

 新火种
2023-11-17
新火种
2023-11-17 


Midjourney迎来最强对手,种子轮融资大佬云集,测试版让马斯克一「键」穿越
机器之能报道编辑:SIA
一直以来,Midjourney 稳坐 AIGC 文生图的王座,少有威胁,直到这家公司的出现。
8 月 23 日,生成式人工智能创业公司 Ideogram AI 正式官宣:「我们正在开发最先进的人工智能工具,使创意表达变得更容易、更有趣、更高效。」官网写道。团队核心成员也是谷歌大脑 Imagen 团队主要成员, Ideogram AI 也被认为试图将 Imagen 发扬光大:
Mohammad Norouzi(CEO )、Jonathan Ho (联合创始人)、 William Chan和 Chitwan Saharia 都是谷歌文本至图像 AI 模型Imagen 的核心作者,相关论文曾入围NeurIPS 2022 Outstanding paper 。Imagen 使用 Transformer 语言模型将输入的文本转换成一个嵌入式向量的序列。然后,连续的三个扩散模型( diffusion model )会将这些嵌入式的向量转换成 1024x1024 像素的图片。由于概念上简单且易于训练,还能产生惊人的强大效果,Imagen 不仅重塑了大家对扩散模型的认知,也开辟出一条 DALL-E 2 以外的文生图新范式。后来,Meta 宣布其文本视频 AI 模型 Make-A-Video 之后,谷歌又发布了视频模型Imagen Video(看看,名字都差不多),基于级联视频扩散模型来生成高清视频。Imagen Video 继承了此前 Imagen 文本生成图像系统的准确描绘文字的功能,以此为基础,仅靠简单描述产生各种创意动画。
 官网显示的当前团队成员。「我们的创始团队他们曾在谷歌大脑、UC 伯克利分校、卡内基梅隆大学和多伦多大学领导过变革性人工智能项目。」官网显示。
官网显示的当前团队成员。「我们的创始团队他们曾在谷歌大脑、UC 伯克利分校、卡内基梅隆大学和多伦多大学领导过变革性人工智能项目。」官网显示。
Mohammad Norouzi 创业之前在谷歌大脑工作了 7 年,在谷歌的最后级别是高级研究科学家,工作重点是生成模型。Ideogram AI在人工智能方面的基础工作积累当中,他的涉猎范围最广,包括Imagen、Imagen Video、用于语音合成的WaveGrad 、神经机器翻译、用于学习视觉表示的对比学习等。合作的团队成员也最多。联合创始人Jonathan Ho ,UC 伯克利博士毕业,在扩散模型方面做了非常重要的工作,以至于他的离开被业内人士视为谷歌的重大损失。

2022 年 4 月,谷歌提出了视频扩散模型(Video Diffusion Models),首次报告了扩散模型根据文本生成视频的结果(效果不俗)。Mohammad Norouzi 、Jonathan Ho 正是文章的主要作者。Jonathan Ho 也是扩散模型奠基作品之一、提出去噪扩散模型 Denoising Diffusion Probabilistic Models 一作。(有趣的是,合著者之一Pieter Abbeel也是这家公司的投资人)。Chitwan Saharia 在谷歌工作时,主要负责领导 image-to-image 扩散模型的工作。除了扩散模型方面的工作,Willian chan 在谷歌工作时从事过神经语音识别研究,与 Mohammad Norouzi 合作研究用于语音合成的 WaveGrad 。或许是因为谷歌囿于安全、伦理方面的顾虑,需要再做进一步的规范,来选择是否开源Imagen 和 Imagen Video ,这些中坚力量决定离开创业。「我们正在突破人工智能的极限,重点关注创造力以及信任和安全的高标准。」官宣最后写道。
 官网截图当天,公司还宣布已筹集由 a16z 和 Index Ventures 领投的总计 1650 万美元的种子融资。几位如雷贯耳的行业中坚力量也参与了本轮投资。
官网截图当天,公司还宣布已筹集由 a16z 和 Index Ventures 领投的总计 1650 万美元的种子融资。几位如雷贯耳的行业中坚力量也参与了本轮投资。
例如,Node.js 之父 Ryan Dahl 、Uber首席科学家 Raquel Urtasun、Jeff Dean、Andrej Karpathy、Pieter Abbeel、GitHub 创始人 Tom Preston-Werner 。同时,公司也宣布迎来 v0.1 的公开测试版。我们也简单体验了一下。目前仅提供文字生成图片的服务,操作很简单,仅需输入你的需求,然后选择生成图像的风格和比例即可。系统理解能力还是不错的,特别是对图片中需要生成的文字的理解。缺点是响应速度比较慢,还不能理解中文指令,构图的空间理解也有待提升。
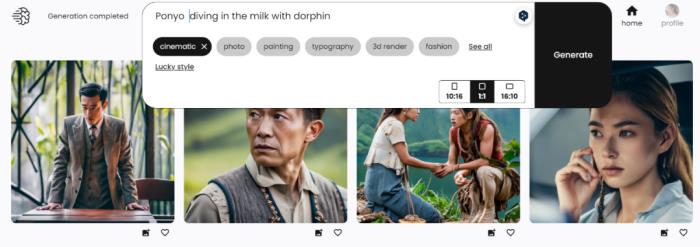 操作页面「Ponyo diving in the milk with dorphin 」,AI 似乎无法理解命令里的 「milk」,而是按照自己的理解(sea)给出了画面。
操作页面「Ponyo diving in the milk with dorphin 」,AI 似乎无法理解命令里的 「milk」,而是按照自己的理解(sea)给出了画面。 我们换了一个输入:「 Elon Musk take hands with Lisa (blackpink )in a Tesla car,( cinematic )」基本正确。只是两个人的脸蛋都有点问题,这是 Lisa?
我们换了一个输入:「 Elon Musk take hands with Lisa (blackpink )in a Tesla car,( cinematic )」基本正确。只是两个人的脸蛋都有点问题,这是 Lisa?
 让马斯克穿越,尝试一下汉服风格,结果还真有点大侠的感觉。「 Elon Musk with long hair in chinese traditional clothing, photo」
让马斯克穿越,尝试一下汉服风格,结果还真有点大侠的感觉。「 Elon Musk with long hair in chinese traditional clothing, photo」
「 Blackpink Jennie but very fat, photo。」不错,原来长胖了后大概是这个样子。
 再看看一些推特网友的使用结果。即使在生成的图片里还需要生成一些文字,系统也可以做到。例如,「An adorable minion holding a sign that says 『It's over, MidJourney』, spelled exactly, 3d render, typography」推友表示,虽然系统并不总是能够正确拼写,但成功率还是不错的。
再看看一些推特网友的使用结果。即使在生成的图片里还需要生成一些文字,系统也可以做到。例如,「An adorable minion holding a sign that says 『It's over, MidJourney』, spelled exactly, 3d render, typography」推友表示,虽然系统并不总是能够正确拼写,但成功率还是不错的。

