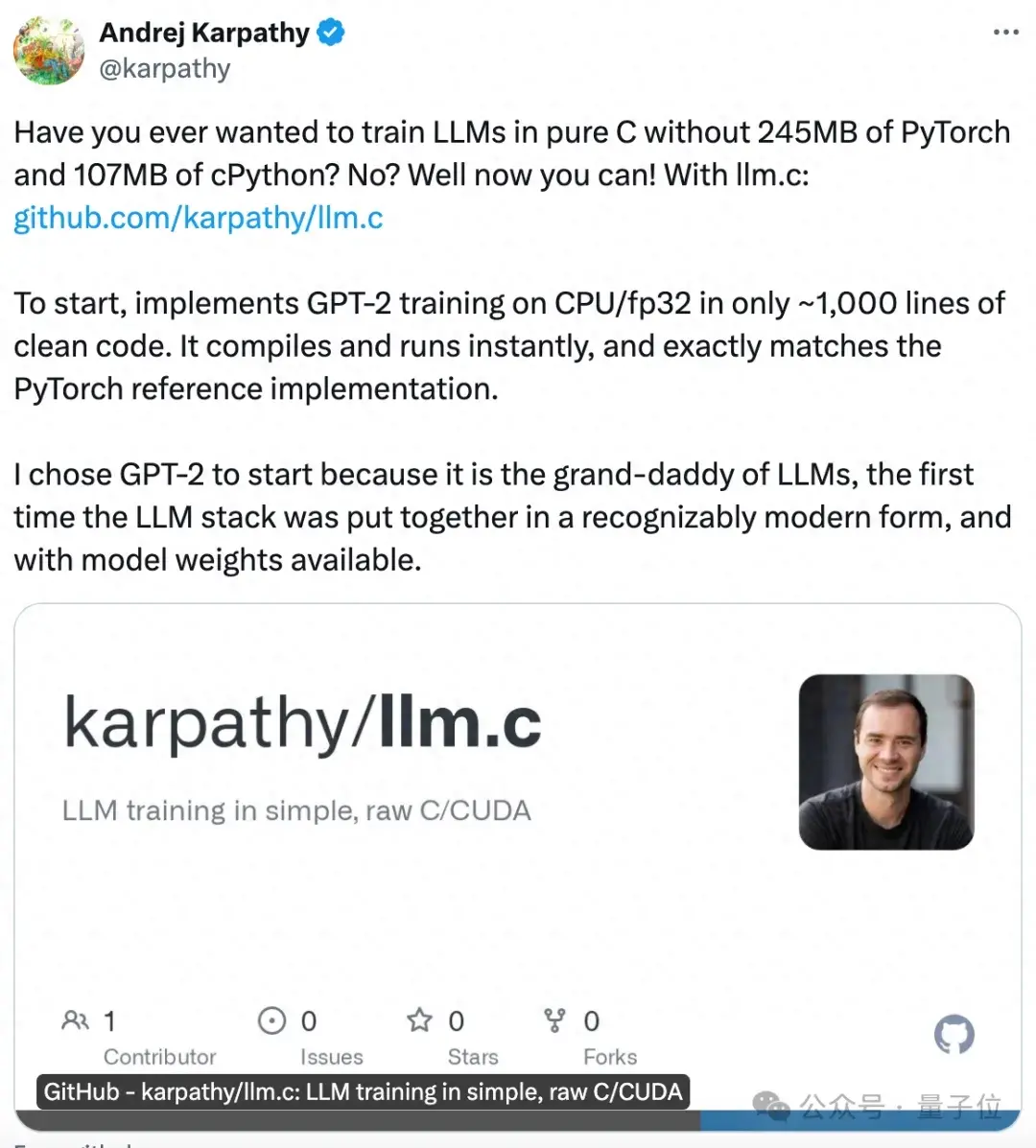
大神卡帕西(Andrej Karpathy)刚“复工”,立马带来神作:纯C语言训练GPT,1000行代码搞定!,不用现成的深度学习框架,纯手搓。发布仅几个小时,已经揽星2.3k。

