

 新火种
2023-11-01
新火种
2023-11-01 


AI能读懂40种语言,15个语种拿22项第一,背后是中国团队22年坚守
编辑:好困 桃子
【新智元导读】怎样才叫打破语言界的天花板?一次拿下15个语种22项第一,还让机器读懂40多种语言。能够在多语种语音语言领域制霸的背后是中国团队22年对顶天立地这一理念的坚守。一次拿下15个语种22项第一!
不,还有更厉害的:40多种语言全能读懂,简直打破语言界的天花板。
2次获奖,科大讯飞在多语种方向上取得了大满贯成绩。

先是在世界权威多语言理解评测XTREME中,哈工大讯飞联合实验室(HFL)团队以总平均分84.1分位列榜首,刷新世界纪录。
后是在国际低资源多语种语音识别竞赛OpenASR中,科大讯飞-中科大联合团队参加了所有15个语种受限赛道和7个语种非受限赛道,全部拿下了第一。
这一切得益于讯飞背后深深扎根的技术,还有其始终如一坚持顶天立地的初心,才能让讯飞在多语种语音语言领域制霸。
第一的背后那么,现在机器的多语种理解能做到什么程度了?
就比如下面这段夹杂着英语、德语、西班牙语的句子吧。
The heat required for boiling the water and supplying the steam can be derived from various sources, most commonly from burning combustible materials with an appropriate supply of air in a closed space (called variously combustion chamber, firebox). In manchen Fllen ist die Wrmequelle ein Atomreaktor, Erdwrme, Solarenergie oder Abwrme von einem Verbrennungsmotor oder einem Industrieprozess. En el caso de modelos o motores de vapor de juguete, la fuente de calor puede ser un calentador eléctrico.
翻译过来就是:
让水沸腾以提供蒸汽所需热量有多种来源,最常见的是在封闭空间(别称有 燃烧室 、火箱)中供应适量空气来燃烧可燃材料 。在某些情况下,热源是核反应堆、地热能、 太阳能或来自内燃机或工业过程的废气。如果是模型或玩具蒸汽发动机,还可以将电加热元件作为热源。
说到多语种的自然语言理解,谷歌举办的XTREME(Cross-Lingual Transfer Evaluation of Multilingual Encoders)评测可谓是十分具有代表性的。

/uploads/pic/20231101/pp.pdf data-track="32">与以往单语言自然语言理解评测任务不同的是,XTREME中的每一个任务都覆盖了多种语言,其中许多都缺乏相关研究,如达罗毗荼语系的泰米尔语、泰卢固语系和马拉雅拉姆语,以及非洲的尼日尔-刚果语系的斯瓦希里语和约鲁巴语。
而评测的成绩则是模型在多种语言上的理解能力平均指标,因此对系统模型的多语言理解与跨语言迁移能力要求大大提高。
具体而言,XTREME涵盖了12个语系的40种语言,包括对不同层次的语法或语义进行推理的4大类9个任务:
句对分类:XNLI、PAWS-X(自然语言推断)序列标注:UDPOS(词性标注)、PANX (命名实体识别)阅读理解:XQuAD、MLQA、TyDiQA(片段抽取型阅读理解)句子检索:BUCC、Tatoeba(跨语言文本检索)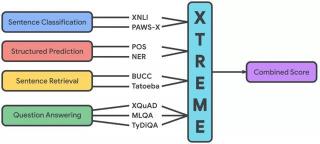
今年9月,微软凭借最新的图灵通用语言表示模型(T-ULRv5),成功刷新了XTREME榜单总分和4个单项任务的SOTA。
为了达到这一最新成就,微软在大规模的多语言数据集上对模型进行了平行文本语料的训练,并同时结合了最新的XLM-E研究和XTune微调技术。
由此诞生的T-ULRv5 XL有48个transformer层,隐藏维度大小为1536,24个注意力头,多语言词汇量为50万个,总参数量达到22亿,并且能够处理94种不同的语言。
不过,在上个月的最新排名中,哈工大讯飞联合实验室(HFL)团队以总平均分84.1分的成绩再次刷新了这个记录。
HFL的CoFe模型在四项任务中,有三项都超过了微软T-ULRv5 XL模型创造的记录,另外一项则与其持平。

