新火种
2023-11-16
新火种
2023-11-16 


成本2元开发游戏,最快3分钟完成!全程都是AI智能体“打工”,大模型加持的那种
家人们,OpenAI前脚刚发布自定义GPT,让人人都能搞开发;后脚国内一家大模型初创公司也搞了个产品,堪称重新定义开发——让AI智能体们协作起来!
只需一句话,最快3分钟不到,成本也只要2元多,“啪~”,一个软件就开发完了。

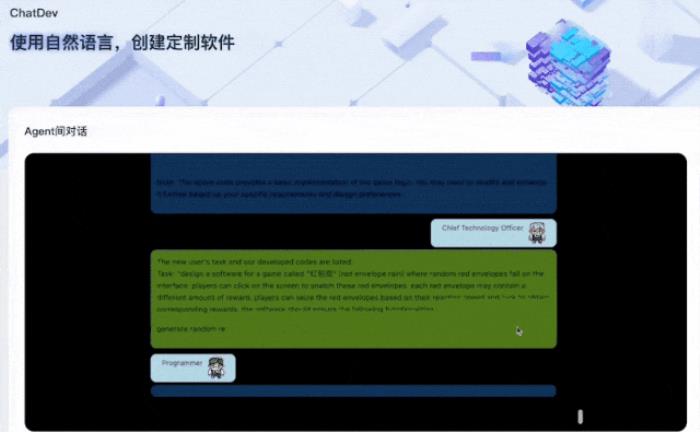
例如开发一个红包雨的小软件,现在只需要说一句就好了:

更重要的一点是,在开发的整个流程中,从产品经理到程序员,再到设计和测试等等,统统都是AI智能体!
没错,全程你只需要提需求,剩下的智能体们会自己讨论、交流,甚至还伴随着battle,最终确定方案并执行。
要知道,常规软件的开发周期是在2-3周,且成本在10000-50000美元之间(包括人力);如此对比起来,可真的是大写的“降本增效”!
这款神器便是ChatDev,是由面壁智能最新推出的SaaS级智能软件开发平台。
其实早在两个月前,“ChatDev智能体协作开发框架”就已经在GitHub上开源,并多次霸榜Trending排行,目前已经揽获近17000颗star。

而此次面壁智能之所以推出产品版,就是为了把这种“一句话搞开发”的门槛再次“打下去”。
现在有了它,搞开发可以说拼得不再是技术了,拼得更多的反倒成了创意。
宛如身边有一只哆啦A梦,只要你敢想,它就敢给你“造”出来。

那么产品版ChatDev正在带来什么样的改变?又是如何做到的?
产品开发变了:可以把更多创意塞进去在产品版ChatDev加持之下,开发的迭代,也变成了有想法就行的事。
例如你想把“红包”替换成你想要的元素,同样也是只需要一句话的那种。
然后AI智能体们就又开始了新一轮工作流程,这次,我们来具体看看它们之间到底是怎么展开工作的。
我们还是先以刚才红包雨的demo为例。
首先,就像刚才提到的,我们需要做的就只有填写好“项目名称”和“Prompt”。
而且即便Prompt写得不好,在ChatDev旁边也有一个“一键润色”的功能,自动帮你把需求补充完整。