机器之心报道编辑:大盘鸡、娄佳琪离 AI 智能体越来越近。如果 OpenAI 的开发者大会是砸向水面的石头,当它结束后,阵阵涟漪正向四面散开。GPT 不仅在集成上更进一步,不必一步步调用,更将成为人人可开发的强大工具。即使你不懂编码、没有计算机相关的基础知识,也能轻松构建。官方博客:https://
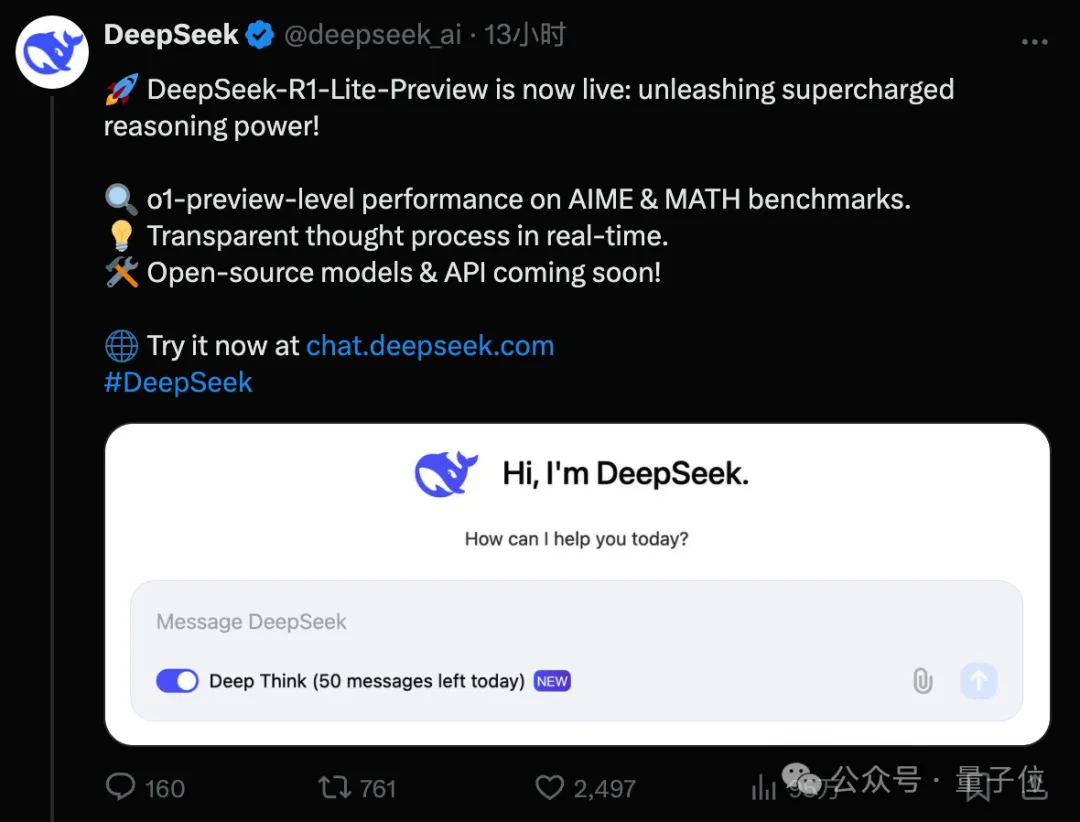
DeepSeek版o1来了,发布即上线,现在就能玩!模型名为DeepSeek-R1-Lite,预览版在难度较高数学和代码任务上超越o1-preview,大幅领先GPT-4o等。据了解,DeepSeek-R1-Lite使用强化学习训练,推理含大量反思和验证,遵循新的Scaling Laws——推理越长

GPT-4再次遭网友“群攻”,原因是“懒”得离谱!有网友想在Android系统开发一个能够与OpenAI API实时交互的应用。于是把方法示例链接发给GPT-4,让它用Kotlin语言编写代码:没成想,和GPT-4一来二去沟通半天,GPT-4死活给不出一个能正常运行的完整代码。

证券时报e公司讯,10月26日,腾讯宣布腾讯混元大模型迎来全新升级,并正式对外开放“文生图”功能,升级后的腾讯混元中文能力整体超过GPT3.5,代码能力大幅提升20%,达到业界领先水平。腾讯内部开始使用混元大模型写代码。目前,超过180个腾讯内部业务已接入腾讯混元,包括腾讯会议等。已有来自零售、教育
羊驼家族的“最强开源代码模型”,迎来了它的“超大杯”——就在今天凌晨,Meta宣布推出Code Llama的70B版本。在HumanEval测试中,Code Llama-70B的表现在开源代码模型中位列第一,甚至超越了GPT-4。

本文带你全面洞悉用LLM写代码的各式方法。随着 BERT 和 GPT 等预训练 Transformer 的出现,语言建模近些年来取得了显著进步。随着大型语言模型(LLM)的规模扩展至数以千万计的参数数量,LLM 开始展现出通用人工智能的迹象,它们的应用也已经不局限于文本处理。










