

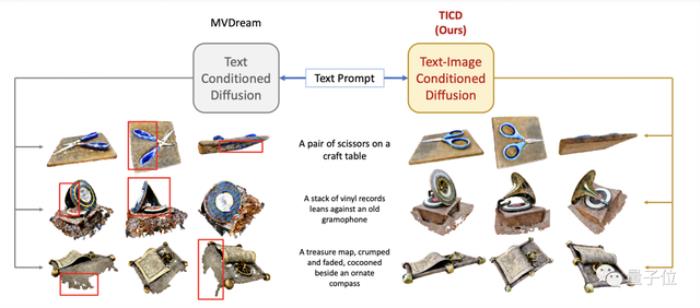
用扩散模型监督NeRF,清华文生3D新方法成新SOTA
近日,清华大学刘永进教授课题组提出了一种基于扩散模型的文生3D新方式。无论是不同视角间的一致性,还是与提示词的匹配度,都比此前大幅提升。文生3D是3D AIGC的热点研究内容,得到了学术界和工业界的广泛关注。
近日,清华大学刘永进教授课题组提出了一种基于扩散模型的文生3D新方式。无论是不同视角间的一致性,还是与提示词的匹配度,都比此前大幅提升。文生3D是3D AIGC的热点研究内容,得到了学术界和工业界的广泛关注。

OpenAI研究如何破解GPT-4思维,公开超级对齐团队工作,Ilya Sutskever也在作者名单之列。该研究提出了改进大规模训练稀疏自编码器的方法,并成功将GPT-4的内部表征解构为1600万个可理解的特征。由此,复杂语言模型的内部工作变得更加可理解。其实,早在6个月前,研究就已经开始进行了:

神经网络的性能评估 (精度、召回率、PSNR 等) 需要大量的资源和时间,是神经网络结构搜索(NAS)的主要瓶颈。早期的 NAS 方法需要大量的资源来从零训练每一个搜索到的新结构。近几年来,网络性能预测器作为一种高效的性能评估方法正在引起更多关注。然而,当前的预测器在使用范围上受限,因为它们只能建模

从一大堆图片中精准找图,有新招了!论文已经中了ECCV 2024。北京大学袁粒课题组,联合南洋理工大学实验室,清华自动化所提出了一种新的通用检索任务:通用风格检索(Style-Diversified Retrieval)。一句话,这种检索任务要求模型面对风格多样的查询条件时,依然能精准找图。

2021 年,美国骨科及医疗科技公司史赛克(Stryker)由于骨植入物强度不够而被召回相关产品,引起领域内的高度关注。那么,这种现象是否有可能从源头被解决呢?清华大学温鹏副教授团队以解决实际应用问题为出发点,提出一种数据高效的新方法:生成式设计-多目标主动学习循环方法。

现在,视频生成模型无需训练即可加速了?!Meta提出了一种新方法AdaCache,能够加速DiT模型,而且是无需额外训练的那种(即插即用)。话不多说,先来感受一波加速feel(最右):可以看到,与其他方法相比,AdaCache生成的视频质量几乎无异,而生成速度却提升了2.61倍。据了解,AdaCac

选自Stanford News机器之心编译参与:刘晓坤、李泽南斯坦福大学的研究者们正在使用计算机视觉系统,利用谷歌街景图片上街边汽车的型号来识别给定社区的政治倾向,其识别准确率超过了 80%。这项研究的论文已发表在《美国科学院论文集》上,研究人员表示,新的研究不仅可以节省大量人力开支,也可以为人口统

“越大越好”的路径走不通?OpenAI正在寻求训练模型的新方法

人工智能 AI 正在加快速度从云端走向边缘,进入到越来越小的物联网设备中。而这些物联网设备往往体积很小,面临着许多挑战,例如功耗、延时以及精度等问题,传统的机器学习模型无法满足要求,

摩尔线程科研团队近日发布了一项新的研究成果《Round Attention:以轮次块稀疏性开辟多轮对话优化新范式》,使得端到端延迟低于现在主流的Flash Attention推理引擎,kv-cache显存占用节省最多82%。










