

 新火种
2023-11-16
新火种
2023-11-16 


Agent4Rec来了!大模型智能体构成推荐系统模拟器,模拟真实用户交互行为
一直以来,推荐系统领域面临模型线上线下效果差距大的痛点问题,昂贵的线上 A/B 测试成本使得广大研究人员望而却步,也造成学术界的推荐系统研究与工业界的实际应用间的巨大割裂。随着大语言模型展现出类人的逻辑推理和理解能力,基于大语言模型的智能体(Agent)能否模拟真实用户的交互行为,从而构建一个可靠的虚拟推荐 A/B 测试场景,以帮助推荐研究的应用落地,是一个急迫、重要且极具经济价值的问题。
为了回答这个问题,来自新加坡国立大学 NExT++ 实验室团队构建了 Agent4Rec,一个由 1000 名 agents 构成的电影推荐系统模拟器。这些 agent 由真实用户初始化,由 ChatGPT-3.5 驱动,根据用户喜好与特质,对封装的不同推荐算法和其推荐的电影做出个性化反应。这些个性化反应模拟真实用户在推荐系统中的行为,包括观看或拒看电影,给电影评分,翻到下一页电影推荐列表,疲倦度估计,因不满意或疲惫退出推荐系统,给推荐算法进行评价等。广泛的实验评估表明,Agent4Rec 里的 agent 能大概率反映真实世界的用户行为。

1.Agent4Rec 平台构建
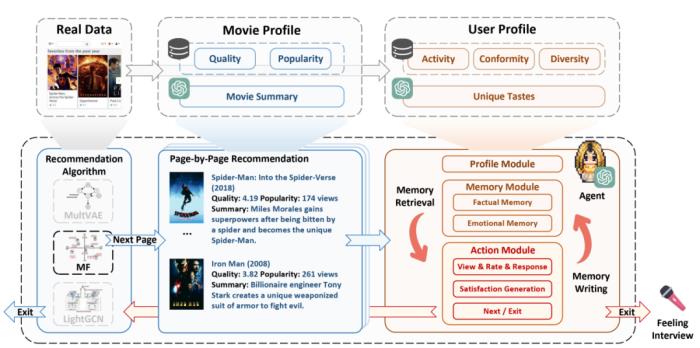
Agent4Rec 中的每一个用户,也即 agent,由 profile module、memory module、action module 构成。作者使用 MovieLens-1m 中的真实用户数据初始化 agent 档案。根据用户的历史交互生成 agent 的电影偏好,根据用户的历史活跃度、从众性和观影多样性生成 agent 的交互特征。
推荐系统将采取逐页推荐的方式,根据特定的推荐算法向用户推荐电影列表。仿照真实的手机 APP 推荐场景,每页将展示 4 部电影。每部电影的信息包括电影名、历史评分、电影简介等。每个 agent 将根据自身的电影喜好、疲惫程度以及个人记忆对推荐的电影做出反应,如观看或评价电影。同时,历史推荐内容和 agent 行为将被存储在记忆中,agent 通过 reflection 的方式总结对推荐系统的满意度和自身的疲惫程度。Agent 在每一页推荐结束后,都根据自身满意度和疲倦度,选择翻到下一页或者退出推荐系统。在用户退出系统之后,采访用户退出推荐系统的原因和对推荐电影的评价。
2.Agent 行为模拟真实性检验
用大语言模型智能体模拟人类行为最关键的问题,在于评估 agent 能够多大程度的模拟用户的真实喜好。Agent4Rec 在推荐场景下首次给出了一个实验级别的回答。