对此,哈工大讯飞联合实验室提出了三项技术,从而让模型具有多语言理解与跨语言迁移能力。
第一,加入了自主研发的跨语言对比学习技术,鼓励模型学习不同语言中的语义相似性。
CoFe利用多语言的同义句对作为正样本,易混淆与反义句对作为高难度负样本,以对比学习和分类任务为训练目标,让模型比较与学习不同语言文本背后的语义。
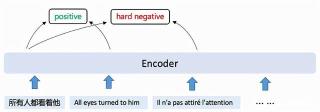
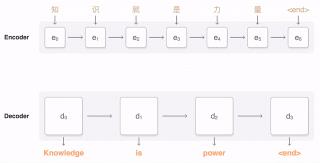
在上图的例子中,对于源语言(中文)中的句子A「所有人都看着他」,以英文中的同义句B「All eyes turned to him」为正样本,法语中的反义句C「Il n'a pas attiré l'attention」为高难度负样本,其他句子作为普通负样本训练模型,达到让模型习得跨语言理解句子语义的目的。
第二,利用知识蒸馏技术进行自监督学习和知识迁移,进一步提升了模型在各个语言上效果的稳定性。
知识蒸馏技术除了可以用于模型压缩与加速,对提升模型的性能与稳定性也有很大帮助。因此,CoFe从多个角度对其进行了开发利用:
通过自监督训练,让模型自我蒸馏,提升稳定性;多语-单语的多到一知识迁移。所谓三人行必有我师,让多语言学生模型从多个单语言教师模型学习知识,博采众长;多语言多模型蒸馏。将多个多语言教师蒸馏至单一模型,从而提供更优的教师指导信号。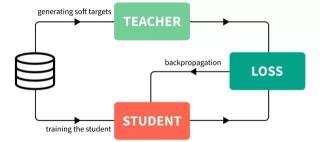
第三,融入细粒度的语言学特征,帮助模型克服训练不足的困难,解决低资源语言学习不充分的问题,同时使之适应不同语言的形态学特点。
例如对于一些书写系统比较特殊的低资源语言,CoFe中引入了额外的分词系统,以帮助模型在少量数据精调下更迅速地掌握理解该语言的能力。
从而让机器可以在少量其他语言语料的情况下,通过「类比」学会这门语言,减少了收集语料、语音标注等大量工作。
在另一个更加关注小语种语音技术的OpenASR比赛中,科大讯飞-中科大语音及语言信息处理国家工程实验室(USTC-NELSLIP)联合团队参加了所有15个语种受限赛道和7个语种非受限赛道,并全部取得第一名的成绩。

小语种语音数据难以获取不仅表现在语音的数据量上,更表现在语料丰富性,发音词典大小以及标注准确度上。对于许多低资源语种,姑且不说上万小时语音数据,就连100小时标注数据的获取也举步维艰。
为此,世界语音学术领域的权威组织美国国家标准与技术研究院NIST(National Institute of Standards and Technology)在2020年底,举办了OpenASR (Open Automatic Speech Recognition) 比赛。
今年更是将语言增加到了15个语种,涵盖受限赛道(Constrained condition)、受限附加赛道(Constrained Plus)和非受限赛道(Unconstrained Condition)。
此外,比赛中各个语种数据主要来自电话信道,口语化特征十分明显,对话风格非常自由,也使得语音识别难上加难。
团队在比赛中提出了基于语音和文本统一空间表达的半监督语音识别框架(Unified Spatial Representation Semi-supervised ASR,USRS-ASR),获此佳绩也验证了该算法良好的推广性。

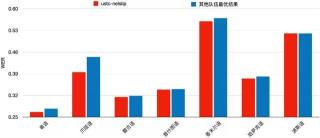
受限赛道15个语种的成绩
在受限赛道上,由于每个语种只有10小时语音数据,如何使用少量文本数据,利用无监督的方法增加语音训练数据的多样性至关重要。
团队运用Flow-TTS语音合成进行训练数据扩增,并使用语音属性解耦技术保证合成语音的多样性。
结果显示,使用上述无监督数据扩增方案,能够稳定、显著地提升低资源语音识别任务的效果。
非受限赛道7个语种的成绩
而在非受限赛道上,虽然可以利用公开的语音数据,但数据总量仍只有数百小时,而且语音数据和文本数据的量级差距十分明显,这对于端到端识别框架来说,弊端更为明显。
为了在端到端统一框架下,充分使用少量语音数据和海量文本数据,团队提出了基于语音和文本统一空间表达的半监督语音识别框架USRS-ASR:
文本掩码语言模型任务、合成数据语音识别两个目标,两个任务联合训练以充分利用海量无监督文本;共享语言解码模块,实现了语音和文本隐层表达空间的统一,大大缓解了低资源语种的数据稀疏问题。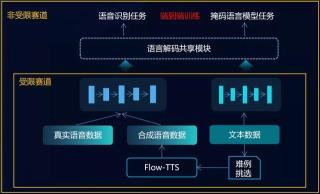 顶天立地,22年坚守
顶天立地,22年坚守让机器能听会说,能理解会思考的这条路上,科大讯飞一直攀登22年之久。
一次拿下15个语种22项第一,让机器可以读懂40种语言等重大成果,都体现了讯飞在人工智能领域一直有着顶天立地的追求和坚守。
那么,科大讯飞为什么担起这个角色?
人工智能的发展不在仅限于如何让AI的一项技能训练到炉火纯青的境界,而在于如何让其更智能,也就是能够抵达通用人工智能。

