新火种
2023-12-06
新火种
2023-12-06 


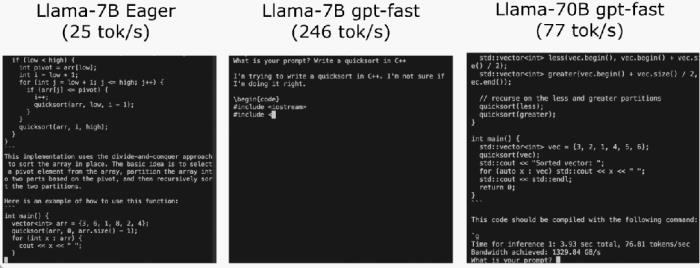
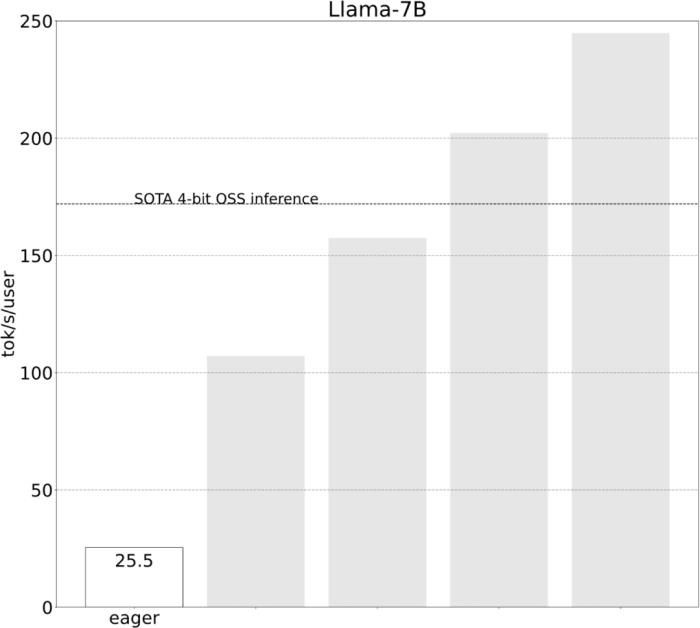
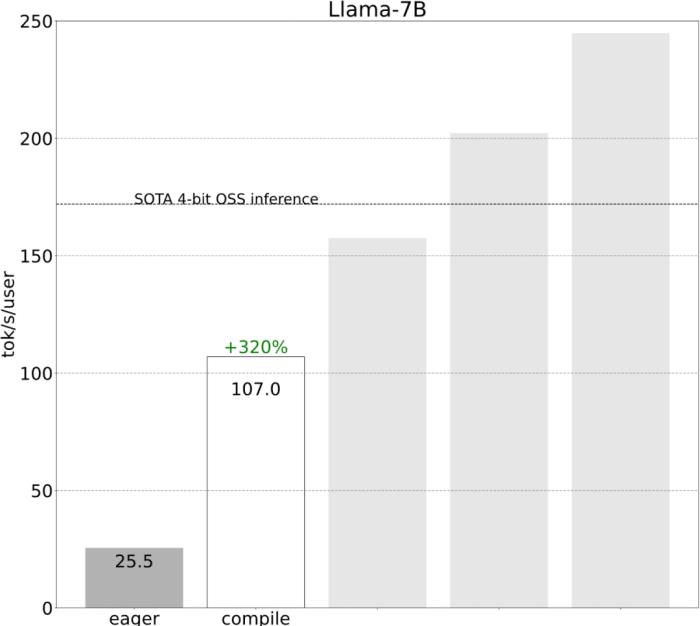
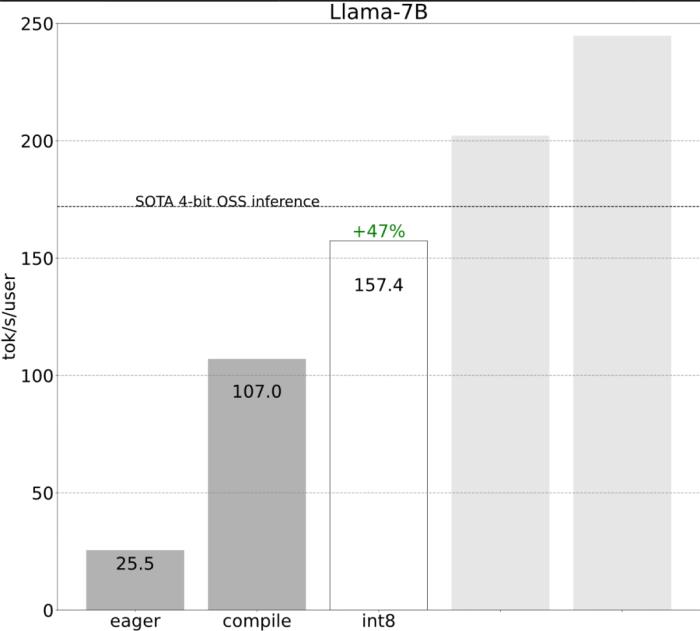
不到1000行代码,PyTorch团队让Llama7B提速10倍
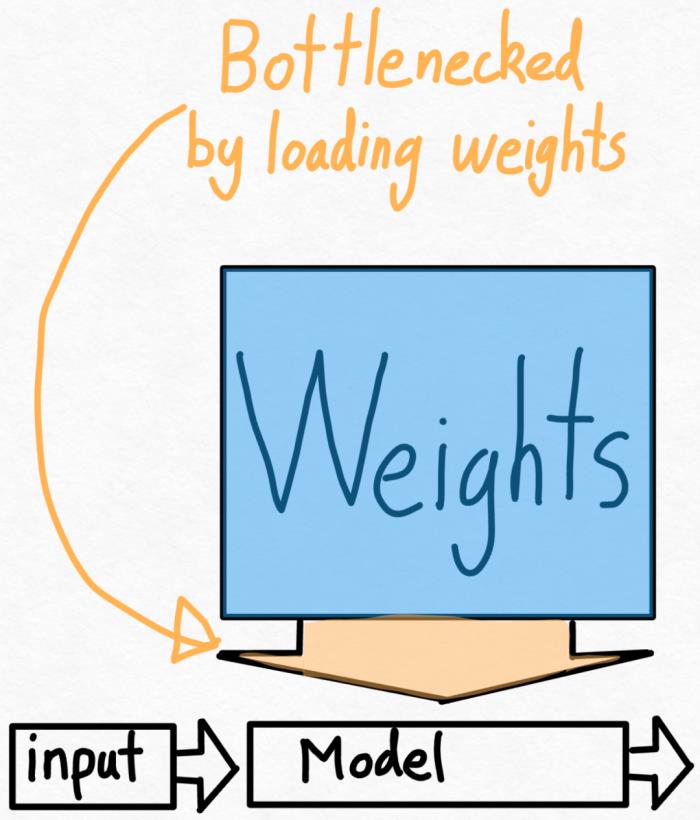