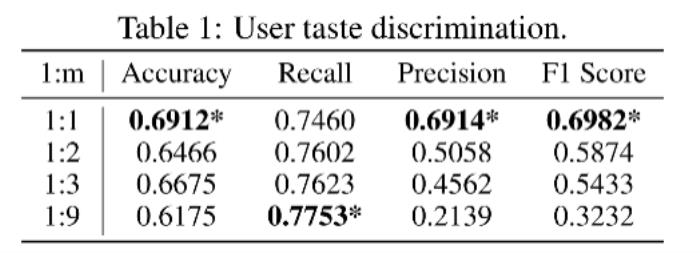
为了衡量用户的电影喜好能否被 agent 正确捕捉,作者首先让 agent 对用户交互过的测试集中的电影和随机采样的负样本电影进行喜爱与否判断。结果表明,agent 能够捕捉约 70% 的用户喜好。
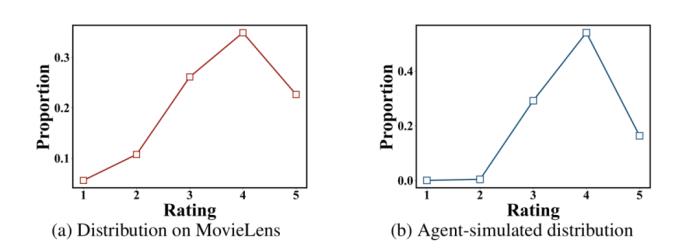
在验证了 agent 的电影喜好合理性的基础上,1000 个 agent 被投放到逐页推荐场景下,agent 可以选择提前退出推荐系统,或在达到 5 页之后强制退出,同时 Agent 对选择观看的电影进行 1 到 5 分的评分。下图实验结果表明 agent 的评分与真实数据中的用户评分呈现分布一致性。
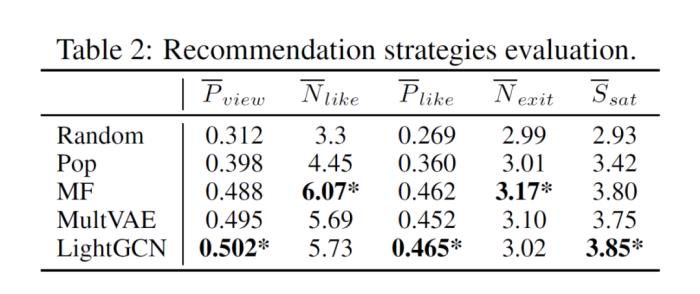
为了验证 Agent4Rec 作为 A/B 测试平台的可能性,作者将 5 个常见的推荐策略部署到 Agent4Rec 平台,收集 agent 反馈(平均观影比例、平均喜爱数、平均喜爱比例、平均退出页数、用户平均满意度)。下表结果表明,基于算法的推荐系统(MF、MultVAE、LightGCN)表现大幅优于基于策略的推荐系统(Random、Pop)。且总体而言,LightGCN 的表现优于其他算法。这一结果证明,agent 能对不同的推荐系统的推荐结果进行分辨。在未来,一个精心设计的基于大语言模型的推荐系统模拟器或许能够充当理想的离线 A/B 测试平台,并给出符合企业需求的用户评价指标。
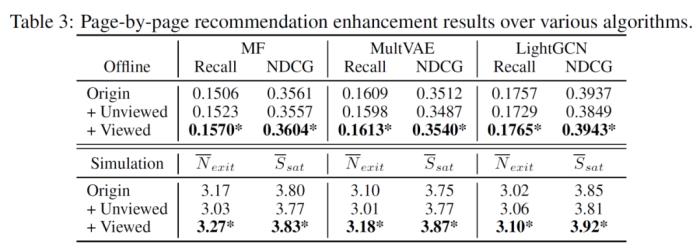
仿照现实生活中推荐系统会根据用户反馈进行更新的场景,作者在完成一轮推荐之后,将 agent 选择的高分电影或未观看的电影以正样本加入训练集,重新训练推荐系统,并将重新训练的推荐算法再次部署到 Agent4Rec 平台。结果表明,将 agent 选择的高分电影对推荐系统进行再训练,在离线指标与模拟的 “在线” 指标上均得到了提升。而将 agent 不喜欢的电影作为数据增强则在大多数情况下起到了负向的效果。这从侧面说明 agent 的行为与真实用户行为对齐。
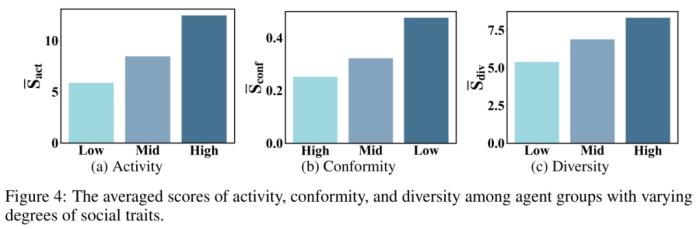
同时,推荐系统中的真实用户往往具有不同的特质,如活跃性、从众性和观影多样性等。作者根据数据集中用户的不同统计信息,将 agent 在每个特质上分为 3 组并给出不同的用户画像。在模拟完成后,收集 agent 的交互次数、agent 评分与用户历史评分的均方误差、agent 交互电影种类数这三个指标,作为 agent 活跃性、从众性、观影多样性特质衡量。实验结果表明,在三个组间 agent 的平均表现符合预期,存在显著差异。
