

 新火种
2023-11-20
新火种
2023-11-20 


酷睿轻薄本上跑StableDiffusion,英特尔这项绝活背后的价值
自从 ChatGPT 火热出圈,生成式 AI 大模型在全球掀起了新的技术浪潮。而 AI 作为数字化未来最重要的底层技术,也必然会对人类社会的生活、生产带来颠覆性的改变。
但是就现阶段而言,AI 距离真正改变世界还有很长的路要走,推动生成式 AI 大规模扩展和应用,也还面临很多挑战。
比如,如今生成式 AI 大模型产品主要部署在云端,在传统认知上,云端能够提供远超终端的算力和存储,但现实并非绝对,我们在使用这些云端大模型产品时其实也经常遇到响应缓慢、生成失败等问题,这是因为在使用高峰期,即便是云端服务器也顶不住极端的算力需求。
而且,对于服务提供商来说,生成式 AI 每一次搜索查询,成本都是传统搜索方法的 10 倍。目前每天有超过 100 亿次的搜索查询产生,这样它对云端算力带来的负载以及产生的成本规模难以想象。

在这种情况下,生成式 AI 向终端侧发展,就显得尤为重要了。
尽管单一终端能提供的算力显然无法和云端服务器相比,但如果把全球数十亿甚至数百亿终端的算力都调用起来,那无疑就可以大大分流云端的压力。这也就是 AI 要往终端侧发展的基本逻辑。
更重要的是,在半导体产业的努力下,这几年终端的 AI 性能和算力也在突飞猛进,就拿生产力担当的 PC 来说,行业引领者英特尔就为生成式 AI 在 PC 终端上的落地做出了突出的贡献。

比如,在我们传统的认知里,运行多模态的 AI 大模型必须要有超大显存的专业显卡加持以完成大量的 AI 并行运算,那么,对于轻薄笔记本或者消费级台式机来说,是否也能支持 AI 大模型的顺利运行呢?这其实就是英特尔在终端侧 AIGC 努力的方向之一。
目前在硬件上,英特尔第 12、13 代酷睿处理器以及英特尔锐炫显卡都可以满足 AIGC 在 PC 本地端的高速算力需求。
针对锐炫显卡,首先英特尔在持续增强其本身的性能体验。自推出以来,英特尔锐炫显卡已累计发布超过 20 版驱动更新,今年早些时候,英特尔还通过 Game On 驱动的发布,提升了锐炫显卡在运行一系列备受欢迎的 DX11 游戏时的性能,可以让游戏帧率得到平均约 19% 的帧率提神以及平均约 20% 的 99th Percentile 帧率流畅度提升。

而在今年 5 月,英特尔还展示了用生成式 AI 加速创作文生图的示例,基于英特尔 OpenVINO,AI 绘图开源模型 Stable Diffusion 可以使用开源图片编辑软件 GIMP 在英特尔锐炫 A750、A770 等显卡上流畅运行。只需要输入简单的文本,就能智能实现创意绘图,对于图片创作者来说很实用。
今年 8 月,英特尔又展示了基于 OpenVINO PyTorch 后端的方案,用 Pytorch API 让社区开源模型在英特尔的客户端处理器、集成显卡、独立显卡和专用 AI 引擎上很好的运行。
比如针对开源图像生成模型 Stable Diffusion,英特尔就启用了 OpenVINO 的加速,他们开发了一套 AI 框架,通过一行代码的安装,就可以加速 PyTorch 模型的运行。通过 Stable Diffusion 的 WebUI,可以在锐炬集成显卡和 Arc 独立显卡上运行 Stable Diffusion Automatic1111。

这其中,尤其是让 Stable Diffusion 在搭载集成显卡的轻薄本上运行,可以说是一件具有重要意义的事情。
比如这里,就选择一款轻薄本来做测试,这款产品是通过英特尔 Evo 平台认证的华硕破晓 Air,搭载英特尔 13 代酷睿 i7-1355U 处理器,锐炬 Xe 集成式显卡,16GB LPDDR5 内存。

可以看到 Stable Diffusion 在华硕破晓 Air 集成显卡上的表现效果。96EU 版本的英特尔锐炬 Xe 显卡强大的算力,可以支持 Stable Diffusion 软件上运行 FP16 精度的模型,快速生成高质量图片。小编让 Stable Diffusion 生成一张“有黑色耳朵的小狗”,华硕破晓 Air 只用了大约十几秒的时间就生成出来了。这是一幅 512×512 的图,如果想画的更好,你还可以自己调节参数。
再比如让 Stable Diffusion 生成一张“一大堆煎饼垒起来的食物摄影”,在华硕破晓 Air 上同样也可以轻松生成出来,并且是在实现的。
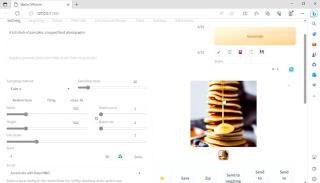
通常我们会认为,轻薄本不太适合做 AI 方面的工作,因为它的配置比较低。但通过上面 Stable Diffusion 的演示,相信大家可以看到 Evo 高性能轻薄本确实可以胜任这些简单的 AIGC 图片创作工作。
如果放在过去,我们很难想象轻薄本可以拥有这样的性能,但随着 13 代酷睿处理器在性能、功耗比方面的进步,以及锐炬 Xe Graphics (96EU) 在 FP16、FP32 浮点性能的大幅提升,同时加入了 INT8 整数计算能力,这些都大大增强了 GPU 整体的 AI 图形计算能力。这也就是华硕破晓 Air 这样的轻薄本也能在本地侧很好地运行 Stable Diffusion 的重要因素。
值得一提的是,在英特尔下一代酷睿处理器 Meteor Lake 中,GPU 核显性能还会得到进一步提升,将拥有 8 个 Xe GPU 核心 128 个渲染引擎,更增加了 8 个硬件的光追单元,还会引入 Arc 显卡的异步拷贝,乱序采样等功能,也对 DX12U 做了优化。
不仅如此,英特尔还在 Meteor Lake 中加入了集成式 NPU 单元,实现更高效能的 AI 计算,它包含了 2 个神经计算引擎,能够更好地支持包括生成式 AI、计算机视觉、图像增强和协作 AI 方面的内容。
同时除了 NPU,CPU 和 GPU 也都可以进行 AI 运算,不同场景下会用不同的 AI 单元去应对,彼此协调,如此一来,其整体能耗比相比前代最多可以提升 8 倍之多。因此,未来搭载 Meteor Lake 处理器的轻薄本在本地 AIGC 创作方面的表现会更加令人期待。

此外,如果追求更好性能,大家也可以选择英特尔锐炫 Arc 独显的设备,在 Arc 独显上跑 Stable Diffusion,速度会快很多。比如今年早些时候英特尔也还展示了在搭载 i7-13700K CPU + Arc A770 独显的机器上运行 Stable Diffusion “图生图”、“人物动作三维数字重建”的效果,速度非常快。

总之,未来对于 PC 来说,所谓的性能将不仅局限在处理器的核心数、线程数、主频这些传统参数,而更在于 AI 运算和创作能力是否强大,换句话说,AI 定义芯片的时代正在到来,而 AI PC 将真正帮助我们实现生产力的大解放。因此,英特尔对于实现终端侧 AIGC 所做的努力无疑具有重要意义,他们为用户提供更智能、高效的移动计算体验,推动人工智能技术的发展和应用走向终端和云端协同的新阶段。
相关推荐



- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。