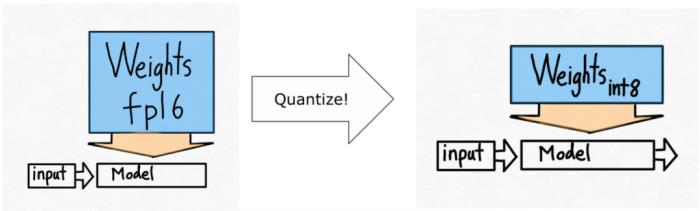
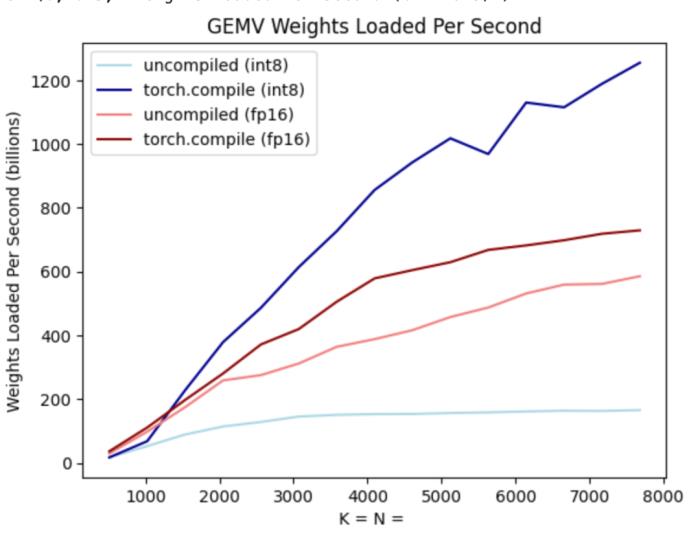
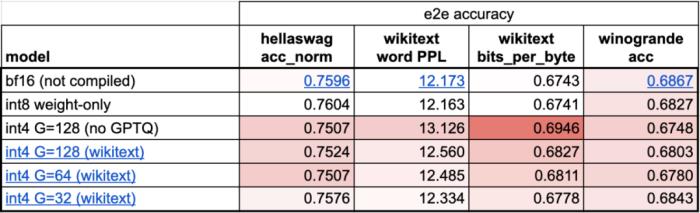
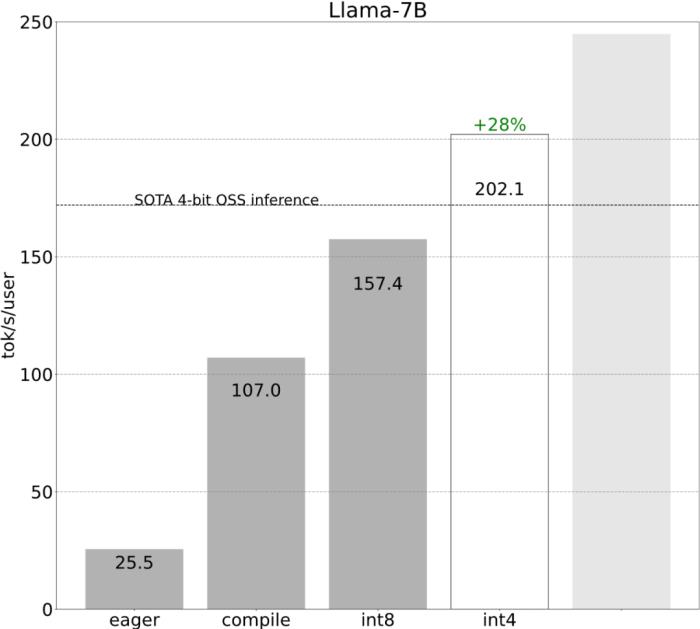
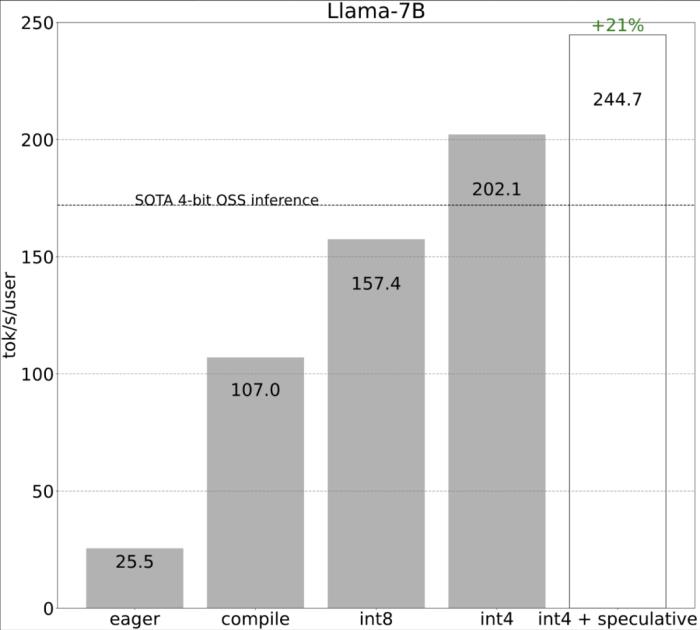
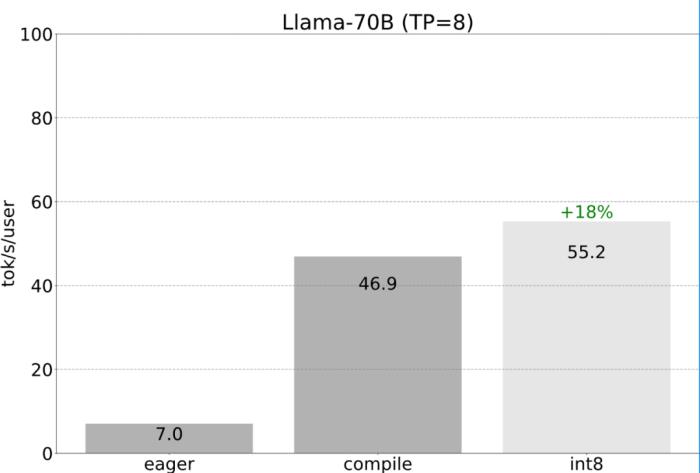
PyTorch 团队亲自教你如何加速大模型推理。在过去的一年里,生成式 AI 发展迅猛,在这当中,文本生成一直是一个特别受欢迎的领域,很多开源项目如 llama.cpp、vLLM 、 MLC-LLM 等,为了取得更好的效果,都在进行不停的优化。作为机器学习社区中最受欢迎框架之一的 PyTorch,自然也是抓住了这一新的机遇,不断优化。为此让大家更好的了解这些创新,PyTorch 团队专门设置了系列博客,重点介绍如何使用纯原生 PyTorch 加速生成式 AI 模型。










相关推荐


- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。