

 新火种
2023-11-03
新火种
2023-11-03 


机器学习完全指南:如何用Python生成合成数据集?
编者按:机器学习在越来越多的领域中凸显出其不可替代的重要性,人们开始从各领域渗透机器学习的典型案例,希望其大规模投入使用,而数据集对机器学习的效果起了决定性作用。这篇文章,原标题是How to Make Synthetic Datasets with Python: A Complete Guide for Machine Learning,作者Dario Radečić在文中主要介绍了如何用Python生成合成数据集,希望对你有所帮助。
推荐阅读:2021 年你应该学会的 5 个 Python 小技巧

图片来源:Pexels.com @Christina Morillo
我们总是很难找到好的数据集。有时候,你可能只想提出一个观点。在这些情况下,繁琐的加载和准备工作则会显得有点多。
在这篇文章中,我将跟大家分享如何用Python和Scikit-Learn(一个非常好的机器学习库)生成合成数据集。此外,你还将了解如何处理噪声,类别平衡和类分离等内容。
懒人目录
生成你的第一个合成数据集
添加噪声
调整类别平衡
调整类分离
生成你的第一个合成数据集对于概念和想法展示而言,现实世界中的数据集总是盈千累万。
假设你想要直观地解释SMOTE算法(一种处理类别平衡的技术)。首先,你必须找到一个类别不平衡的数据集,并且把它映射到二维或三维空间上,以便于可视化工作。
当然,还有更好的解决方案。
Scikit-Learn库附带了一个方便的make_classification()函数。虽然这个函数不是唯一一个生成合成数据集的函数,但你在如今必然会频繁地使用它。
这个函数接受各种参数,可以让你控制数据集的具体信息,下文中会进一步介绍。
首先,你需要导入所需的库。你可以参考以下代码段:
import numpy as npimport pandas as pdfrom sklearn.datasets import make_classificationimport matplotlib.pyplot as pltfrom matplotlib import rcParamsrcParams['axes.spines.top'] = FalsercParams['axes.spines.right'] = False
你将开始生成自己的第一个数据集。
这个数据集有1000个样本,这些样本被分为0和1两类,为了确保样本类别平衡,每一类的占比都是50%。
每个类别的所有样本都以一个单独的簇为中心。为了提高可视化效果,该数据集只有两个特征:
X, y = make_classification( n_samples=1000, n_features=2, n_redundant=0, n_clusters_per_class=1, random_state=42)df = pd.concat([pd.DataFrame(X), pd.Series(y)], axis=1)df.columns = ['x1', 'x2', 'y']# 5 random rowsdf.sample(5)
调用sample()函数可以列出五个随机的数据点:
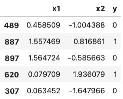
图片来源:Dario Radečić
这五个随机数据点还无法提供数据集背后的完整信息。该数据集是二维的,所以你可以声明一个用于数据可视化的函数。比如,你可以声明这样一个函数:
def plot(df: pd.DataFrame, x1: str, x2: str, y: str, title: str = '', save: bool = False, figname='figure.png'): plt.figure(figsize=(14, 7)) plt.scatter(x=df[df[y] == 0][x1], y=df[df[y] == 0][x2], label='y = 0') plt.scatter(x=df[df[y] == 1][x1], y=df[df[y] == 1][x2], label='y = 1') plt.title(title, fontsize=20) plt.legend() if save: plt.savefig(figname, dpi=300, bbox_inches='tight', pad_inches=0) plt.show()plot(df=df, x1='x1', x2='x2', y='y', title='Dataset with 2 classes')
这是该数据集可视化之后的效果:
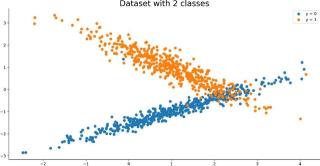
图2:合成数据集的可视化效果。图片来源:Dario Radečić
整个过程十分迅速!你现在拥有一个简单的能够自行处理的合成数据集。接下来,你将学习如何添加一些噪声。
添加噪声你可以使用make_classification()函数的flip_y参数来添加噪声。
这个参数代表y(每一个样本中的类成员的整数标签)噪声值的比重。更大的值可以将噪声引入到标签中,并且使得分类任务更加困难。
值得注意的是,在某些情况下,默认设置flip_y > 0可能会导致y中缺少n_classes(类别数量)。
下面是使用该参数处理我们的数据集,为其添加噪声的演示:
