新火种
2023-11-13
新火种
2023-11-13 


AI教程系列--聊天机器人的强化学习部署
朱洪银的快速会议。
今天我们来讲一个知识点。这个知识点是关于大语言模型,聊天机器人的法强化学习与人类对齐的技术。我们今天主要来讲怎么样使用现有的工具来强化与人类的价值观对齐。这个是什么意思呢?对于专家、专业人士来讲明白什么意思。
对于小白来讲也就是大语言模型在执行任务的对话机器人在聊天的时候需要跟人类的观念对齐,不要产生一些有害的言论,道德观念各方面要跟人类对齐,就需要具备这么个技术对吧?这一节要专注一点,主要是讲工程实现,而且主要是告诉你能怎么用起来就行了。理论方面是想到哪讲到哪。

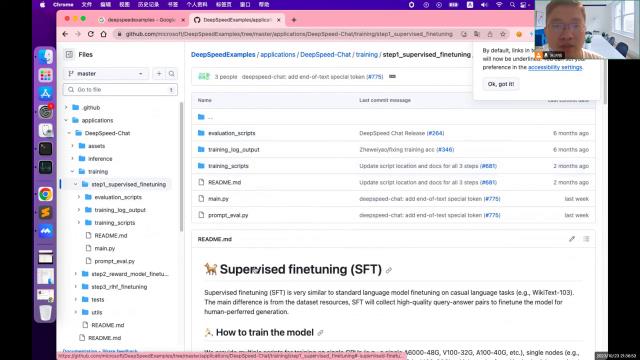
以后如果有机会的话再讲。先登录网址,这个网址是开源的、对桥、人类反馈学习机制的复线视力,然后找到这个网址,这个网址注意一下。找到之后点文件夹、application,找到这个deep speedchat,找到这年间。
下面是功能的说明书,下面还会附上一个对于它的使用方法。然后这里就教这里提供一套程序,可以让我们训练一套属于自己的自己训练的价值观对齐的模型,聊天机器人模型。这个模型主要是分为,怎么训练呢?就刚才说的说明文档里面有,每一步应该怎么执行、应该怎么去执行都写了。
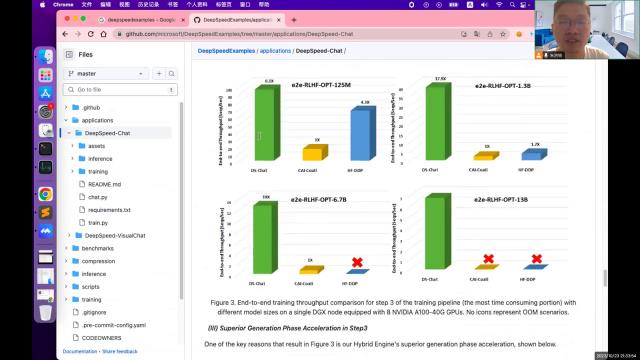
简单说一下这个过程一共分为三步,第一步叫super rise的 fan tuning是有监督的,微调。也就是在大模型的基础上把大模型用的问答问答数据机对训练一下,相当于让它懂得。别人说是什么意思?你问的事是什么意思呢?你有什么诉求。
第一步训练完了之后第二步是reward、model,这个是奖励模型微调,要训练一个训练一个像人一样的标注员,第二步的目的是训练一个标注员。这个标注语言训练完了之后第一步训练的模型可以回答问题了,第二步的训练标注语言模型可以判断,在第一步模型回答的问题好还是不好,给他一个反馈,这个事情就不用人去干了,就交给第二步的模型去干。就这么意思。
第三步把刚才说的事把第一步的问答机器和第二步的标注语言模型结合起来,就实现了人类反馈的机制,本来人类反馈应该是人类去给模型评判回答的好还是不好,对吧?人类反馈,现在要追求的是自动化,所以就让这个标志员来干这件事了。过程这样整个过程就是这样了,至于你怎么运行,比如说这个,这里给了三个三个这个视力,你可以去文件夹下找到这个视力,这个一步都有一个视力,比如说我举例子。