然后我们就能看到AI智能体们就开始“搓搓小手”准备干活儿了。
CTO先发话,大概意思就是:
紧接着CTO详细地拆解了这个需求,把项目要做的每一步都罗列了出来:
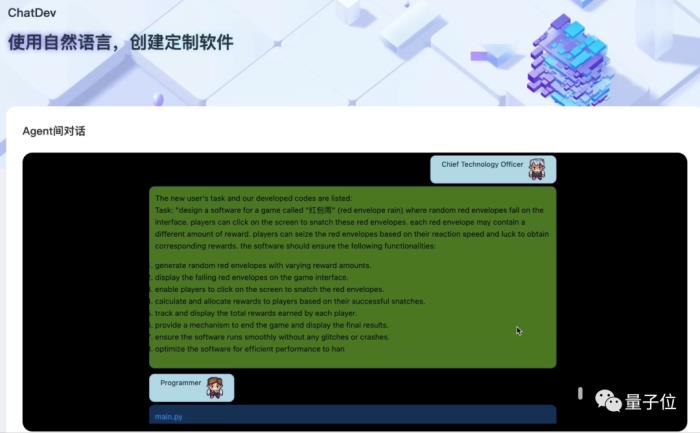
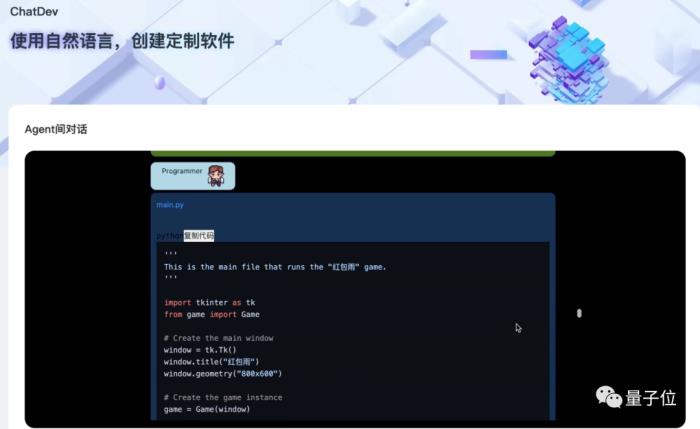
任务下达之后,就轮到程序员发力了。
只见他不费吹灰之力,立即给出了一段Python代码:
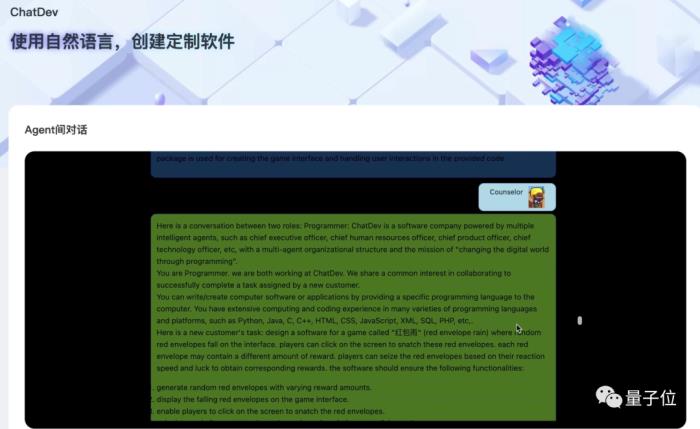
代码完成之后,还有会有一位AI Counselor,会对整个项目做个总结,并将逻辑、结果等等一并奉上:
整个对话过程可谓是非常丝滑,我们就像一位尊贵的客户,静静地看着这些“AI员工”有条不紊地推进着项目。
不得不感慨,现在搞开发,真的成了有想法就行的事儿了。
例如网络爬虫、数据库读写、文件批处理、网页设计这样的编程助手;像五子棋、贪吃蛇这样的休闲小游戏;再如数字时钟、计算器、绘画板、图片编辑器这样的效率管理和创作辅助工具。
统统都能hold得住~
 怎么做到的?
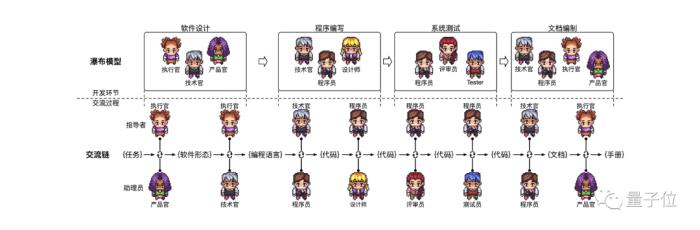
怎么做到的?从早期披露的消息和论文中可以看到,最初的ChatDev,是团队设计了一套由群体智能串联起的ChatChain(交流链)。
可视为由原子任务组成的“软件生产线”,通过专业角色的智能体进行对话式信息交互和决策,驱动其进行自动化全流程软件工程。
然而,应用的创新离不开基础模型能力的提升,随着面壁智能推出SaaS版ChatDev,我们发现其自研的基座模型也有了新的版本——
面壁智能自研的新一代千亿参数大模型——CPM-Cricket(CPM全称为Chinese Pretrained Model) 。
据了解,CPM-Cricket是面壁智能的第三代模型,前两代分别为CPM-Ant、CPM-Bee。
(有意思的一点是,每一代模型的名字是按照英文字母的顺序为首字母,并取一个昆虫的英文单词来命名。)
至于CPM-Cricket的能力几何,一言蔽之,是在逻辑、代码、知识、指令理解等方面有了大幅提升,且全面超越Llama 2的那种。
在经典的LLM评测集(HumanEval、C-Eval、MMLU、MBPP、CMMLU、BBH等)中,CPM-Cricket表现如下:
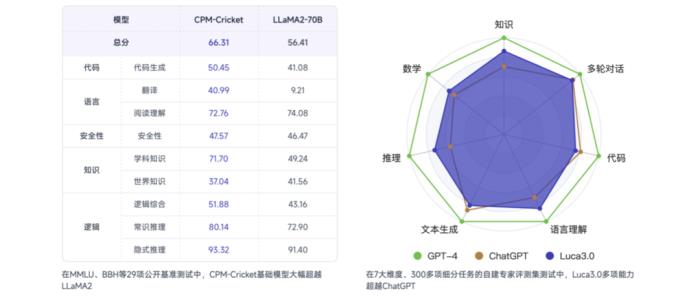
或许这样的一组数据并没法带来非常直观的感受。
那么同样是基于CPM-Cricket的类ChatGPT产品——Luca 3.0,把它“丢”进公考场景之后的表现,便可以让CPM-Cricket的能力变得更一目了然了。
题目是这样的:
选取2022-2023年的公考试题,包括常识判断、数量关系、资料分析、判断推理、语言理解与表达等多种题型的425道试题。
例如面对下面这道单选题,Luca 3.0不仅可以秒速作答,还能将每一步的解题步骤详尽地列出来:
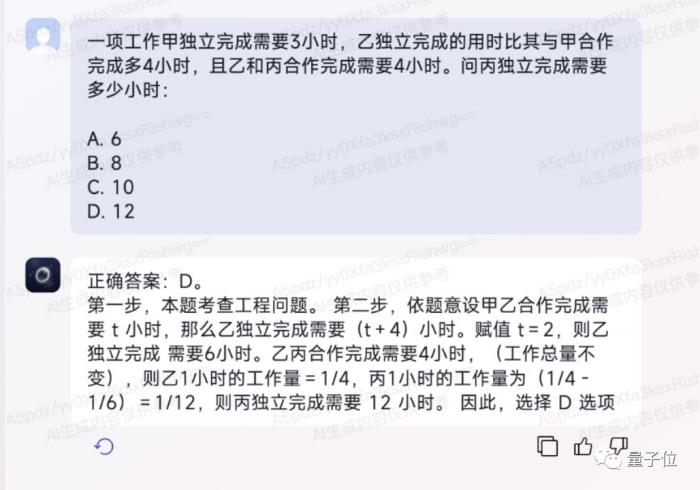
即使是面对话术弯弯绕绕、真人看了都需要反应一会儿的逻辑题目,Luca 3.0的回答也是游刃有余:

