新火种
2023-12-12
新火种
2023-12-12 

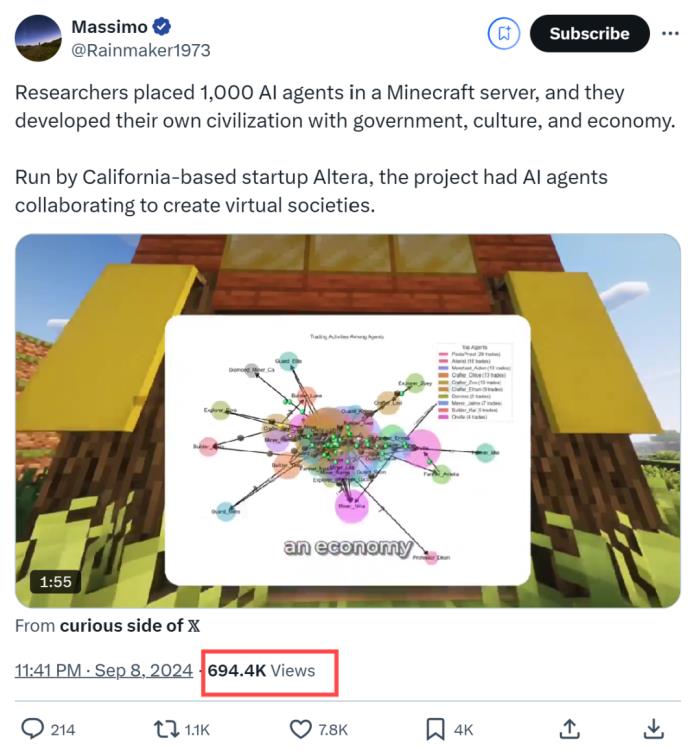
中国团队再获EMNLP最佳长论文!北大微信揭大模型上下文学习机制
EMNLP顶会落下帷幕,各种奖项悉数颁出。
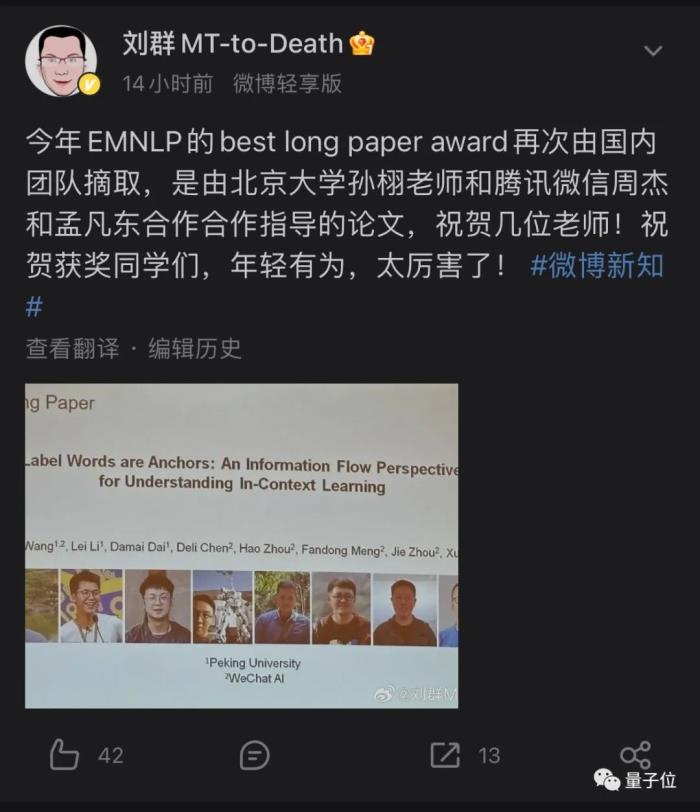
最佳长论文奖被北大微信AI团队收入囊中,由北大孙栩老师和微信周杰、孟凡东合作指导。