·比如说第一步,这里有一个trainingscript,下面也写了,下面也写了是吧?署名。这个第一步就运行这个脚本,你就找到这个文件,你们一会就知道是啥了。
·第二步也写了,我给你提供了一个让你运行哪一个?第三步他也写了也会让你提供了一个让你运行哪一个?都一样。
·然后整个三步,一步两步三步,全部运运下来就得到了一个经过微调之后的对话机器人了,就是一个微调周的对话机器人。
·后面可能再会再讲一讲如何用自己的数据去微调一个真正属于你的能够帮你干事情的事情,因为这里面包含的知识太多了,还是这里面包含的知识面太广,每一个视频里面只能整一小块。
·再回到上一层chat,我记得这里有一个,这里有一个执行一次就能够把后面的step一二三全部都执行完,就不用一步的自己去执行体验体验,你也可以只执行,一个命令就能把后面的全部执行完。看看是哪一个,记得这里是有一个命令行的。
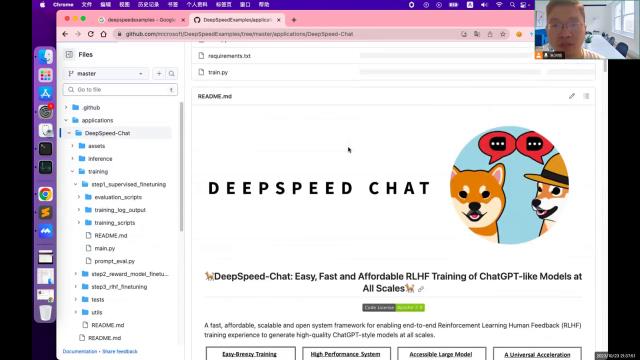
·可能串串点拍看看,就是这个,春天派这个文件这里写了,怎么去执行他?就能够把后面这三个文件就不用你一步一步的执行了,只一个就可以那样的效果就可以完成这个过程,只要掌握了这个就可以训练自己的对话机器人了。
·如果只训练了第一步,可以训练一个针对特定领域的回答机器人,我现在先不管这个道德,还有各方面的价值是不是跟人类对齐了?我不管,只是想让他来帮干点事的吧?让他训练一个某一个领域的解决某一类问题的,这个问答机器人就可以了,就已经得到了已经ok了。如果我没有太高的这种全方位的评判标准已经ok了,能帮我干这活就行。
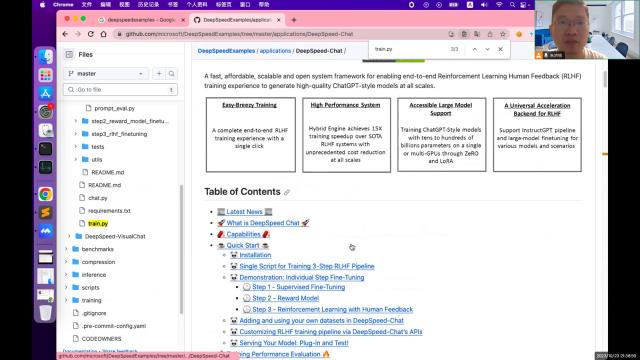
·如果你有更高的要求你有工作要求,就需要训练一个与人类的价值对齐的机器人。那就需要把后边那两步也执行完,进一步的训练。周围出来之后就既实现了你的功能,又能够跟人类的价值对齐,就完美了,对吧?总而言之掌握了这个就基本上可以获得一个拆的dvt了,当然人家拆的dvt是用大量非常高质量的数据,AI教程系列--聊天机器人的强化学习部署。
一般人可能没有那么多高质量数据,所以训练出来效果因人而异,就因人而异。因为这个数据还是占据了一个非常重要的地位的。这节课讲完了。
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。