X, y = make_classification( n_samples=1000, n_features=2, n_redundant=0, n_clusters_per_class=1, flip_y=0.15, random_state=42)df = pd.concat([pd.DataFrame(X), pd.Series(y)], axis=1)df.columns = ['x1', 'x2', 'y']plot(df=df, x1='x1', x2='x2', y='y', title='Dataset with 2 classes - Added noise')
下图是对应的可视化效果。
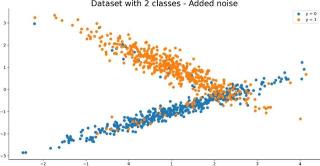
图3:在合成数据中添加噪声的可视化效果。图片来源:Dario Radečić
你能看见蓝色簇中有更多的橘色点,反之亦如此,至少和图2比较时,这个发现是成立的。
以上就是添加噪声的方式与过程。接下来我们将讲解类别平衡。
调整类别平衡在现实世界的数据集中,我们总能看到类别不平衡的情况。一些数据集甚至存在极大的类别不平衡问题。例如,1000笔银行交易中,可能有一笔交易是诈骗交易,这就意味着其平衡比例为1:1000。
你可以使用weights参数来控制类别平衡。它是一个有N-1个值的列表,其中N是特征数。我们之前设置的特征数为2,所以列表中只有一个值。
现在让我们来看看如果将值指定为0.95,会出现什么结果:
X, y = make_classification( n_samples=1000, n_features=2, n_redundant=0, n_clusters_per_class=1, weights=[0.95], random_state=42)df = pd.concat([pd.DataFrame(X), pd.Series(y)], axis=1)df.columns = ['x1', 'x2', 'y']plot(df=df, x1='x1', x2='x2', y='y', title='Dataset with 2 classes - Class imbalance (y = 1)')
下图就是数据集可视化效果:
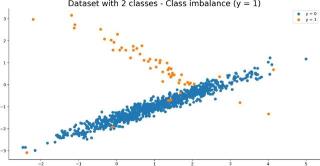
图4:在正类上类别不平衡的合成数据集可视化效果。图片来源:Dario Radečić
如图所示,数据集中只有5%的部分属于类1,你也可以将这一个分类比例轻松地转换。比如说,如果你将数据集中类0的占比改为5%:
X, y = make_classification( n_samples=1000, n_features=2, n_redundant=0, n_clusters_per_class=1, weights=[0.05], random_state=42)df = pd.concat([pd.DataFrame(X), pd.Series(y)], axis=1)df.columns = ['x1', 'x2', 'y']plot(df=df, x1='x1', x2='x2', y='y', title='Dataset with 2 classes - Class imbalance (y = 0)')
下图就是对应的可视化效果:
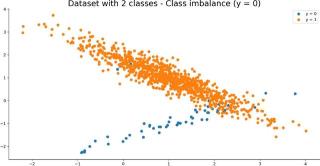
图5:在负类上类别不平衡的合成数据集可视化效果。图片来源:Dario Radečić
这就是关于类别平衡的全部信息。最后,我们再看看调整类分离。
调整类分离默认状态下,类0和类1中总会有一些重叠的数据点。对此,你可以使用class_sep参数来控制类分离的情况。Class_sep的默认值是1.
如果你将该值设为5,我们看看会出现什么结果:
X, y = make_classification( n_samples=1000, n_features=2, n_redundant=0, n_clusters_per_class=1, class_sep=5, random_state=42)df = pd.concat([pd.DataFrame(X), pd.Series(y)], axis=1)df.columns = ['x1', 'x2', 'y']plot(df=df, x1='x1', x2='x2', y='y', title='Dataset with 2 classes - Make classification easier')
下图就是数据集的可视化效果:
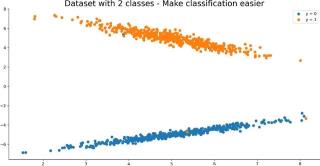
图6:明显的类分离合成数据集可视化效果。图片来源:Dario Radečić
如图所示,类分离的情况非常明显。将class_sep的值设置得越高,类分离效果就越好,反之亦然。
写在最后在这篇文章中,我跟大家分享了如何用Python和Scikit-Learn生成基本的合成分类数据集。
你可以在想要证明一个观点,或是实现一些数据科学概念的时候来使用它们。然而,在这种情况下,不建议使用真实的数据集,因为它们往往需要缜密的准备工作。
译者:俊一
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。