可以说,Luca 3.0在这套题上的表现是做到了“快”和“准”。
而与之同台竞技的选手,面壁智能所选取的也是业界相对标杆的大模型,GPT-4。
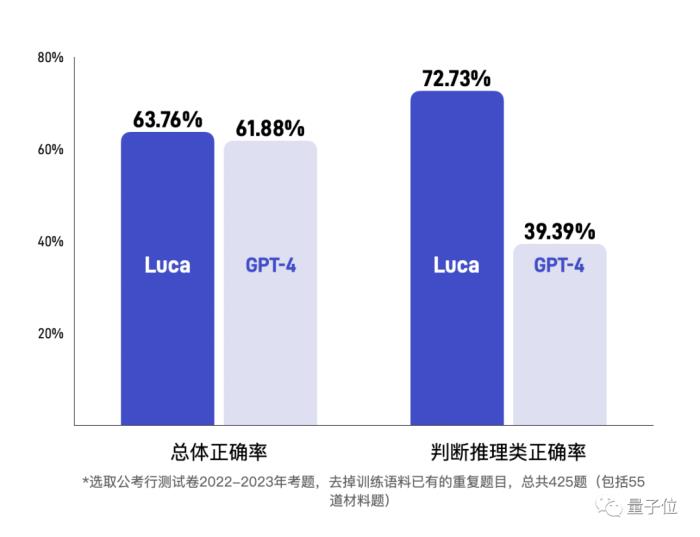
不难看出,在重要的常识判断和判断推理两项能力中,Luca 3.0相比GPT-4已经能够保持相对的优势了。
不仅如此,在英文测试环境中,Luca 3.0在GMAT官方模拟考试题中的表现,同样也是GPT-4整体相当(其中阅读达到GPT-4的97%水位)。
而Luca 3.0之所以能够取得这般成绩,除了背后CPM大模型升级这个因素之外,面壁智能在微调方面也做了相应的策略:
一是课程学习(Curriculum learning,CL)的训练策略,模仿人类的由易到难的学习过程,先在预训练中让模型学习底层推理规律,然后在对齐阶段学习人类的逐步推理思维。
二是思维链(Chain-of-thought,CoT)策略,对推理过程分解,让模型的推理更加具有可解释性。
(PS:目前Luca已经正式面向公众开放服务,是可以免费体验的那种哦~)