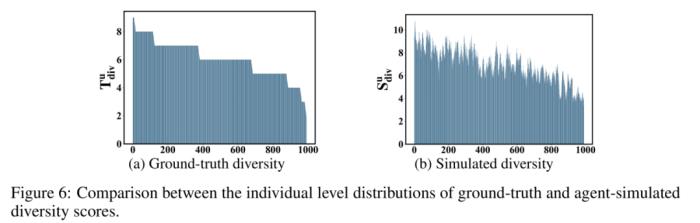
在个体层面,agent 的表现也与真实用户呈现一致性。以下图中的用户观影多样性为例,每个用户的真实观影种类数与 Agent4Rec 中的 agent 所观看的电影种类数呈现一致趋势。
作者还通过消融实验研究了不同特质初始化对 agent 行为起到的作用。下述实验结果表明,没有个性化的特质初始化,agent 的行为呈现趋同,与现实生活中的真实用户行为长尾分布有别。
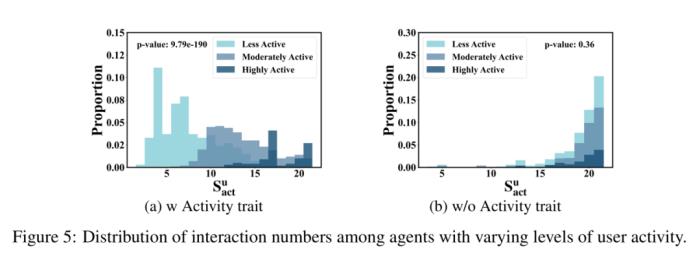
3. 探索推荐系统中尚未解决的问题
获得一个真实的推荐系统模拟器,将极大地帮助推荐研究工作的推进。鉴于 Agent4Rec 对用户较大程度的真实行为模拟,作者探索了两个有意思的待解决问题。
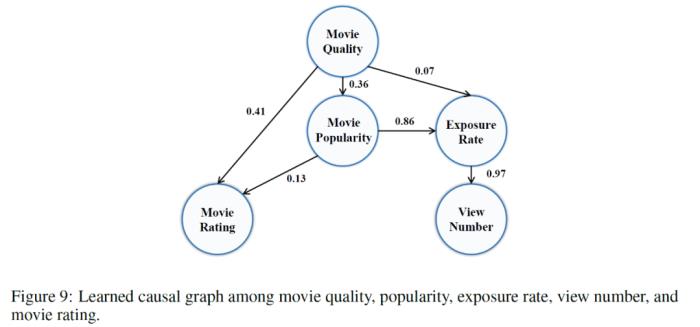
首先,作者利用 Agent4Rec 平台收集多维度推荐数据,探究推荐系统中潜在的因果关系。作者选取 5 个推荐系统中常见的变量:电影质量、电影流行度、电影曝光率、电影浏览量、电影评分,通过 DirectLiNGAM 建模一个带权有向无环因果图,分析这 5 个变量间的因果关系。下述因果图的左半部分说明,电影评分只受电影质量与电影流行度的正向影响。因果图的右半部分说明电影的质量和流行度将共同影响电影的曝光率,进而影响电影被点击次数。这反映了推荐系统中的的流行度偏差效应:更流行的物品被更多曝光,进一步导致物品流行度环路放大效应。
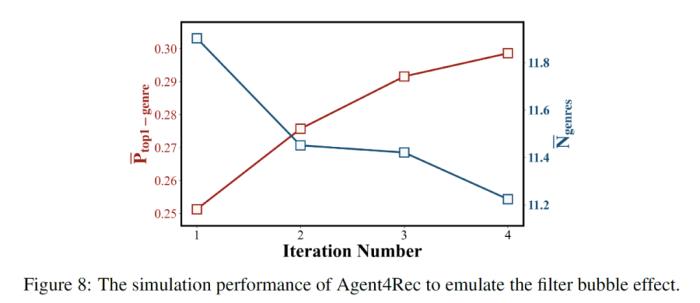
作者还进一步探究了推荐系统中信息茧房问题。作者不断将 agent 选择的物品作为正样本加入训练集,训练新的推荐算法并收集 agent 反馈。随着模拟与重新训练的轮数增多,推荐系统对个体用户推荐的第一大类电影的比例逐渐上升,且推荐系统对个体用户推荐的平均电影种类数下降。这一现象表明,用户接受的信息种类将在推荐算法的干预下越来越单一。
4. 总结与展望
本篇工作探索了基于大语言模型的智能体(Agent)模拟真实推荐场景下用户行为的可能性。尽管大语言模型仍存在诸如幻觉在内的种种问题,但 Agent4Rec 上的多智能体仍在多个方面展现出了和真实用户群体一致的行为。期待在未来,一个精心设计的基于大语言模型的 agent 平台,能够足够真实地模拟推荐场景的各个维度,为学术界和工业界的研究提供更多便利。
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
热门文章