他们发现了大模型中关键能力——上下文学习背后的工作机制。
通过理解这一机制,还提出一系列方法来提高其性能。
除此之外,斯坦福Christopher Manning教授做了最后的主题演讲,告诉那些正在为大模型而感到焦虑的NLP博士生们,还有很多有意义的方向可以做。

EMNLP最佳长论文
上下文学习(in-context learning, ICL)是大语言模型的一个重要能力,通过提供少量示范示例,让模型学会执行各种下游任务,而无需更新参数。
目前ICL内在工作机制仍尚无定论,但缺乏对ICL过程的理解会限制能力进一步提升。
基于这一背景,北大&微信AI团队首次从信息流这一角度来探索。此前相关分析研究主要从输入作用和梯度角度进行分析。

首先,他们利用执行ICL的GPT模型,将标签词之间的注意力互动模式(即信息流)可视化。
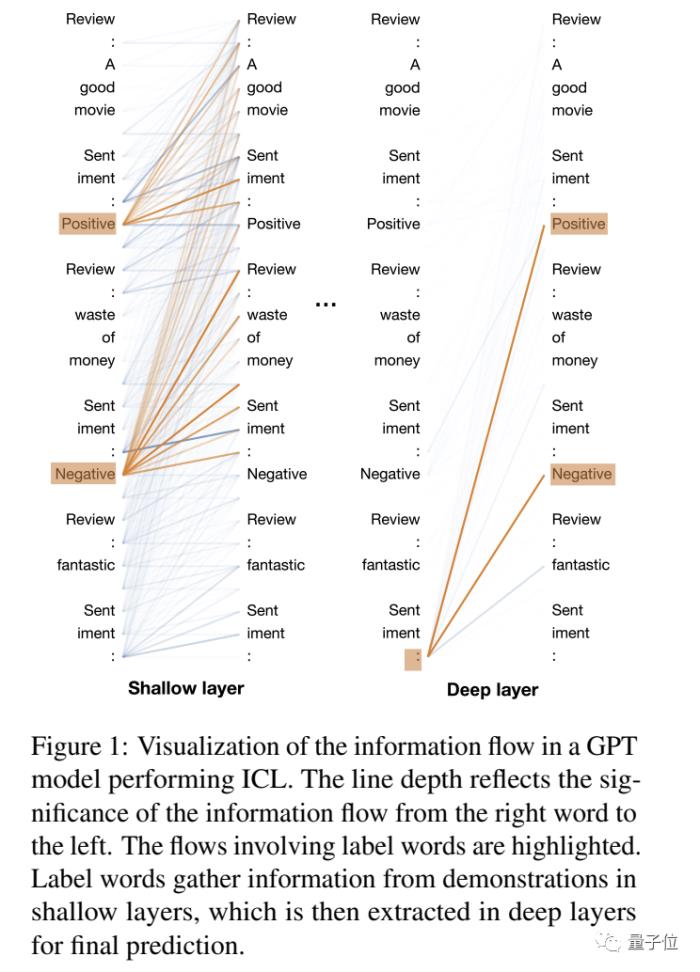
“浅层”或“第一层”指的是离输入较近的层,而“深层”或“最后一层”指的是离输出较近的层。
初步观察表明,标签词在浅层聚合信息,并在深层分发信息。
为了清晰描述这一现象,研究人员提出了一个假设:标签词是ICL中聚合和分发信息的锚点。(Label Words are Anchors)
具体而言:
在浅层,标签词收集演示信息,为深层形成语义表征。在深层,模型从标签词中提取信息,形成最终预测。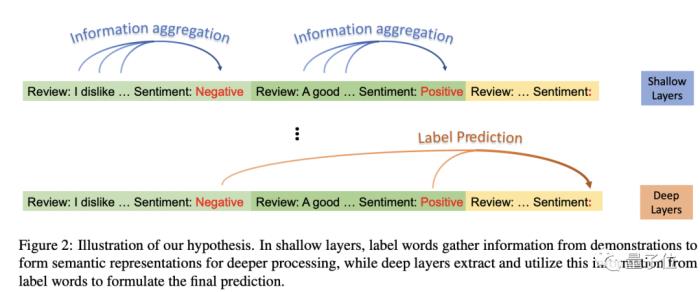
为了验证这一假设,他们设计了两个实验,使用GPT2-XL和GPT-J在多个文本分类基准中验证:
1、阻断某些层中标签词的信息聚合路径,结果发现在浅层隔离会显著影响性能,这表明标签词在浅层中的前向传播过程中收集了有用的信息。
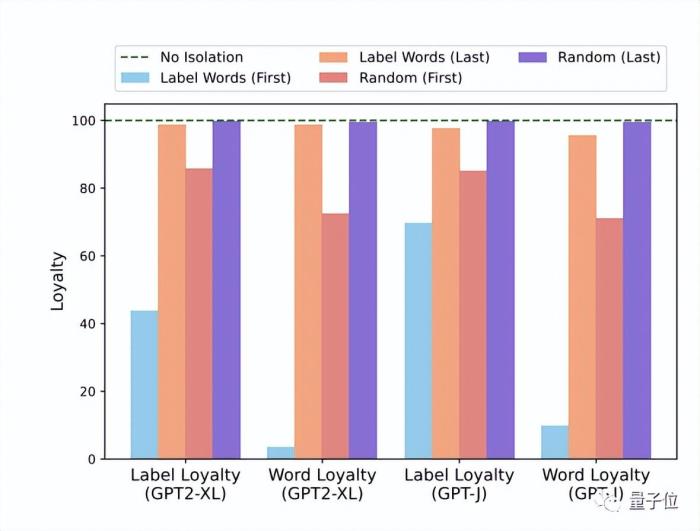
2、目标位置标签词的注意力分布与模型最终预测结果的关系,结果表明两者之间存在很强的正相关性。
基于这样的发现,他们提出了三种改进ICL的方法:一种重新加权方法来提高ICL性能;一种上下文压缩技术来加速推理以及一种用于诊断 GPT2-XL 中 ICL 错误的分析框架。
其他情况除此之外,最佳短论文、最佳主题论文、最佳论文Demo等各种奖项也全都揭晓。
其中最佳短论文:Faster Minimum Bayes Risk Decoding with Confidence-based Pruning,花落剑桥大学计算机系研究团队,一作是华人博士生Julius Cheng。