而当前,人机交互是大势所趋。万物互联,语音便成为人机交互关键入口,包括语音输入、语音搜索、语音交互等技术已经成为手机、车载、玩具等智能产品的标配。
据统计,2020年即便在疫情情况下,我国电子及汽车类出口总额也超过了3000亿美元,这些出口的智能设备对多语种技术有着强烈的需求。
此外,「一带一路」的建设依赖语言互通,多语种翻译技术价值凸显。
近年来,多语种语音语言技术涉及国家安全信心等重大方向,成为Nuance、谷歌等科技巨头竞相布局的关键技术方向。
再加上国际形势不确定,技术竞争十分激烈,因此亟待解决国内自主研发问题,打破多语种技术被卡脖子问题。
在这样背景下,科大讯飞担起了这个重任,在大规模多语种语音语言技术的研发上投入大量精力,期望能够破解多语种技术难题。
近一年来,讯飞在重点语种上进行不断的迭代演进,并在语音识别,语音合成,图文识别,机器翻译这些方面取得了一系列新的进展。
比如,24个语种的合成自然度MOS分超过4.0,35个语种听写场景语音识别正确率超过90%,18个语种文档拍照场景正确率大于90%,36个语种口语场景人工分忠实度大于4.0。
领先的多语种语音语言技术有力支撑了科大讯飞智能硬件产品创新及应用。
就拿多语种翻译来说,2016年发布的讯飞翻译机开创了AI翻译机新品类,先后推出了4代,覆盖全球近200个国家和地区,2019年提供的翻译服务超过5亿人次。
今年5月份又发布了双屏翻译机,可以做到精准实时的翻译,而且有很多语种选择。
它光是中外互译就多达60种,还有5种中文方言与英语互译,2种难懂的民族语言(藏语和维吾尔语)也能与普通话互译。

用户可以一边说另一边就能翻译,只需按下时说话,松开即可翻译,能做到0.5秒疾速响应。
此外,讯飞的智能录音笔,也可以支持10个语种的语音转写和分离。
就拿SR302来说,不仅支持粤语、重庆话、贵州话等12种方言转写,同时还可进行英语、日语、法语等10大语种的转写。

在多语种语言服务方面,讯飞听见同传系统已经能够支持9个语种的实时转写和翻译字幕上屏。
前段时间,在中国驻欧盟使团与欧盟农业总司共同举办中欧地理标志产品推广视频交流会上,讯飞听见同传全程提供转写技术服务,展现了其不俗实力。
目前,科大讯飞在多语种技术及应用,也获得国家领导和社会业界的广泛认可。
并成为北京2022年冬奥会和冬残奥会官方自动语音转换与翻译独家供应商,助力打造人类历史上首个信息沟通无障碍的奥运会。
一路走来,正是对源头技术的不懈攻坚,让讯飞在语音合成、语音识别、机器阅读理解等多项国际核心技术赛事上获得冠军,并树立了人工智能发展史上的多个里程碑。
正如科大讯飞董事长刘庆峰所说,人工智能发展要顶天立地。
现在,讯飞不断践行这一「顶天立地」理念,未来还有很长的路要走,还有更高的山峰等着攀登。
参考资料:
/uploads/pic/20231101/pgv_ref=apub style="text-align: left" data-track="189">https://www.microsoft.com/en-us/research/blog/microsoft-turing-universal-language-representation-model-t-ulrv5-tops-xtreme-leaderboard-and-trains-100x-faster/?mc_cid=3d43a11ddd
https://sites.research.google/xtreme
相关推荐


- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。









