

 新火种
2023-12-21
新火种
2023-12-21 


有效提高视频编辑一致性,美图&国科大提出基于文生图模型新方法EI²
美图影像研究院(MT Lab)与中国科学院大学突破性地提出了基于文生图模型的视频生成新方法EI2,用于提高视频编辑过程中的语义和内容两方面的一致性。该论文从理论角度分析和论证视频编辑过程中出现的不一致的问题,主要由引入的时序信息学习模块使特征空间出现协变量偏移造成,并针对性地设计了新的网络模块进行解决以生成高质量的编辑结果。目前,该论文已被机器学习顶会之一 NeurIPS 2023 接收。背景作为当前炙手可热的前沿技术之一,生成式 AI 被广泛应用于各类视觉合成任务,尤其是在图像生成和编辑领域获得了令人赞叹的生成效果。
对比静态图像,视频拥有更丰富的动态变化和语义信息,而现有的视觉生成任务主要基于变分自编码器(VAE)和生成对抗网络(GAN),但通常会受限于特定场景和数据,很难提供普适的解决方案。因此,近年来基于扩散模型(Diffusion Models)在分布式学习上表现出的卓越能力,扩散模型也开始被拓展到视频领域,并在视频生成与编辑领域展现出了巨大的潜力。在研究初期,基于扩散模型的视频生成和编辑任务利用文本 - 视频数据集直接训练文生视频模型以达到目标。然而,由于缺少高质量的视频数据,这类工作泛化能力通常较差,此外,它们也需要耗费大量的计算资源。为避免上述问题,近期工作更倾向于将基于大规模数据集上预训练的文生图模型拓展到视频领域。此类任务通过引入可学习的时序模块使文生图模型具备视频生成和编辑能力,从而减少对视频数据的需求以及计算量,并提供了简单易用的方案。因此,这类任务在近期引起了广泛的关注。
然而,以上基于文生图模型的视频生成方案也面临着两个关键问题:一是时序不一致问题,即生成视频帧间内容的不一致,例如闪烁和主体变化等;二是语义不一致问题,即生成视频未能按照给定文本进行修改。解决上述两个核心问题将极大地推动基于文本的视频编辑与生成技术在实际场景中的应用和落地。美图影像研究院(MT Lab)与中国科学院大学在 NeurIPS 2023 上共同提出一种基于文生图模型的视频编辑方法 EI2, 从理论上分析和论证了现有方案出现不一致的原因,并提出了有效的解决方案。


图 1 本文提出的 EI2 方案与已有方案在视频编辑任务上的结果对比基于上述分析,EI2 设计了更为合理的时序模块并将其与文生图模型相结合,用于增强生成能力,以更好地解决视频编辑任务。具体而言,EI2 采用一次微调框架(One-shot Tuning),从理论和实践两方面对现有方法进行了改进。首先,EI2 设计了偏移控制时序注意力模块,用于解决视频编辑过程中出现的语义不一致问题。EI2 从理论上证明了在特定假设下,协变量偏移与微调无关,是由时序注意力机制新引入的参数造成,这为解决语义不一致问题提供了有价值的指导。通过上述论证,EI2 定位层归一化(Layer Norm)模块是协变量偏移出现的重要原因。为了解决这一问题,EI2 提出了简单有效的实例中心化模块以控制分布偏移。此外,EI2 也对原时序注意力模块中的权值进行归一化,从而限制方差的偏移。
其次,EI2 设计了粗细力度帧间注意力模块来缓解视频编辑过程中出现的时序不一致问题。EI2 创新性地提出了一种粗细力度交互机制,用于更为有效地建立时空注意力机制,从而使得低成本的视频全局信息交互成为可能。与现有丢弃空间信息的方案相比,EI2 在空间维度上进行采样,这不仅保持了时空数据的整体结构,也减少了需要考虑的数据规模。具体而言,粗细力度帧间注意力模块对于当前帧保留细粒度信息,而对于其他帧则进行下采样以获得粗粒度信息来做交互。这种方式使得EI2 在有效学习时序信息的同时,保证了与现有时空交互方案接近的计算量。基于以上设计,实验结果表明 EI2 可以有效地解决视频编辑过程中出现的语义不一致问题并保证时序上的一致性,取得了超越现有方案的视频编辑效果。
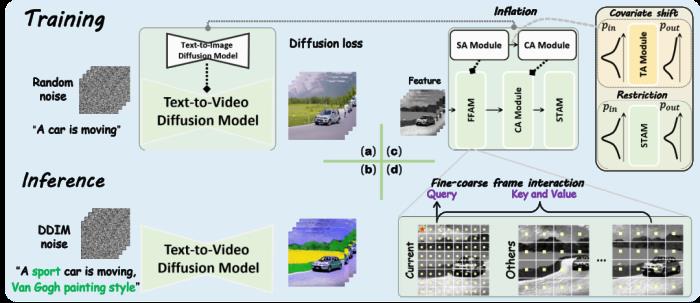


 图 4 协变量偏移控制的消融实验
图 4 协变量偏移控制的消融实验
图 5 时空注意力机制的消融实验总结该论文创新性地提出了基于文生图模型的视频编辑新方案EI2,有效地解决了现有方案遇到的语义和时序不一致问题。其中,EI2 从理论上证明了语义不一致问题由引入的时序模块产生的协变量偏移造成,并设计了偏移控制时序注意力进行改进。另外,EI2 提出了粗细力度帧间注意力模块,在提升视频编辑效果的同时也保证了较低的计算复杂度。与现有方案相比,EI2 在量化和可视化的分析中都表现出了明显的优势。研究团队本论文由美图影像研究院(MT Lab)和中国科学院大学的研究者们共同提出。美图影像研究院成立于 2010 年,致力于计算机视觉、深度学习、计算机图形学等人工智能(AI)相关领域的研发。
曾先后参与 CVPR、ICCV、ECCV 等计算机视觉国际顶级会议,并斩获 ISIC Challenge 2018 皮肤癌病灶分割赛道冠军,ECCV 2018 图像增强技术比赛冠军,CVPR-NTIRE2019 图像增强比赛冠军,ICCV2019 服饰关键点估计比赛冠军等十余项冠亚军,在 AAAI、CVPR、ICCV、ECCV、NIPS 等国际顶级会议及期刊上累计发表 48 篇学术论文。在美图影像研究院(MT Lab)的支持下,美图公司拥有丰富的 AIGC 场景落地经验。2010 年开始人工智能领域的相关探索,2013 年开始布局深度学习,2016 年推出 AIGC 雏形产品 “手绘自拍”,2022 年 AIGC 产品全面进入爆发期,2023年6月发布自研AI视觉大模型MiracleVision(奇想智能),2023年12月MiracleVision迭代至4.0 版本,主打AI设计与AI视频。
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。