「A cute fluffy pikachu standing on a big fluffy moon, holding a neon sign says 『to the moon』 , 3d render」
 最近上映的电影中,《芭比》和《奥本海默》都比较引发关注,推友要求生成有关「巴本海默(barbenheimer)」的电影画报设计,风格上参考芭比和核武器。效果如下。虽然这些电影信息很可能出现在训练截止日期之后,但系统还是很好地处理了这个合成词。另外,老问题,人物的脸还不够好。
最近上映的电影中,《芭比》和《奥本海默》都比较引发关注,推友要求生成有关「巴本海默(barbenheimer)」的电影画报设计,风格上参考芭比和核武器。效果如下。虽然这些电影信息很可能出现在训练截止日期之后,但系统还是很好地处理了这个合成词。另外,老问题,人物的脸还不够好。

「Word『surreal』spelled and rendered in a Dali-style surreal painting, typography」

「a melting snowman in a volcano 」
 「Word 『NVIDIA』rendered in GPU chip circuit typography, cyperpunk, sci-fi」
「Word 『NVIDIA』rendered in GPU chip circuit typography, cyperpunk, sci-fi」 「beautiful girl in Dali's painting, with a caption『Stanford』, typography 」
「beautiful girl in Dali's painting, with a caption『Stanford』, typography 」 一只时髦的布娃娃猫,戴着古驰太阳镜,举着一个写着『周日快乐』的牌子,黑色背景,海报
一只时髦的布娃娃猫,戴着古驰太阳镜,举着一个写着『周日快乐』的牌子,黑色背景,海报 场景中有 4 个物体。一个红色的金字塔位于一个蓝色的立方体上面。一个黄色球体位于这个蓝色立方体的下方。一个大理石六边形位于金字塔的左边,蓝色立方体的顶部。看来,系统目前对构图和空间的理解还不到位。
场景中有 4 个物体。一个红色的金字塔位于一个蓝色的立方体上面。一个黄色球体位于这个蓝色立方体的下方。一个大理石六边形位于金字塔的左边,蓝色立方体的顶部。看来,系统目前对构图和空间的理解还不到位。 其他首页上的作品展示。
其他首页上的作品展示。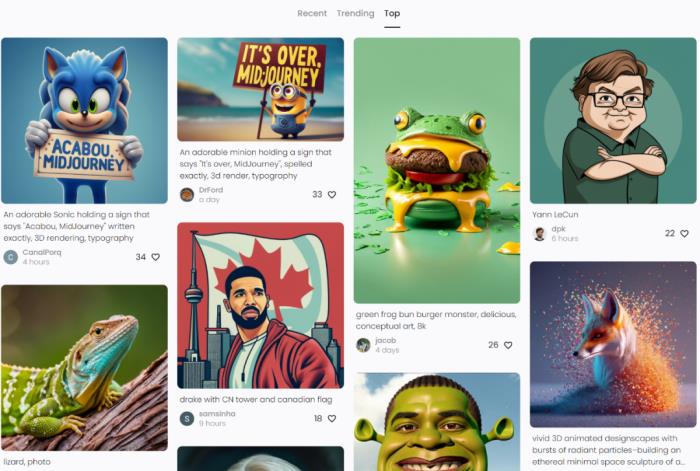
相关推荐



- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
热门文章