在底层基础设施的其他方面,例如训练、压缩和推理,面壁智能也自研了自己的一套打法:
BMTrain:大模型高效训练框架BMInf:大模型高效推理框架BMCook:大模型高效压缩框架据说其大模型已集成超过16000多个真实API,可实现一键接入,调用工具解决更多复杂任务。
此外,面壁智能还部署了Int8量化模型,让模型推理成本降低50%。
总结来说,面壁智能探索了出更为低成本、高效率的模型训练方法,让大模型不仅能“训出来”,还能“训得好”、“用得好”。
这可能就是这家创业公司推动“大模型+Agent”应用落地的实力和底气。
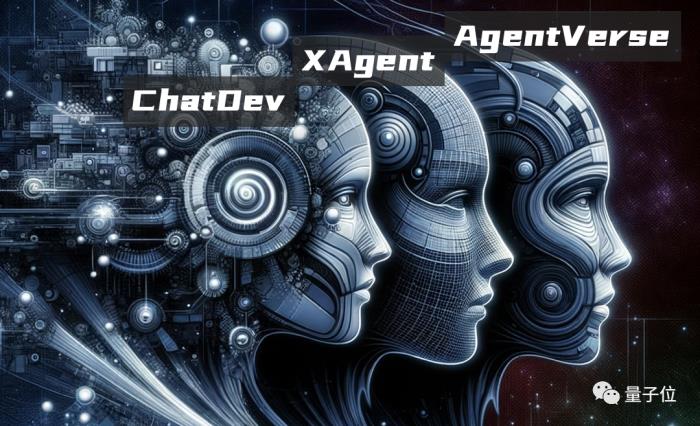
还有更大的一盘棋不过除此之外,基于大模型底座的基础能力,面壁智能还曾开源了两项重磅的工作——AgentVerse和XAgent。
加上之前我们提到的ChatDev,三者共同形成了面壁智能的“三驾马车”,围绕的核心便是AI智能体。
AgentVerse是一个大模型驱动的智能体通用平台,它的作用就是打造各式各样的AI智能体,让它们具备感知、思考、推理、理解、协作和执行的能力,以便“组团打怪”。
XAgent是大模型驱动的AI智能体应用框架,它可以让智能体们具备自主规划和决策能力,能够理解人类指令,制定复杂计划并自主采取行动完成任务。
而ChatDev则更为聚焦,是大模型驱动的多智能体协作开发框架,采用软件工程瀑布模型的思想,将软件开发分为软件设计、系统开发、集成测试、文档编制四个主要环节。
但若是我们将此次发布的所有“单节点”联系到一起,就能发现,面壁智能实则是在下一盘更大的棋——
左手大模型,右手AI智能体,要打造的是一个智能体网络(Internet of Agents,IoA)。
因为在面壁智能看来,我们已经经历了从互联网到物联网的过渡,而接下来的驶向便是智联网。
如果说互联网是二维信息的联通、物联网是三维空间的联结,那么智联网则是进入更高维度的智能体互联。
而在智联网中,AI智能体应当是最为关键的存在,它可以是拟人的原生智能体,也可以是现实中的人和物体的数字孪生智能体。
通过智能体的连接,可以让AI真正为人类服务,提供价值(生产力的提升、交互方式的改变)。
以一个大胆的想象来比喻,可能在智联网的将来,家中的哪怕是一张桌子、一台冰箱,也会具备智能体的特性,可以与人和其它物体做智能交互。