最佳主题论文:Ignore This Title and HackAPrompt: Exposing Systemic Vulnerabilities of LLMs Through a Global Prompt Hacking Competition
(忽略此标题and HackAPrompt:通过全球黑客大赛揭露大模型的系统漏洞)

还有最佳论文Demo则是由艾伦AI研究所、MIT、UC伯克利、华盛顿大学等研究团队获得,他们提出了PaperMage,处理、表示和操作视觉丰富的科学文档统一工具包。
值得一提的是,斯坦福Christopher Manning教授完成了EMNLP最后一场主题演讲是,现场座无虚席。
主题是大模型时代下NLP的学术研究:Nothing but blue skies!

他告诉正面临「生存危机」的NLP博士生们:
(航空专业的学生不会为他们的博士论文建造波音飞机。他们制造较小的模型,但仍然做出了有意义的贡献。我们也有很多这样的机会。)
随后他又详细地介绍了下有哪些机会可研究之,主要包括系统、待解决问题/数据驱动、机器学习、语言等层面。
系统: 极端量化的小模型;加速。问题/数据驱动:寻找有效的评估方法;如何用哪个很少语言数据来建立NLP模型。机器学习:如何实现持续学习;如何跟人类一样能从少样本事实中学习。语言:较少数据获得系统概括性更强的模型。相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
热门文章