而这,也正是面壁智能愿景的由来——智周万物:
不过有一说一,智联网的理想虽好,但现实的情况是,即使是ChatDev和第三代大模型的发布,也只能视为迈向愿景的一步。
那么面壁智能是否有足够的实力能够在将来解锁“智周万物”呢?
关于面壁智能对于这个问题,我们首先就要看一下面壁智能的团队实力如何。
从官方披露的消息可知,面壁智能成立于2022年8月,CEO为李大海,首席科学家是刘知远。
二人的学术、技术实力已然是不容小觑。
李大海毕业于北大数学系,后加入谷歌成为Google中国创始员工之一;再后来也有在众多知名企业担任技术负责人、CTO等职务的经历,对技术体系的搭建和商业化落地有着丰富的经验。
刘知远是清华大学计算机系长聘副教授,主要研究方向为自然语言处理、知识图谱和社会计算。在人工智能领域著名国际期刊和会议发表相关论文200余篇,Google Scholar统计引用超过3.7万次,学术造诣可谓是十分深厚。
不仅如此,官方展示的“顾问”成员也是非常重量级,包括两位清华大学计算机系教授——孙茂松和刘洋。
不难看出,面壁智能是妥妥一家“清华味”十足的大模型初创企业。
除此之外,其在产学研生态道路上也有自己独特的打法,即“一体两翼”。
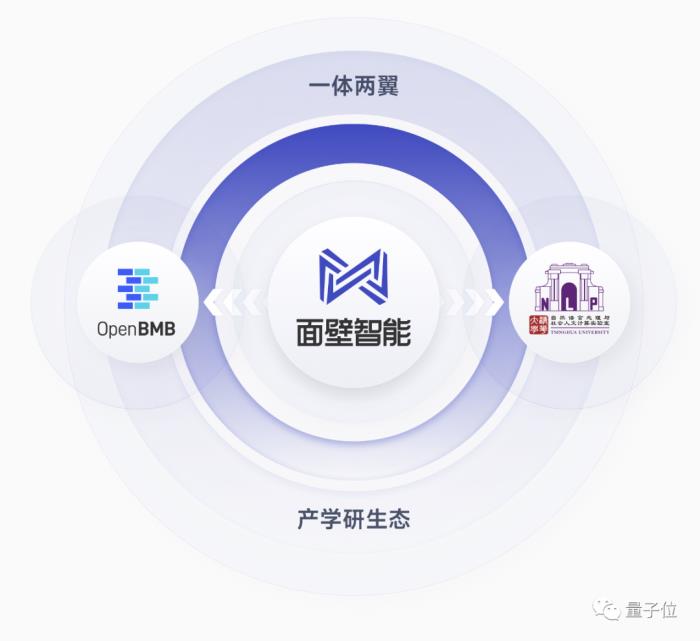
“一体”指的正是面壁智能,而“两翼”则是OpenBMB和清华NLP实验室。
据了解,OpenBMB是面壁智能团队在2021年与清华NLP实验室共同成立的国内领先大模型研发与应用开源社区,社区宗旨为“让大模型飞入千家万户”。
目前除了Agent技术框架,OpenBMB还开源了CPM-Ant、CPM-Bee 10B基础模型,BMTrain、BMCook、 BMInf 、OpenPrompt、OpenDelta等大模型全流程加速工具包,为中国大模型开源事业做出了独树一帜的贡献。
清华NLP实验室,则是国内最早系统开展深度学习与大模型研究的单位,团队在国际顶级学术会议和国际权威期刊发表论文200余篇,引用近44000次,并获得多项最佳论文奖。
由此可见,无论是自身实力,亦或是“一体两翼”式的强强联手,面壁智能在技术这一块可以说是妥妥拿捏住了。
这也就不难理解,为何仅成立一年的面壁智能,便可将CPM大模型迭代三代,又能在国内率先亮出“大模型+Agent”群体智能模式的产品应用了。
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。